
华南理工提出多模态ReID新数据集,语义自对齐网络SSAN达到SOTA性能!代码数据集均已开源!...
关注公众号,发现CV技术之美本篇分享论文『Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification』,华南理工提出多模态ReID新数据集,语义自对齐网络SSAN达到SOTA性能!代码数据集均已开源!详细信息如下:论文地址:https://arxiv.org/pdf/2107.1266
关注公众号,发现CV技术之美
本篇分享论文『Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification』,华南理工提出多模态ReID新数据集,语义自对齐网络SSAN达到SOTA性能!代码数据集均已开源!
详细信息如下:

论文地址:https://arxiv.org/pdf/2107.12666.pdf[1]
代码地址:https://github.com/zifyloo/SSAN[2]
01
摘要
文本到图像的人物再识别(ReID)旨在使用文本描述搜索包含感兴趣人物的图像。然而,由于在文本描述中存在显著的模态差异和较大的类内差异,文本到图像ReID仍然是一个具有挑战性的问题。
因此,在本文中,作者提出了一种语义自对齐网络(SSAN)来处理上述问题。首先,作者提出了一种新的方法,自动提取其相应视觉区域的部分级文本特征。其次,设计了一个多视图非局部网络,捕捉身体部位之间的关系,从而在身体部位和名词短语之间建立更好的对应关系。第三,引入了一种复合排序(CR)损失,该损失利用相同身份的其他图像的文本描述来提供额外的监督,从而有效地减少了文本特征的类内方差。最后,为了加快文本到图像ReID的未来研究,作者建立了一个新的数据库ICFG-PEDES。
大量实验表明,SSAN在很大程度上优于最先进的方法。
02
Motivation
文本部到图像人物再识别(ReID)是指根据自然语言描述搜索包含感兴趣人物(例如失踪儿童)的图像。当没有目标人的探测图像并且只有文本描述可用时,它是一个重要而强大的视频监控工具。与使用预先定义的属性的ReID作品相比,文本描述包含了更多的信息,因此描述了更多样化和更细粒度的视觉模式。不幸的是,现有的大多数ReID文献都关注基于图像的ReID,文本到图像的ReID仍处于起步阶段。
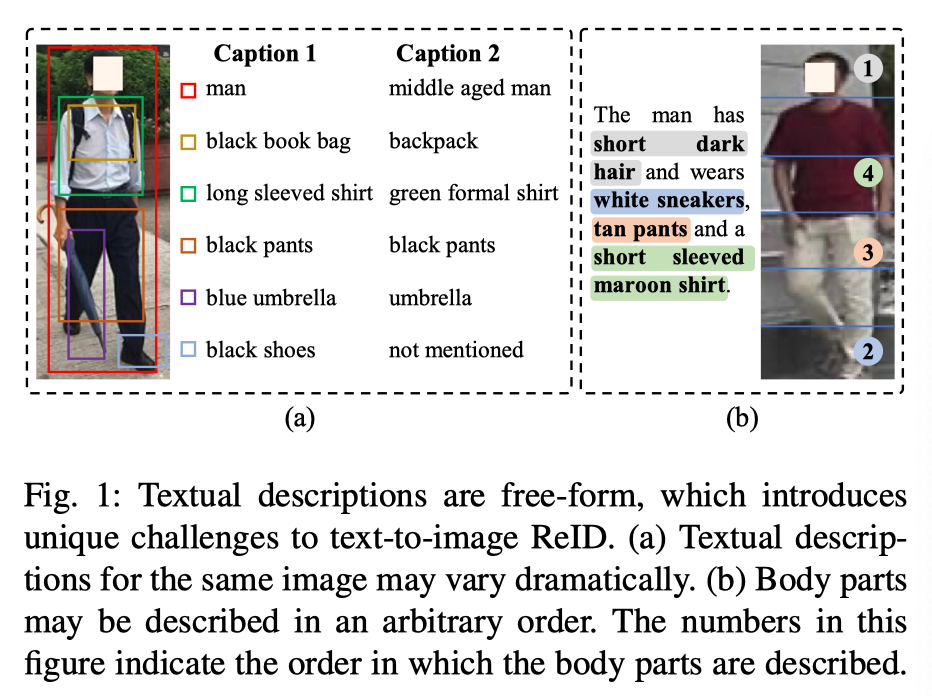
文本到图像的ReID比基于图像的ReID更具挑战性。其中一个主要原因是文本描述是自由形式的,这造成了两个主要问题。首先,如上图(a)所示,同一图像的文本描述可能会发生显著变化,导致文本特征的类内差异很大。其次,身体部位通常是和行人检测对齐良好;然而,如上图(b)所示,身体部位可以用不同数量的单词以任意顺序进行描述,因此在从两种模式中提取语义对齐的部件级特征时存在困难。
因此,跨模态对齐对于文本到图像ReID至关重要。一种流行的跨模态对齐策略涉及采用注意力模型来获取身体部位和单词之间的对应关系。然而,该策略依赖于每个图像-文本对的跨模态操作,这在计算上很昂贵。
另一种直观的策略是使用外部工具,例如自然语言工具包,将一个文本描述分解为若干组名词短语。每组名词短语对应一个特定的身体部位。这种方法的缺点是文本特征的质量对外部工具的可靠性很敏感。此外,分割操作破坏了名词短语之间的相关性,降低了文本特征的质量。
在本文中,作者提出了一种新的模型,称为语义自对齐网络(SSAN),它可以有效地提取语义对齐的视觉和文本部分特征。SSAN不分割文本描述或执行跨模态操作;相反,它探索图像中相对对齐的身体部位作为监督,并利用语言描述中的语境线索来实现这一目标。
具体地说,作者首先通过将视觉主干中的特征图分割为非重叠区域来提取part级视觉特征。然后,使用双向长短时记忆网络(Bi-LSTM)处理每个文本描述来捕捉单词之间的关系。在语境提示的帮助下,使用基于每个单词表示的单词注意模块(WAM)来推断单词部分对应。
因此,可以参考词-部分对应关系获得原始部分级纹理特征。部分级视觉和文本特征由两种模式之间共享的1×1卷积(Conv)层进一步定义。最后,通过约束两种模态的部分级特征相似,WAM被迫做出合理的预测,减少了两种模态之间的语义差距。
然而,上述模型忽略了身体部位之间的相关性。在文本描述中,一个名词短语通常涵盖几个身体部位(例如“长裙”)。此外,文本描述可以指定图像区域之间的某些空间关系(例如,“拿着一个袋子”)。因此,作者提出了一种基于非局部注意机制的多视图非局部网络(MV-NLN),以捕捉身体部位之间的关系。
首先,作者通过多视图投影计算共享嵌入空间中第k部分特征和每个其他部分特征之间的相似性。接下来,相似性分数指定第k部分和其他部分之间的交互强度。交互后,每个部件特征的接受域扩展到与名词短语更一致。
此外,为了克服描述中的类内方差,作者提出了一种复合排序(CR)损失。在传统的排名损失中,正对由完全匹配的图像-文本对组成。由于观察到一个文本描述可以粗略地标注相同身份的其他图像,CR-loss采用它们组成弱监督项来优化网络。然而,这种粗略标注的描述能力差别很大,这取决于文本的质量和两个图像之间的外观差异。因此,作者提出了一种针对新损失项自适应调整margin的策略。CR损失可以被视为一种新的数据增强方法。
最后,由于只有一个大型数据库可用(即CUHK-PEDES),作者为文本到图像ReID构建了一个新的数据库,名为以身份为中心的细粒度人物描述数据集(ICFG-PEDES)。与CUHK-PEDES相比,本文的新数据库有三个关键优势。首先,它的文本描述以身份为中心,纹理清晰;
相比之下,CUHK-PEDES中的文字描述相对较短,可能包含与身份无关的细节(如动作和背景)。更具体地说,ICFG-PEDES的每个字幕平均比CUHK-PEDES多58%。其次,ICFG-PEDES中包含的图像更具挑战性,由于存在复杂背景和可变照明,因此包含更多外观变化。第三,ICFG-PEDES的规模更大:其包含的图像比CUHK-PEDES多36%。
作者在ICFG-PEDES和CUHK-PEDES数据库上进行了广泛的实验。结果表明:SSAN大大优于现有方法。此外,SSAN在效率和易用性方面具有进一步的优势。
03
方法
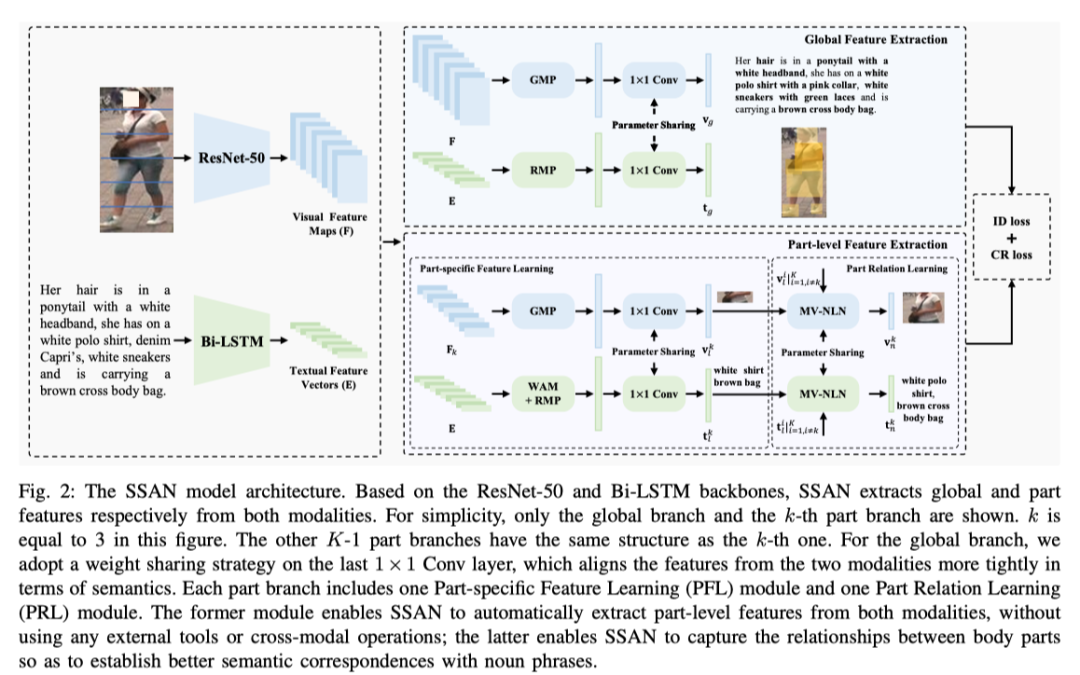
SSAN的总体架构如上图所示。
Backbone
视觉表征提取
作者采用流行的ResNet-50模型作为视觉特征提取主干。如上图所示,作者首先提取特征映射,其中H、W和C分别表示特征图的高度、宽度和通道数。对于全局分支,作者直接利用学习全局视觉特征。对于部分分支作者们首先将均匀划分为K个非重叠部分 。然后,从中提取部分级视觉特征。
文本表示提取
作者建立了一个矩阵包含训练集中所有唯一单词的单词嵌入。这里,V和U分别表示单词嵌入维度和唯一单词的数量。给定长度n的描述D,第i个单词的单词嵌入为。
为了捕捉单词之间的关系,作者采用双向长短时记忆网络(Bi LSTM)作为文本主干。Bi LSTM处理从到和到的字嵌入,如下所示:
其中和分别表示第i个字的正向和反向隐藏状态。接下来,第i个单词的表示定义如下:
就最后将进行堆叠来表示文本描述D:
其中。
Global Feature Extraction
SSAN 将整体视觉和文本特征投影到一个公共空间中。为了获得全局特征,作者首先在F上执行全局最大池化(GMP),在E上执行行最大池化(RMP)。然后,通过共享的1×1 Conv层将获得的特征投影到公共特征空间中:
其中。表示全局视觉和文本特征。与以前的方法相比,上的权重共享策略鼓励F和E在语义方面更紧密地对齐。
最后,一个图像-文本对的全局特征之间的相似性表示如下:
Part-level Feature Extraction
部分级表示对于ReID至关重要。因此,作者在SSAN中引入了部分分支,可以有效地提取语义一致的部分级视觉和文本特征。每个部分分支包括一个部分特定特征学习(PFL)模块和一个部分关系学习(PRL)模块。
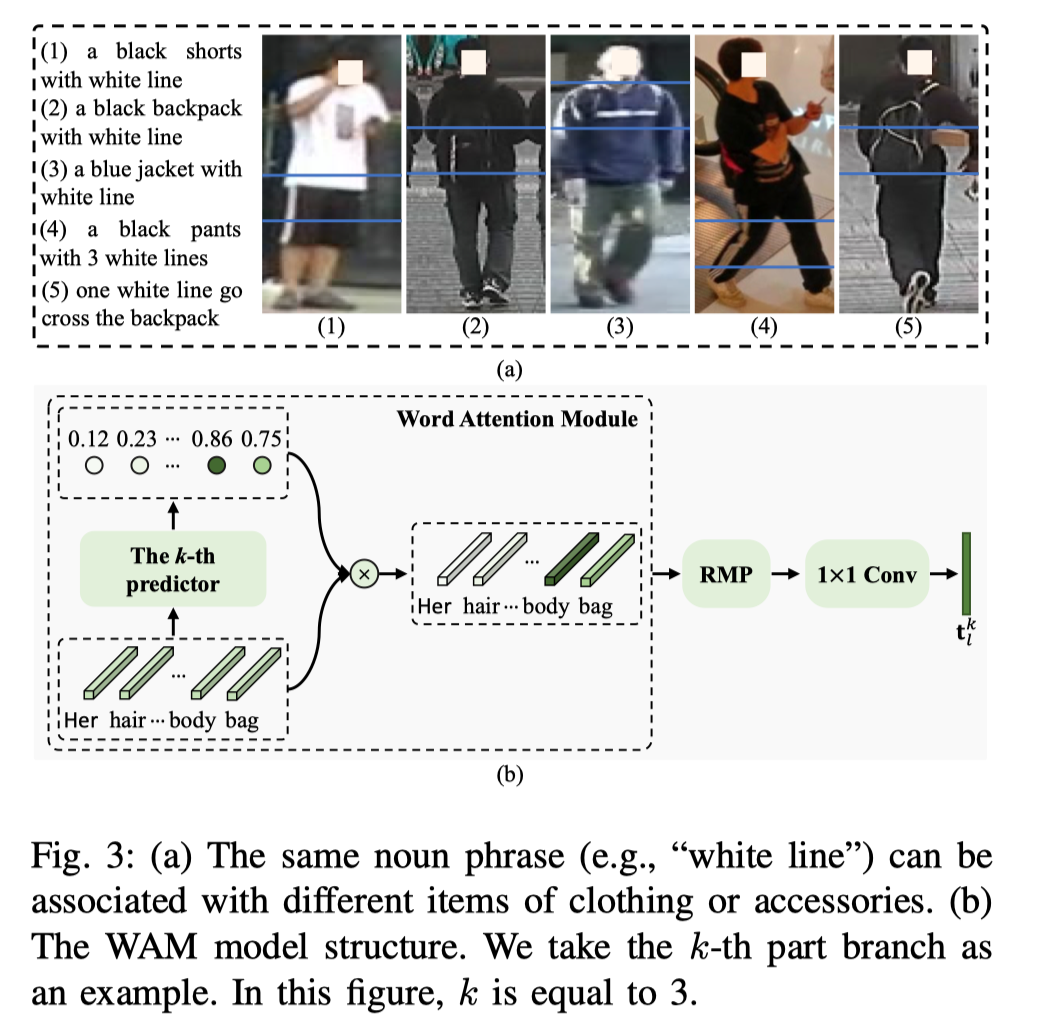
1) 部分特定特征学习(PFL): 为了获得部分级别的文本特征,现有方法通常首先使用外部工具检测名词短语,然后提取每个部分的文本特征。但是,此策略会破坏文本上下文。例如,如上图(a) 所示,名词短语 “白线” 可以涉及不同的服装或配件; 在没有文本上下文的情况下,不能推断 “白线” 和身体部位之间的对应关系。
因此,非常需要直接从原始文本描述中提取部分级文本特征,而无需外部工具。如上图(a)所示,图像中的身体部位通常对齐良好。因此,利用对齐良好的人体部位作为监督,以促进实现这一目标。此外,作者认为,在LSTM处理完成后,将获得语境线索,可以用来推断第i个单词对应的部分。因此,作者提出了以下方法来有效提取语义一致的部分级视觉和文本特征。
首先,作者引入单词注意模块(WAM)来推断单词部分对应关系。如上图(b)所示,作者预测第i个单词属于第k部分的概率如下:
其中表示概率,σ表示sigmoid函数。。作者修改来表示第k个部分的文本描述:
其次,作者通过将馈入一个GMP层和一个1×1 Conv层来获得第k部分的视觉特征。类似地,作者通过对执行RMP来生成第k部分级的文本特征,并将其馈送到与相同的1×1 Conv层:
其中,表示共享1×1 Conv层的参数。分别表示第k部分的视觉和文本特征。
通过将约束为具有区分性和相似性,WAM对词部分对应进行合理的预测。值得注意的是,一个单词可能对应多个部分,如下图(a)所示。此外,共享的1×1 Conv层用于从和中选择与第k部分相关的元素。通过这种方式,可以在没有任何外部工具的情况下获得语义一致的部分级视觉和文本特征。
最后,一个图像-文本对的部分级特征之间的相似性表示如下:
其中。它们分别通过连接K部分级视觉和文本特征获得。
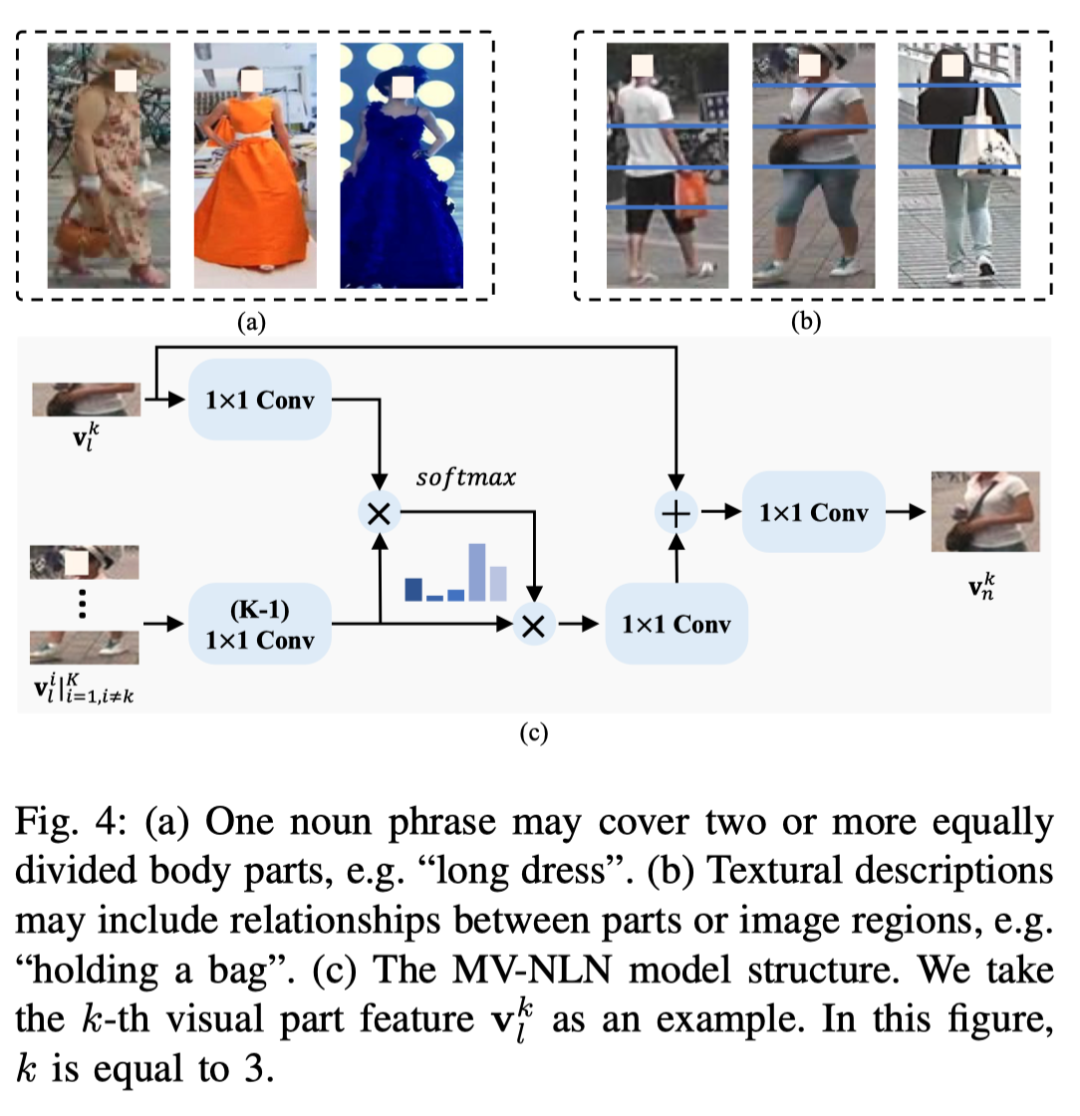
2) 部分关系学习(PRL):F上的等分策略对于基于图像的ReID是有效的。然而,文本到图像ReID可能不太理想,因为一个短语可能涵盖两个或多个等分部分(例如上图(a)中的“长裙”)。此外,文本描述可以指定部分之间的关系(例如上图(b)中的“拿着一个袋子”和“一个袋子交叉的箱子”)。在这种情况下,部分之间的相关性对于区分这两个短语至关重要。
作者提出了多视图非局部网络 (MVNLN) 来解决这些问题。在下文中,作者以第k个视觉部件特征为例。如上图(c) 所示,作者首先通过多视图的投影来计算共享嵌入空间中和之间的相似性:
其中,。。然后,第k个视觉部分特征和其他k-1部分特征之间的交互强度可以表示为:
用于聚合K-1个部分特征:
最后,MV-NLN产生的部分级视觉特征可以表示为:
其中和。
与视觉特征类似,作者还使用MV-NLN来捕捉部分级文本特征的相关性。注意,MV-NLN的参数在两种模态之间共享。与和类似,作者采用余弦度量来评估MV-NLN为一个图像-文本对生成的特征之间的相似性:
其中,和是通过连接MV-NLN产生的K个部分级视觉和文本特征获得的。
Optimization
Ranking Loss应用了一个约束,使得类内相似性得分必须大于类间相似性α,如下所示:
其中,和是从匹配的图像-文本对中提取的。和分别表示小batch中的最难负片文本和的最难负片图像。然而,文本描述是灵活的。上述Ranking Loss仅利用匹配的图像-文本对组成正对,这可能导致过度匹配的风险。

如上图所示,文本描述可以大致标注相同身份的其他图像;换句话说,每个文本描述可以被视为具有相同身份的其他图像的粗略标题。受这一观察结果的启发,作者提出了一种复合排名(CR)损失,包括强监督项和弱监督项。强监督项中的正对是从完全匹配的图像-文本对中提取的。相反,弱监督项中的正对由一个图像和同一身份的另一个图像的文本描述组成。通过这种方式,CR损失为每个训练图像利用更多样的文本描述,作为数据增强策略。在形式上,CR损失定义如下:
其中,是指与具有相同身份的另一个图像的文本描述。和表示margin。β表示弱监督项的权重。
然而,如上图所示,由于图像外观中丰富的类内方差,对的描述能力有所不同,这表明两个弱监督项中的固定margin可能不太理想。为了克服这个问题,作者提出了以下策略来自适应调整α2的值:
其中:
CR损失和常见的ID损失一起用于分别优化全局特征、PFL生成的部分特征和PRL生成的部分特征。注意,ID损失施加在每个K部分特征上,而CR损失施加在concat的K部分特征上。三种类型特征的所有损失项的权重设置为1、0.5和0.5。在测试阶段,一个图像-文本对之间的总体相似性分数是、和的总和。
04
实验
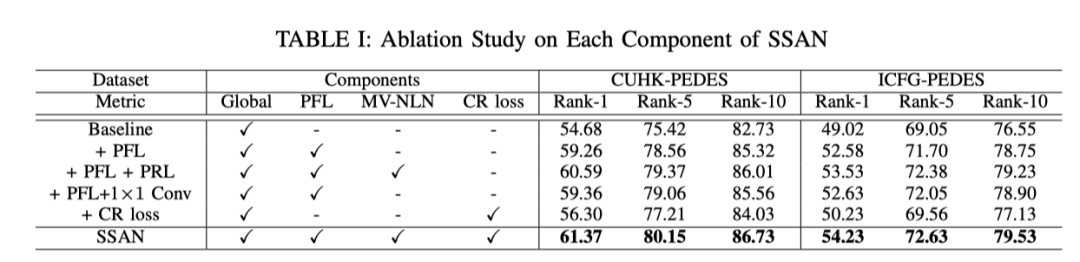
上表展示了本文方法不同模块的消融实验,证明了本文提出的多个模块对于性能提升有正面的作用。
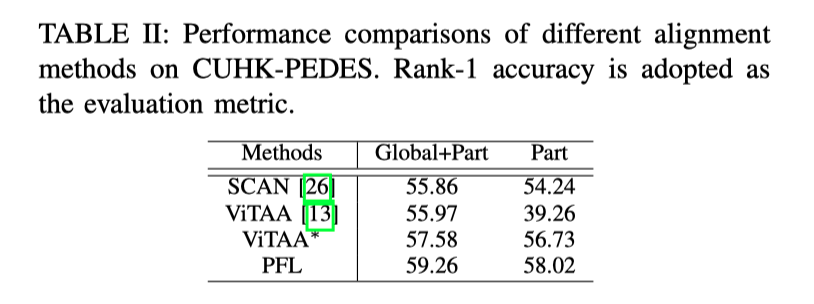
上表展示了不同对齐方法在CUHK-PEDES上的性能比较。采用Rank-1精度作为评估指标。
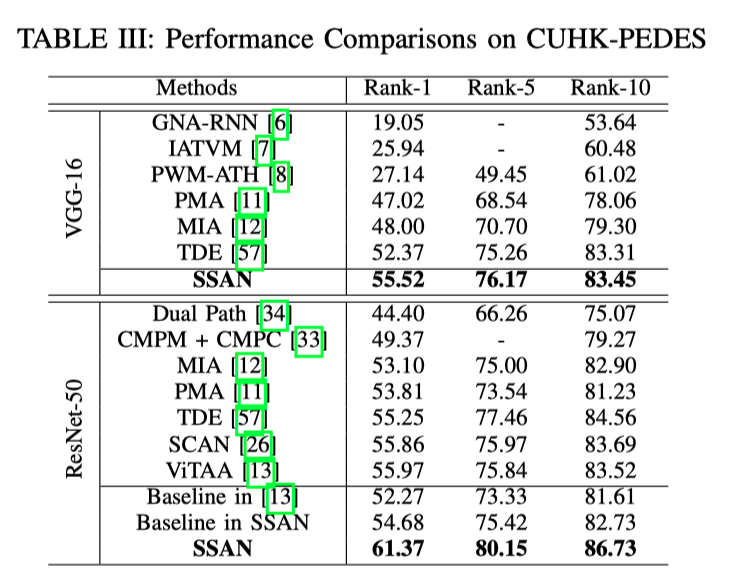
上表展示了不同Backbone在SOTA方法在CUHK-PEDES数据集上的性能的对比。
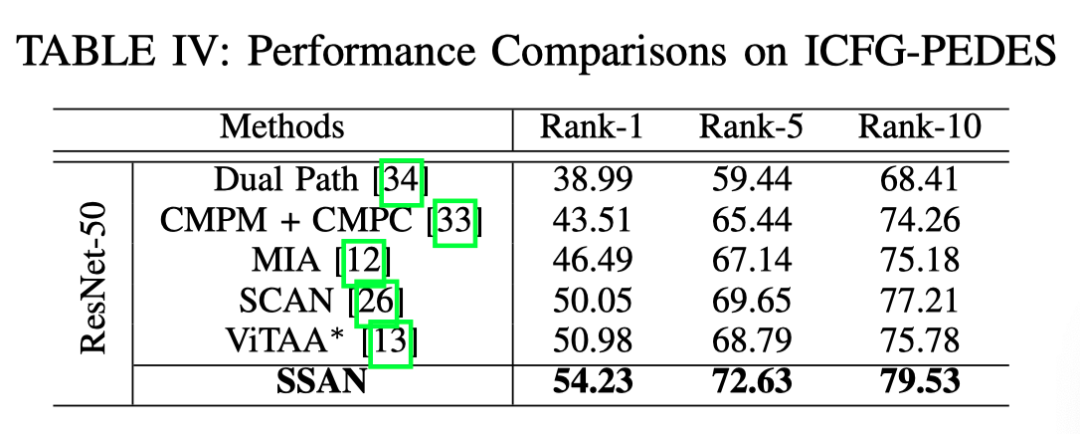
上表展示了不同方法在ICFG-PEDES上的性能对比。
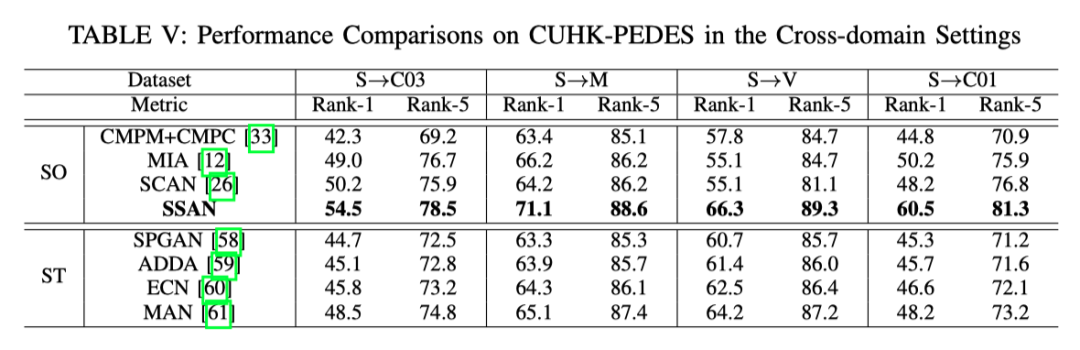
上表展示了本文方法在CUHK-PEDES的Cross-domain设置下的实验结果对比。
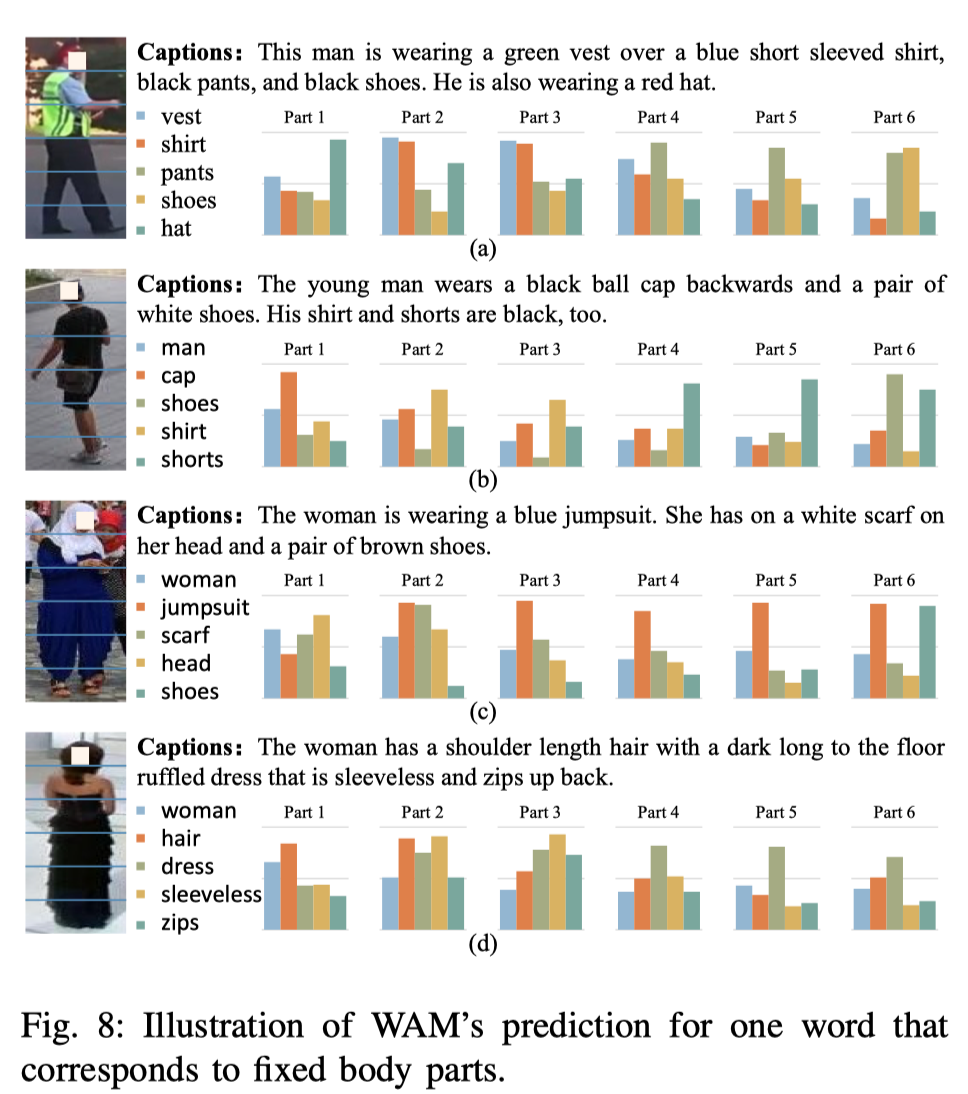
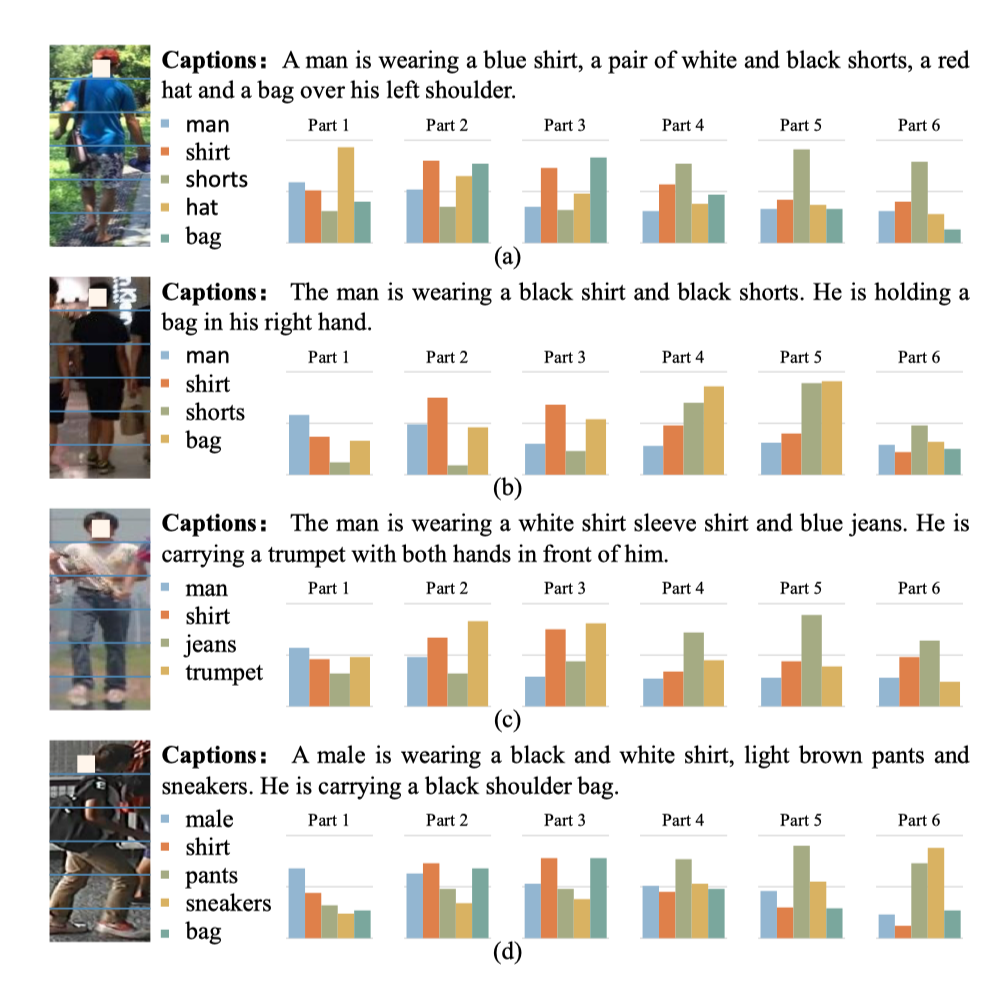
上图展示了在图像中相对对齐的身体部位的监督下,WAM可以对单词进行正确的预测。通过利用文本描述中的语境线索,WAM还对与位置灵活的对象相对应的单词进行了合理的预测。
05
总结
在本文中,作者提出了一种新的模型,称为SSAN,用于自动从文本到图像的ReID的视觉和文本模态中提取语义对齐的特征。
具体来说,作者引入了一个文字注意力模块,该模块能够可靠地关注部分相关文字。这使得SSAN能够通过共享的1×1 Conv层自动提取两种模态的部分级特征。作者进一步提出了一种多视图非局部网络来捕捉身体部分之间的关系。
此外,为了克服文本描述中的大类内方差问题,作者提出了一种包含强监督项和弱监督项的CR损失。最后,为了加快文本到图像ReID的研究,作者建立了一个新的数据集,该数据集以身份为中心,具有细粒度的文本描述。在两个数据集上的大量实验证明了SSAN的有效性。
参考资料
[1]https://arxiv.org/pdf/2107.12666.pdf
[2]https://github.com/zifyloo/SSAN
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
加入「人员重识别」交流群👇备注:reid


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)