

React Design Editor 图像/视频在线编辑器;2022阿里天池冠军方案[1/1149];计算机优秀课程大集锦;贝叶斯统计课程资料;前沿论文 | ShowMeAI资讯日报
[开源版Canva]图像/视频在线编辑器、网页版音频编辑器、3D被动人脸活体检测(反欺诈)、petals 运行100B+参数语言模型的去中心化平台、DocQuery [开源]询问文档相关问题、2022阿里天池『真实场景篡改图像检测挑战赛』冠军方案、计算机优秀课程集锦、贝叶斯统计课程资料、图像补全资料列表、前沿论文…点击获取全部资讯

工具&框架
🚧 『React Design Editor』开源版 Canva,图像/视频在线编辑器
https://github.com/layerhub-io/react-design-editor
Design Editor 是 Canva 的完美替代应用,是图片、演示文稿和视频的编辑器。Design Editor 使用了 fabric.js 的 React 设计,你也可以在线访问上方第二个链接,了解更多与交互操作。
🚧 『Wavvy Audio Editor』开源网页版音频编辑器
https://github.com/ahilss/wavacity
Wavvy Audio Editor 是一个免费开源的网页版音频编辑器,支持对音频进行高效全面的编辑,操作简单。
🚧 『FaceLivenessDiscovery-SDK』3D 被动人脸活体检测(反欺诈)与Deepfake 换脸检测
https://github.com/DoubangoTelecom/FaceLivenessDetection-SDK
https://www.doubango.org/webapps/face-liveness/
FaceLivenessDiscovery-SDK 是 3D 人脸有效性检测(反欺骗)和深度伪造检测工具。只需要一张图片就可以计算出活性得分。在作者数据集上有 99.67% 的准确率,在多个公共数据集(NUAA, CASIA FASD, MSU…)上均有非常好的表现。

🚧 『petals』无需高端GPU、用于运行100B+参数语言模型的去中心化平台
https://github.com/bigscience-workshop/petals
petals 是一个运行极大型(100B以上)语言模型的去中心化平台,通过与互联网上的人联合计算资源,运行推理或微调大型语言模型,如 BLOOM-176B。不需要拥有高端 GPU。
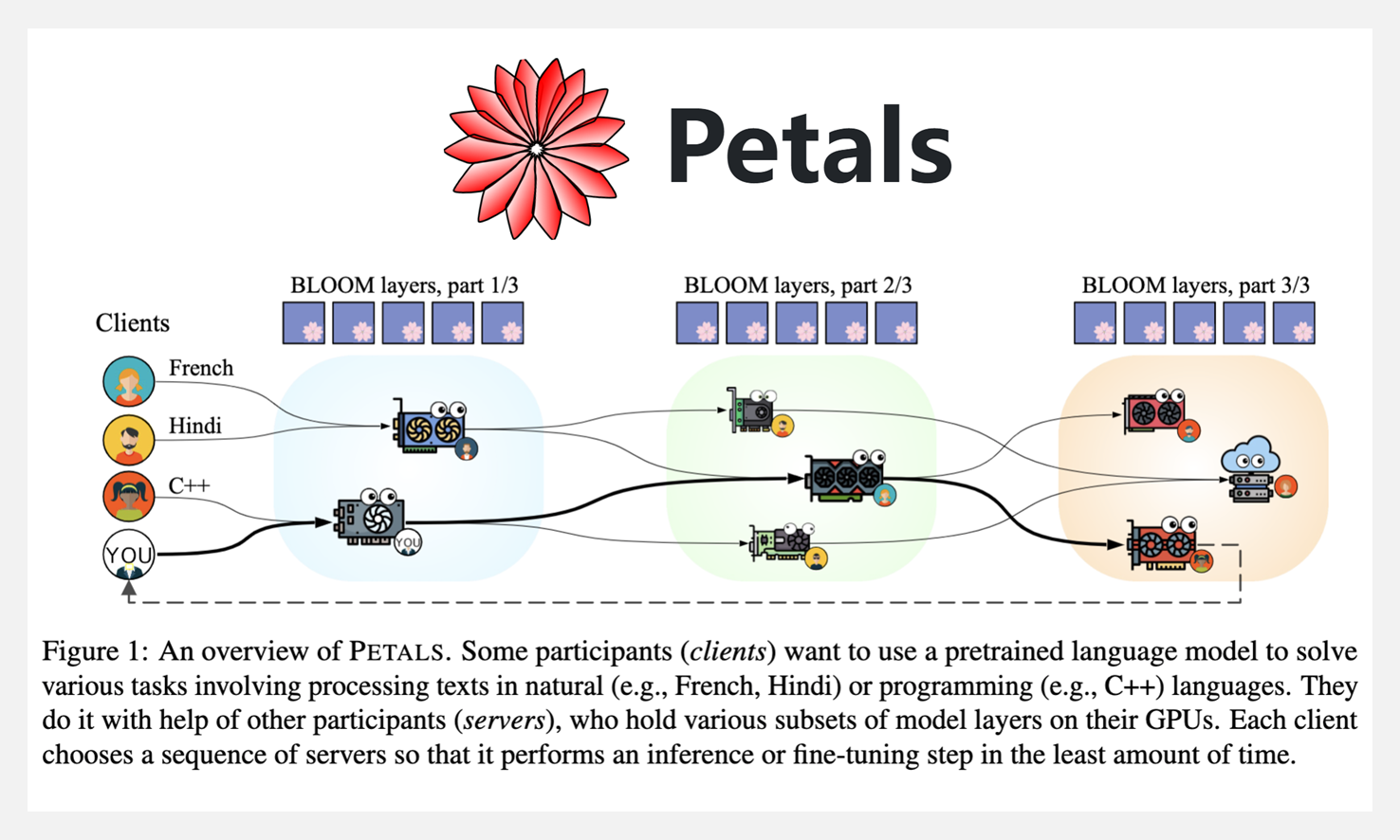
Petals允许加载和服务于模型的一小部分,然后与服务于所有其他部分的人合作,运行推理或微调。除了传统的语言模型 API——工具还可以通过执行模型的自定义路径或访问其隐藏状态来采用任何微调和采样方法。这使得 API 的舒适性和 PyTorch 的灵活性得以实现。
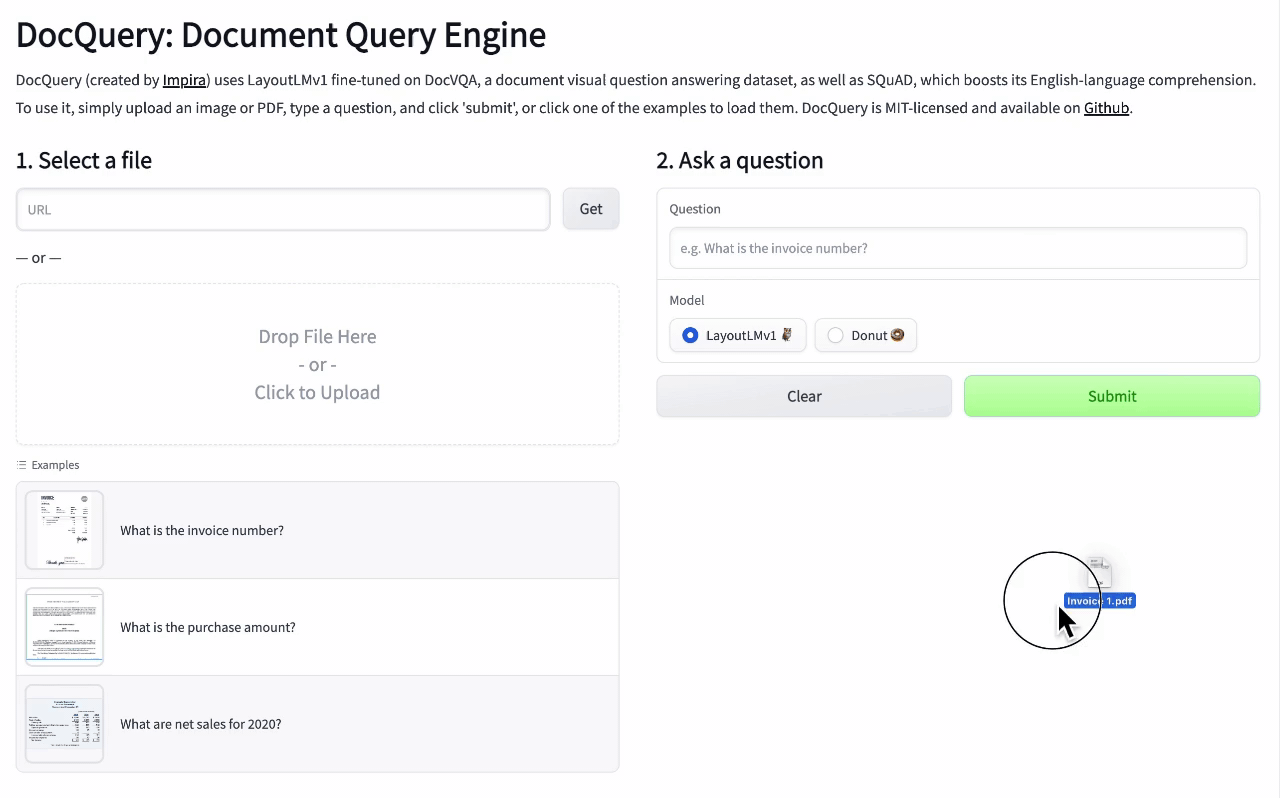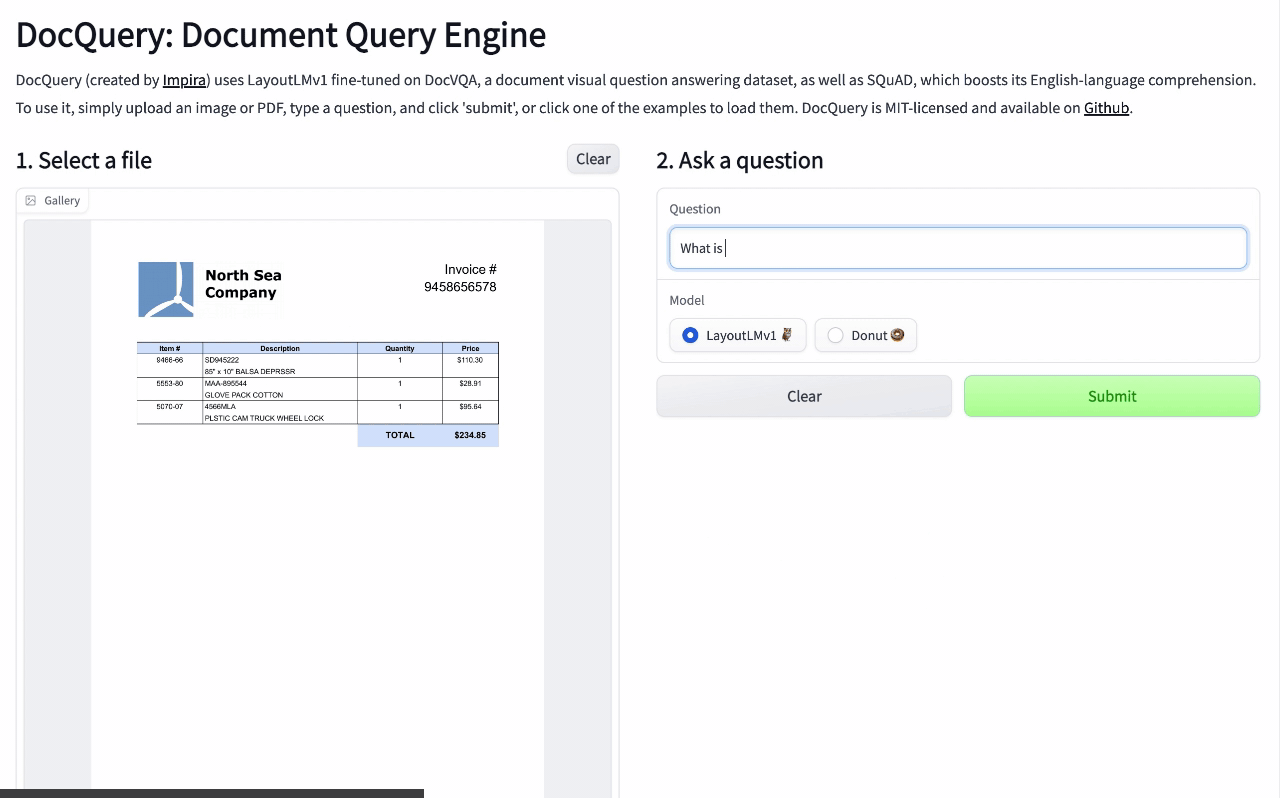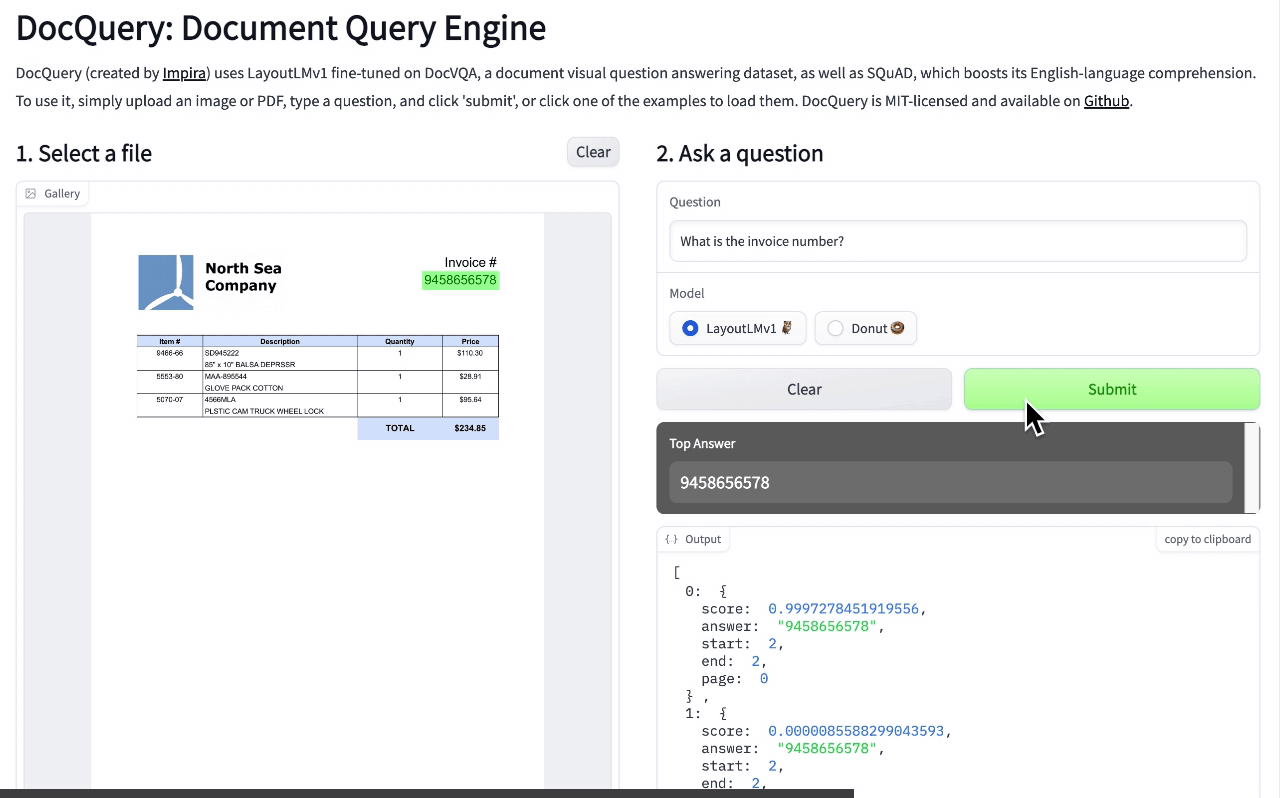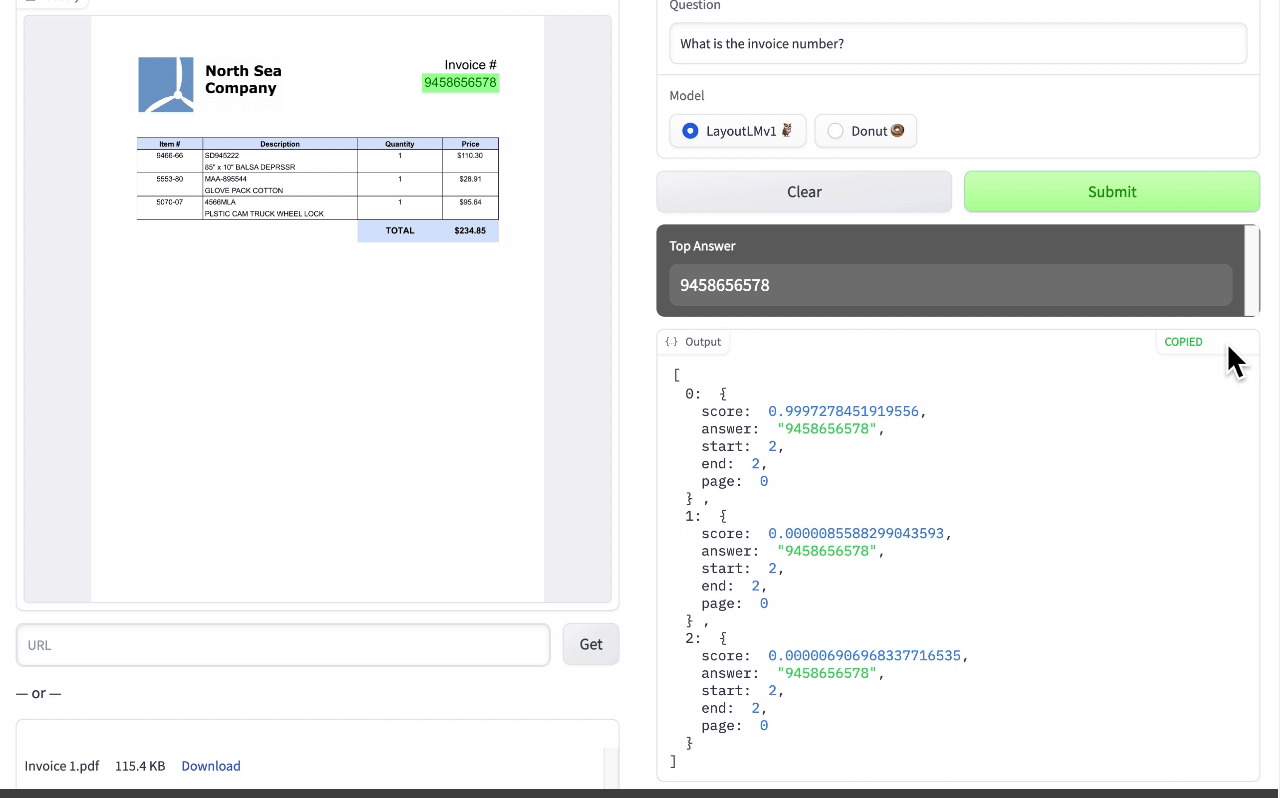
🚧 『DocQuery』可供询问文档相关问题的开源工具
https://github.com/impira/docquery
https://www.impira.com/blog/hey-machine-whats-my-invoice-total
DocQuery 是一个库和命令行工具,它应用先进的自然语言处理(NLP)来分析半结构化和非结构化的文件(PDF、扫描图像等)。

你只需将 DocQuery 指向对应的一个或多个文件,并指定想查询的问题即可。DocQuery 由 Impira 的团队创建。
项目&代码
🎯 2022阿里天池『真实场景篡改图像检测挑战赛』冠军方案(1/1149)
https://github.com/Junjue-Wang/Rank1-Ali-Tianchi-Real-World-Image-Forgery-Localization-Challenge
https://tianchi.aliyun.com/competition/entrance/531945/introduction
阿里天池举办一个针对真实场景中大量出现的篡改图像的检测比赛,提供一个接近真实经济生活场景的篡改图像数据集,让篡改检测领域更加关注此类高风险篡改图像,通过比赛促进此方向的技术进步。

Repo是排行榜第一名『审稿人手下留情』团队公开的解决方案,基于篡改任务中存在的『正负样本不均衡,模型优化困难』『正负样本视觉差异小,判别特征微弱』『训练集数据量小,泛化性弱』三个挑战,设计以下思路:
- 针对数据集正负样本不均衡问题,采用 lovasz-loss,自动平衡训练过程中样本权重,保证对每张图片的正样本都有足够的学习能力。
- 针对正负样本视觉差异小,判别特征微弱问题,采用大尺度输入与大尺度放缩数据增强策略,从微观和宏观层面分别增强特征差异。
- 针对训练集数据量小,泛化性弱问题,引入三种来源不同的数据集。

博文&分享
👍 『CS Awesome Courses』计算机优秀课程集锦
https://github.com/jackwener/CS-Awesome-Courses
课程集锦包含以下几个大类:
- Artificial Intelligence / 人工智能
- Operating System / 操作系统
- Programming Language / 编程语言
- Compliers / 编译器
- Database System / 数据库系统
- Distributed System / 分布式系统
- Data Structures and Algorithms / 数据结构与算法
- Computer Networking / 计算机网络
- Computer Architecture / 计算机体系结构
👍 『Bayesian Statistics』贝叶斯统计课程资料
https://github.com/storopoli/Bayesian-Statistics
https://github.com/storopoli/Bayesian-Statistics/blob/main/slides/slides.pdf
这是一份超酷的『贝叶斯』教程,包含完整的幻灯片、数据集和代码!作者中二之魂熊熊燃烧,手指天空喊出『Bayesian for Everyone! (适合所有人的贝叶斯!)』的口号~
贝叶斯统计是统计领域的一种理论。与许多其他对概率的解释不同,贝叶斯统计方法使用贝叶斯定理在获得新数据后计算和更新概率。作者这份教程兼顾了数学的严谨性、展示的直观性,将枯燥深沉的数学理论,展示得明白清晰。主要内容如下:
- What is Bayesian Statistics? / 何为贝叶斯统计
- Common Probability Distributions / 常见概率分布
- Priors / 先验
- Predictive Checks / 预测检查
- Bayesian Linear Regression / 贝叶斯线性回归
- Bayesian Logistic Regression / 贝叶斯逻辑回归
- Bayesian Ordinal Regression / 贝叶斯有序回归
- Bayesian Regression with Count Data: Poisson Regression / 贝叶斯回归与计数数据:泊松回归
- Robust Bayesian Regression / 鲁棒贝叶斯回归
- Hierarchical Models / 分层模型
- Markov Chain Monte Carlo (MCMC) and Model Metrics / 马尔可夫链蒙特卡罗(MCMC)和模型指标
- Model Comparison: Cross-Validation and Other Metrics / 模型比较:交叉验证和其他指标

数据&资源
🔥 『Awesome-Inpainting-Tech』图像补全相关文献资源列表
https://github.com/zengyh1900/Awesome-Image-Inpainting
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.08.25 『音频处理』 Contrastive Audio-Language Learning for Music
- 2022.08.20 『视频目标检测』 YOLOV: Making Still Image Object Detectors Great at Video Object Detection
- 2022.09.03 『运动规划』 miniSAM: A Flexible Factor Graph Non-linear Least Squares Optimization Framework
⚡ 论文:Contrastive Audio-Language Learning for Music
论文时间:25 Aug 2022
领域任务:Audio to Text Retrieval, Genre classification, 音频处理,自然语言处理
论文地址:https://arxiv.org/abs/2208.12208
代码实现:https://github.com/ilaria-manco/muscall
论文作者:Ilaria Manco, Emmanouil Benetos, Elio Quinton, György Fazekas
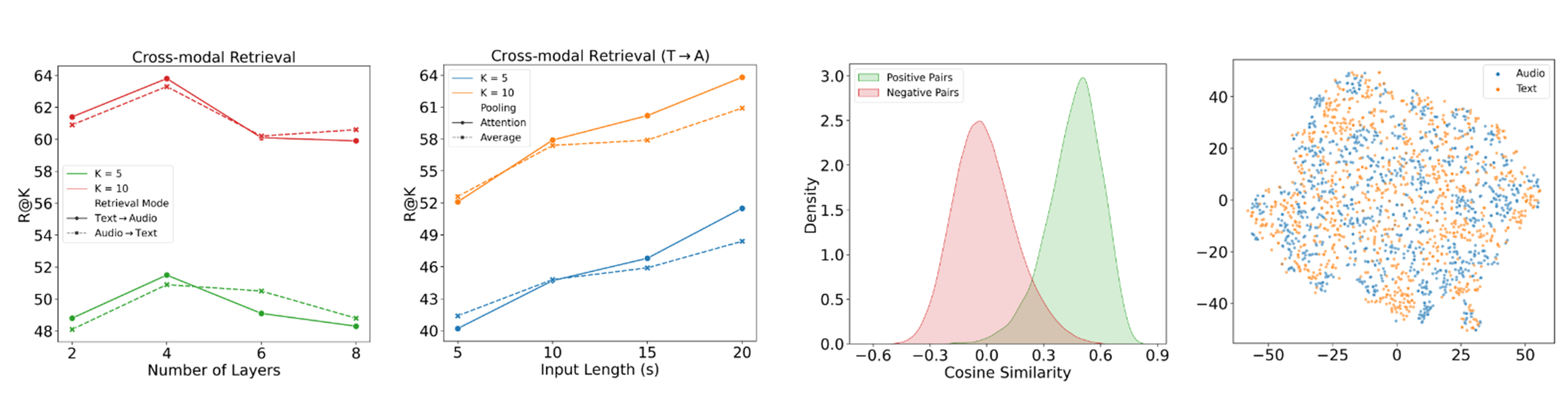
论文简介:In this work, we explore cross-modal learning in an attempt to bridge audio and language in the music domain./在这项工作中,我们探索了跨模式学习,试图在音乐领域的音频和语言之间架起桥梁。
论文摘要:作为人类已知的最直观的界面之一,自然语言有可能调解许多涉及人机交互的任务,特别是在像音乐信息检索这样以应用为重点的领域。在这项工作中,我们探索了跨模式学习,试图在音乐领域中连接音频和语言。为此,我们提出了MusCALL,一个音乐对比性音频-语言学习的框架。我们的方法包括一个双编码器架构,它学习音乐音频和描述性句子对之间的对齐,产生多模态嵌入,可用于文本到音频和音频到文本的检索,即开即用。由于这一特性,MusCALL可以被转移到几乎任何可以被投射为基于文本的检索的任务上。我们的实验表明,我们的方法在检索与文本描述相匹配的音频和反之与音频查询相匹配的文本方面的表现明显优于基线。我们还证明,我们的模型的多模态对齐能力可以成功地扩展到两个公共数据集的流派分类和自动标签的零样本迁移学习场景中。
⚡ 论文:YOLOV: Making Still Image Object Detectors Great at Video Object Detection
论文时间:20 Aug 2022
领域任务:Video Object Detection,视频目标检测
论文地址:https://arxiv.org/abs/2208.09686
代码实现:https://github.com/yuhengsss/yolov
论文作者:Yuheng Shi, Naiyan Wang, Xiaojie Guo
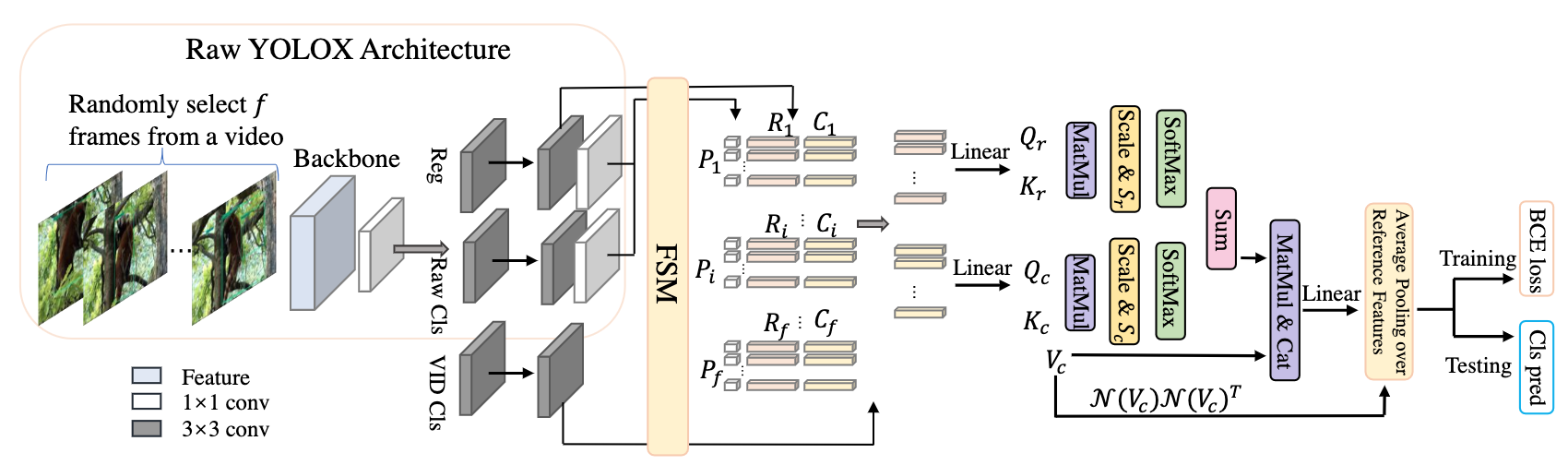
论文简介:On the positive side, the detection in a certain frame of a video, compared with in a still image, can draw support from other frames./从积极的方面来看,与静止图像相比,视频中某一帧的检测可以从其他帧中获得支持。
论文摘要:视频物体检测(VID)具有挑战性,因为物体的外观变化很大,而且在某些帧中存在不同的恶化。从正面看,与静止图像相比,视频中某一帧的检测可以从其他帧中获得支持。因此,如何在不同的帧中聚合特征是VID问题的关键所在。大多数现有的聚合算法是为两阶段检测器定制的。但是,由于两阶段的性质,这类检测器的计算成本通常很高。这项工作提出了一个简单而有效的策略来解决上述问题,它在花费边际开销的同时,在精度上也有明显的提高。具体来说,与传统的两阶段流水线不同,我们主张将区域级选择放在单阶段检测之后,以避免处理大量低质量的候选人。此外,我们还构建了一个新的模块来评估目标帧和其参考帧之间的关系,并指导聚合工作。我们进行了大量的实验和消减研究,以验证我们设计的有效性,并揭示了其在有效性和效率方面比其他最先进的VID方法的优势。我们的基于YOLOX的模型可以实现很好的性能(例如,在单个2080Ti GPU上,在ImageNet VID数据集上以超过30 FPS的速度实现87.5%的AP50),使其对大规模或实时应用具有吸引力。实施很简单,演示代码和模型已经在 https://github.com/YuHengsss/YOLOV 开放。

⚡ 论文:miniSAM: A Flexible Factor Graph Non-linear Least Squares Optimization Framework
论文时间:3 Sep 2019
领域任务:Motion Planning, Simultaneous Localization and Mapping,运动规划
论文地址:https://arxiv.org/abs/1909.00903
代码实现:https://github.com/dongjing3309/minisam
论文作者:Jing Dong, Zhaoyang Lv
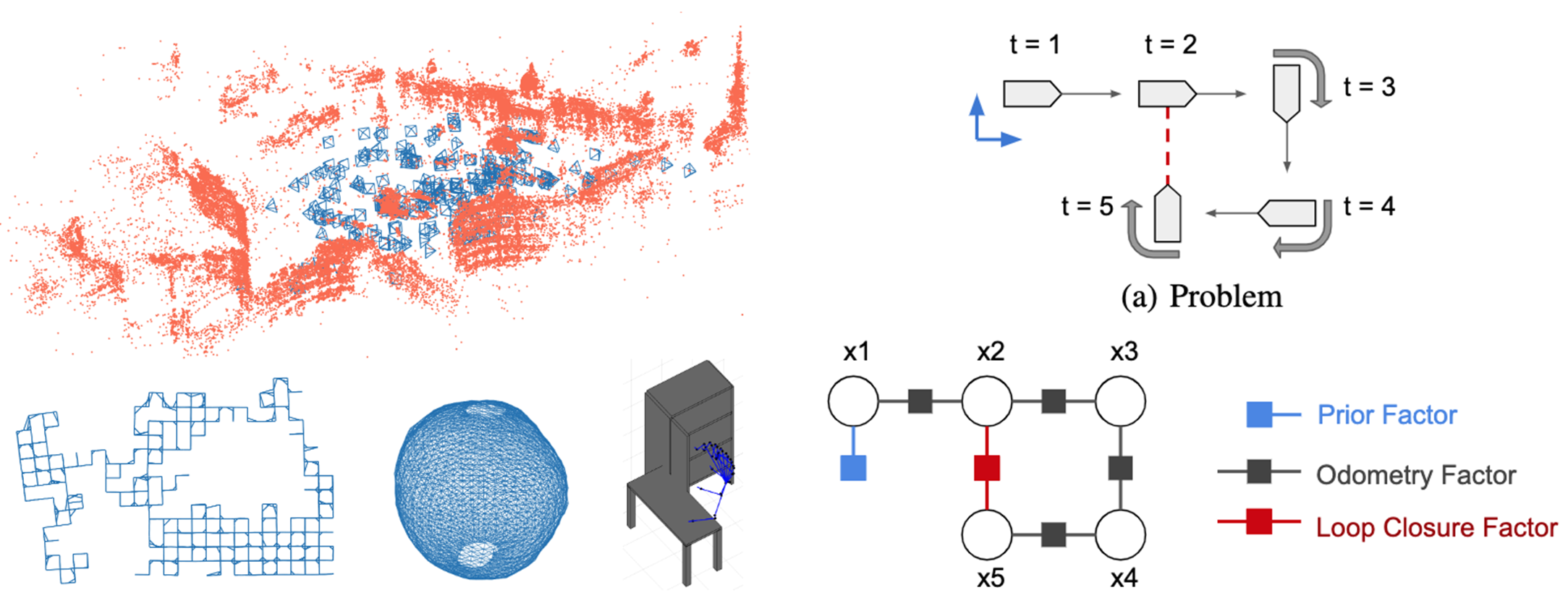
论文简介:Many problems in computer vision and robotics can be phrased as non-linear least squares optimization problems represented by factor graphs, for example, simultaneous localization and mapping (SLAM), structure from motion (SfM), motion planning, and control./计算机视觉和机器人学中的许多问题可以被表述为由因子图表示的非线性最小二乘法优化问题,例如,同步定位和映射(SLAM)、来自运动的结构(SfM)、运动规划和控制。
论文摘要:计算机视觉和机器人技术中的许多问题可以被表述为由因子图表示的非线性最小二乘法优化问题,例如,同步定位和映射(SLAM)、来自运动的结构(SfM)、运动规划和控制。我们开发了一个开源的C++/Python框架miniSAM,用于解决这种基于因子图的最小二乘法问题。与大多数现有的最小二乘法求解器框架相比,miniSAM具有(1)完整的Python/NumPy API,这使得开发更加敏捷,并且容易与现有的Python项目结合,以及(2)广泛的稀疏线性求解器列表,包括支持CUDA的稀疏线性求解器。我们的基准测试结果表明,miniSAM在各种类型的问题上具有可比性,并且具有更灵活、更流畅的开发体验。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

{kind=link}
所有评论(0)