
MNN 2.0 发布——移动端推理引擎到通用深度学习引擎
MNN近期更新了2.0版本啦!在整体定位方面,相比于1.0版本的端侧深度学习引擎,MNN 2.0迈向了端云一体化的通用深度学习框架,一方面大幅优化了在服务端CPU和GPU上的性能;另一方面新增了类似OpenCV、Numpy的通用计算模块,以完整覆盖学习任务的前处理、模型运行、后处理3阶段。下面本文将对MNN 2.0的相关技术做详细介绍。MNN 及技术挑战▐MNN 简介...

MNN近期更新了2.0版本啦!在整体定位方面,相比于1.0版本的端侧深度学习引擎,MNN 2.0迈向了端云一体化的通用深度学习框架,一方面大幅优化了在服务端CPU和GPU上的性能;另一方面新增了类似OpenCV、Numpy的通用计算模块,以完整覆盖学习任务的前处理、模型运行、后处理3阶段。下面本文将对MNN 2.0的相关技术做详细介绍。
MNN 及技术挑战
▐ MNN 简介
MNN 是一个轻量级的深度学习引擎,核心解决深度神经网络模型在各类设备,尤其是移动设备/嵌入式设备的推理与训练问题。目前,MNN已经在淘宝、手猫、优酷、聚划算、UC、飞猪、千牛等 30 多个 App 中使用,覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发放、安全风控等场景,每天稳定运行上亿次。基于 MNN 实现了首个端到端、通用型、规模化产业应用的端云协同机器学习系统—— Walle ,相关论文发表在系统领域顶级会议 OSDI'22 上。
MNN 的特点是轻量、通用、易用、高效:
轻量性
主体功能(模型推理CPU+GPU)无任何依赖,代码精简,可以方便地部署到移动设备和各种嵌入式设备中。
iOS平台:功能全开的MNN静态库 armv7+arm64大小12MB左右,链接生成可执行文件增加大小2M左右。裁剪主体功能后静态库大小6.1M ,链接生成可执行文件增加大小 600 KB。
Android平台:主体功能 armv7a - c++_shared 动态库大小800KB左右。
支持采用 Mini 编辑选项进一步降低包大小,大约能在上述库体积基础上进一步降低 25% 左右。
支持模型FP16/Int8压缩与量化,可减少模型50% - 75% 的体积
通用性
支持 Tensorflow、Caffe、ONNX、Torchscripts 等主流模型文件格式,支持CNN / RNN / GAN / Transformer 等主流网络结构。
支持多输入多输出,支持任意维度的输入输出,支持动态输入(输入大小可变),支持带控制流的模型
算子丰富,支持 178 个Tensorflow Op、52个 Caffe Op、142个 Torchscipts Op、158 个 ONNX Op(ONNX 基本完整支持)
支持 服务器 / 个人电脑 / 手机 及具有POSIX接口的嵌入式设备,支持使用设备的 CPU / GPU 计算,支持部分设备的 NPU 计算(IOS 11 + CoreML / Huawei + HIAI)
支持 Windows / iOS 8.0+ / Android 4.3+ / Linux 及具有POSIX接口的操作系统
高性能
对iOS / Android / PC / Server 的CPU架构进行了适配,编写SIMD代码或手写汇编以实现核心运算,充分发挥 CPU的算力,单线程下运行常见CV模型基本达到设备算力峰值。
iOS设备上基于 Metal 实现算子以支持GPU加速,常用模型上快于苹果原生的CoreML。
Android上提供了OpenCL、Vulkan两套方案,针对主流GPU(Adreno和Mali)做了深度调优,其中 OpenCL 侧重于推理性能极致优化,Vulkan 方案注重较少的初始化时间。
广泛运用了 Winograd 卷积算法提升卷积性能,首次在业界工程实践中实现转置卷积的Winograd算法优化与矩阵乘的Strassen算法优化并取得加速效果。
支持低精度计算( int8 / fp16 / bf16)以提升推理性能。并对 ARMv8.2 和 AVX512架构的相关指令进行了适配,这两种架构下有更好的加速效果。
易用性
支持使用 MNN 的算子进行常用的数值计算,覆盖 numpy 常用功能
提供 MNN CV 模块,支持图像仿射变换与归一化等 MNN_CV 库,支持常用的图像处理(armv7a 架构下小于 100 k )
支持各平台下的模型训练,尤其是移动端上的模型训练
支持 python 接口
▐ 技术挑战
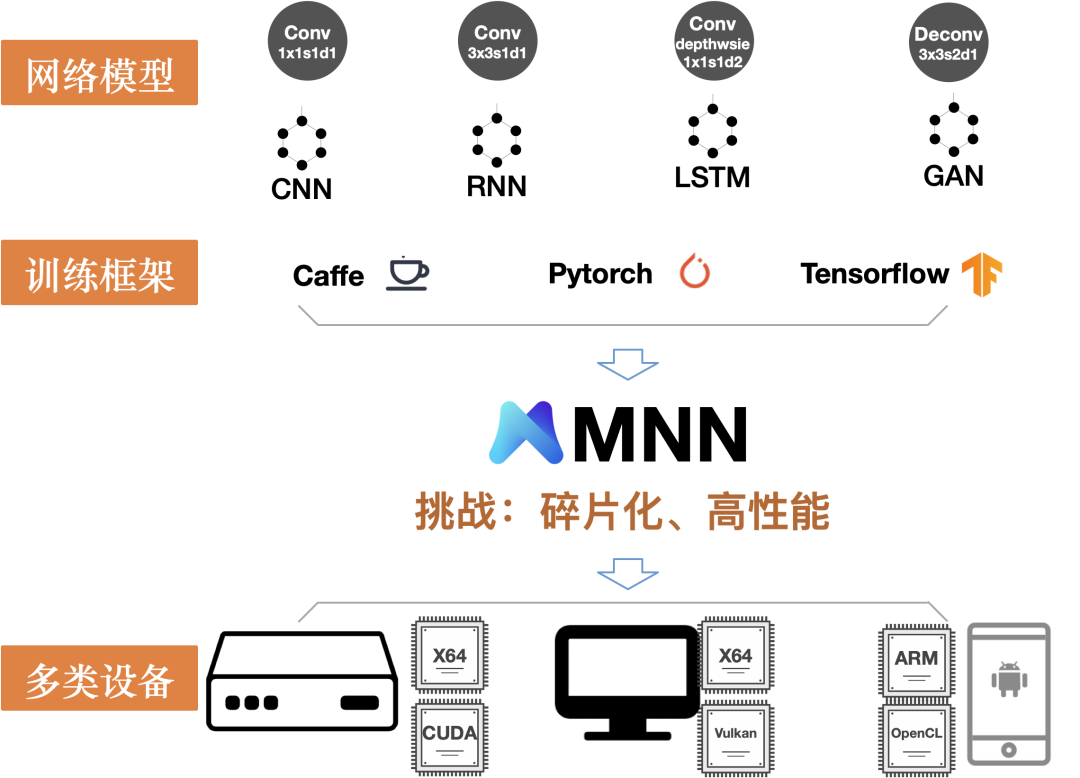
MNN 面临的技术挑战,如上图所示,主要是两个矛盾
AI应用需要的复杂功能支持与受限制的程序体积之间的矛盾
AI 模型本身包含多种算子,并在不断演进,如 ONNX 的算子数目前有 160 个左右,Tensorflow 接近 2000 个,MNN 需要以更精简的代码去实现 AI 模型所需要的这些算子。
AI 应用除去模型推理之外,也包含数据前后处理所需要的数值计算与图像处理模块,算法工程师常用的 Numpy 与 OpenCV 库在移动端上往往因为体积占用过大而不能使用,对应功能也需要 MNN 支持。
AI应用需要的强大算力支撑与碎片化的计算资源之间的矛盾
AI 模型往往计算量很大,需要 MNN 对设备上的计算资源深入适配,持续做性能优化,以充分发挥设备的算力。
计算资源包括 CPU , GPU , DSP 和 NPU ,它们本身编程方式是碎片化的,需要 MNN 逐个适配,开发成本高,也会使程序体积膨胀。
架构设计
为了应对性能与功能层面的挑战,MNN 设计了预推理与表达式两个核心模块:
预推理模块可以降低计算资源的差异性,在任意的计算资源上寻找到较优的计算方案。
表达式模块可以抹平不同训练框架的算子差异,并将模型训练、图像处理、数值计算等功能转换为推理所需要的张量计算图,从而可用 MNN 进行推理。
▐ 预推理
MNN 在加载模型之后,会根据用户设定的输入形状,对模型中的算子做一遍预处理,降低算子种类,寻找最优计算策略,做资源分配。这个过程称为预推理。
预推理相比推理过程是轻量的,若用户设定的输入形状不变,预推理不需要重复执行,可以降低推理延时。
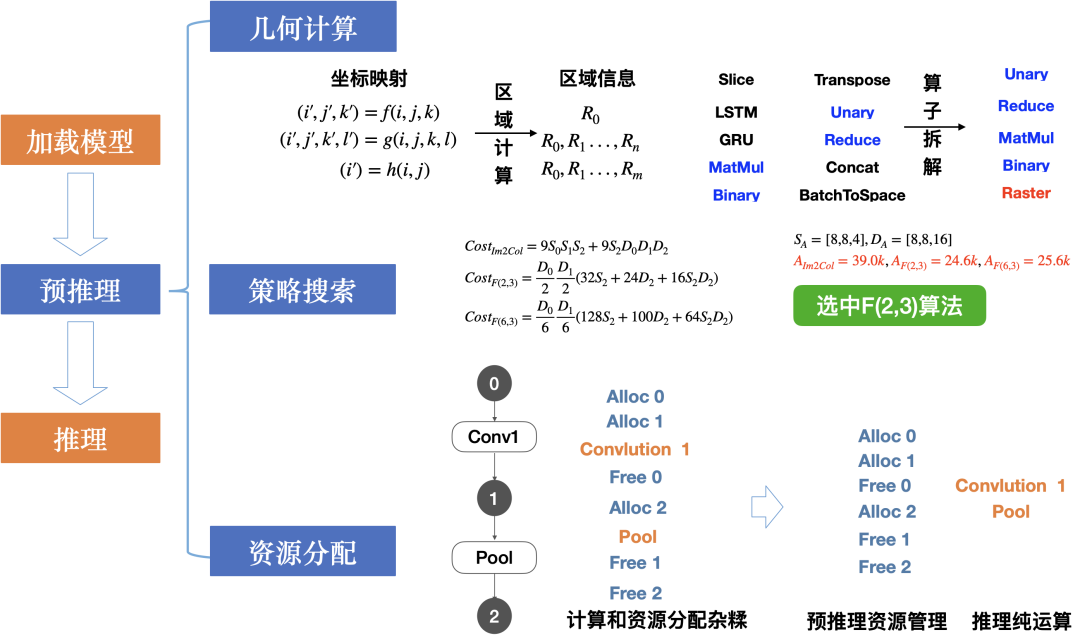
如上图所示,预推理主要包括如下步骤:
策略搜索:对核心算子,根据输入输出的大小,按预设的评估函数计算各类实现策略的成本,选择最优的计算策略。
资源分配:根据网络图的拓扑顺序,计算所需的最小资源分配方案,并进行资源申请。
几何计算:MNN 为了应对计算资源碎片化的问题所创造的新机制。在这一机制下,能够大大降低多算子,多后端情况下的实现成本,同时能够通过在线的算子融合提升模型性能。其核心思想是使用一个通用算子来描述内存映射关系,从而方便开发之使用基础算子组合成复杂算子,降低复杂算子的实现成本。在模型中的内存映射可以描述为张量平面的映射关系如下:
张量平面
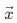 在内存中的线性地址为:
在内存中的线性地址为: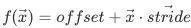 ,因此可以使用offset和stride[]来描述内存张量平面;
,因此可以使用offset和stride[]来描述内存张量平面;对于张量平面
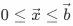 内存映射
内存映射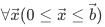 :
: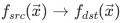 ,当取张量维度为3时,映射关系为:
,当取张量维度为3时,映射关系为: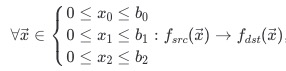
即可用三层嵌套循环实现该映射关系;
因此使用Region来描述张量平面,构造Raster算子来实现张量平面映射;实现了内存映射的元算子。在有了内存映射元算子后,im2col, transpose, concat, split等操作在后端中均可用Raster算子实现;conv3d,pool3d等也可以通过Raster与matmul,pool2d等组合实现,也不需要新增算子,可以大大降低实现的工作量。
同时因为使用了通用的映射表达各类内存映射关系,可以通过循环变换自动化寻找可融合算子,如:Permute(0, 2, 1) + Permute(1, 0, 2)可以自动化合并为Permute(2, 0, 1),减少冗余,提升性能。
▐ 表达式
MNN 需要对接各种训练框架导出的模型格式,有如下特点:
训练框架随版本变迁会有不同的导出格式
训练框架随版本变迁有大量的算子新增与修改
不同训练框架的算子重合度高,但不完全一样
| 框架 | 导出方式 | 导出成功率 | 算子数(不完全统计) | 冗余度 |
|---|---|---|---|---|
| Caffe | Caffe | 高 | 52 | 低 |
| Tensorflow | Pb - 1.x | 高 | 1566 | 高 |
| Tflite | 中 | 141 | 低 | |
| MLIR | 中 | |||
| Pytorch | Onnx | 中 | 165 | 低 |
| Torchscripts | 较高 | 566 | 高 | |
| Torch PKL + Python | 高 |
为了抹平训练框架不同的差异,比较明确的做法就是定义MNN自己一套算子并实现前端,基于基于此对接各个训练框架
这个 MNN 的前端就是表达式模块,对应的 MNN 模型转换流程优化如下:
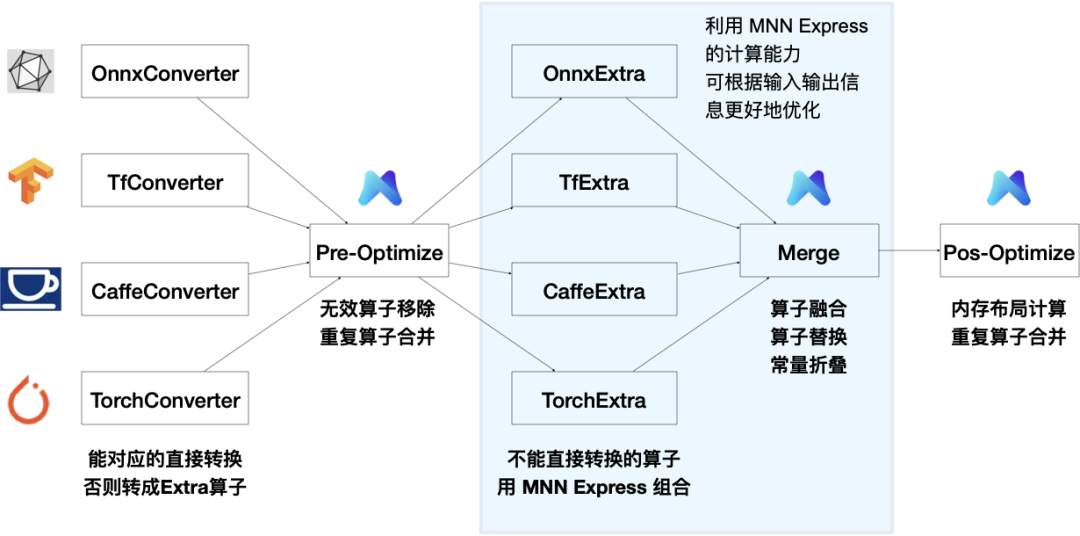
由于 AI 模型的算子数逐渐丰富,推理引擎(或称张量计算引擎)与图像处理和数值计算正在趋同,如 Tensorflow 实现了 numpy 库,OpenCV 也通过 GAPI 的方式,将图像处理表示为计算图,由内置的张量计算引擎实现。
MNN 也基于表达式去实现了 Numpy 和 OpenCV 常用功能,详细见下文。
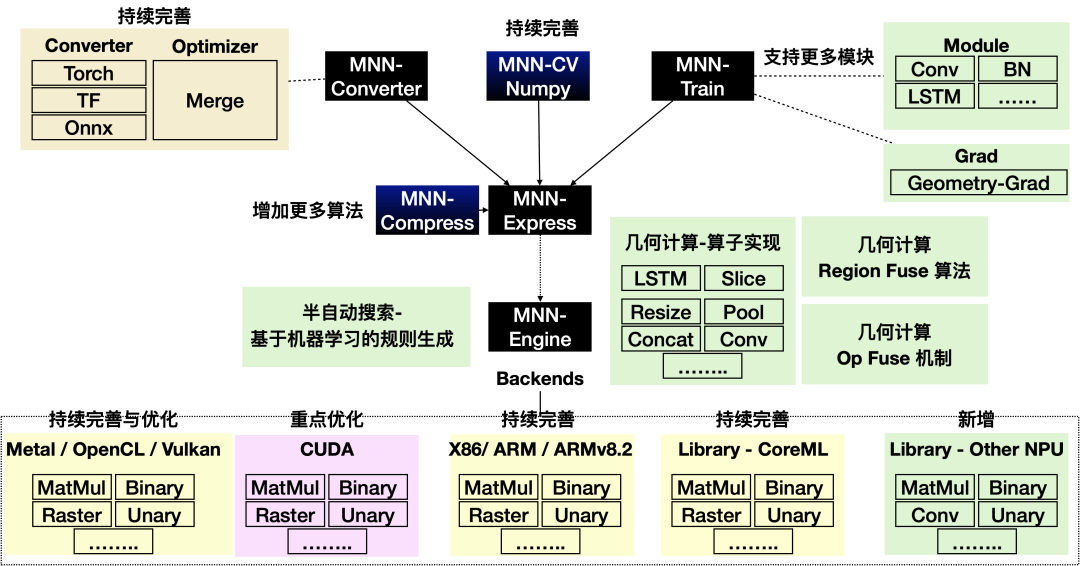
▐ 整体架构

MNN可以分为主体(推理引擎)和工具两大部分。
主体:亦即推理引擎,负责AI模型(张量计算图)的加载与执行,可分为调度(预推理)与执行(推理)两层。
工具
MNN-Converter:模型转换工具,由Frontends和Graph Optimize构成。前者负责支持不同的训练框架,MNN当前支持Tensorflow(Lite)、Caffe、ONNX(PyTorch/MXNet的模型可先转为ONNX模型再转到MNN)和Torchscripts;后者通过算子融合、算子替代、布局调整等方式优化图,一般离线运行。
MNN-Compress: 模型压缩工具,在一定的精度误差许可下,对模型进行压缩,减少模型体积,提升运行性能。
MNN-Express :支持带控制流的模型运行,支持调用 MNN 的算子进行自定义的计算。
MNN-CV :类似 OpenCV ,但核心计算功能基于 MNN 实现的图像处理算法库
MNN-Train :MNN 训练模块,支持各平台训练
性能优化
MNN 的架构设计可以降低性能优化的成本,但性能优化本身仍然是MNN中最艰难复杂的工作,需要深入理解模型结构、算子实现、硬件架构,分析模型运行中的计算冗余,并将其尽可能地压制。
▐ 冗余分析
深度学习推理中存在的计算冗余大致可分为以下几类:
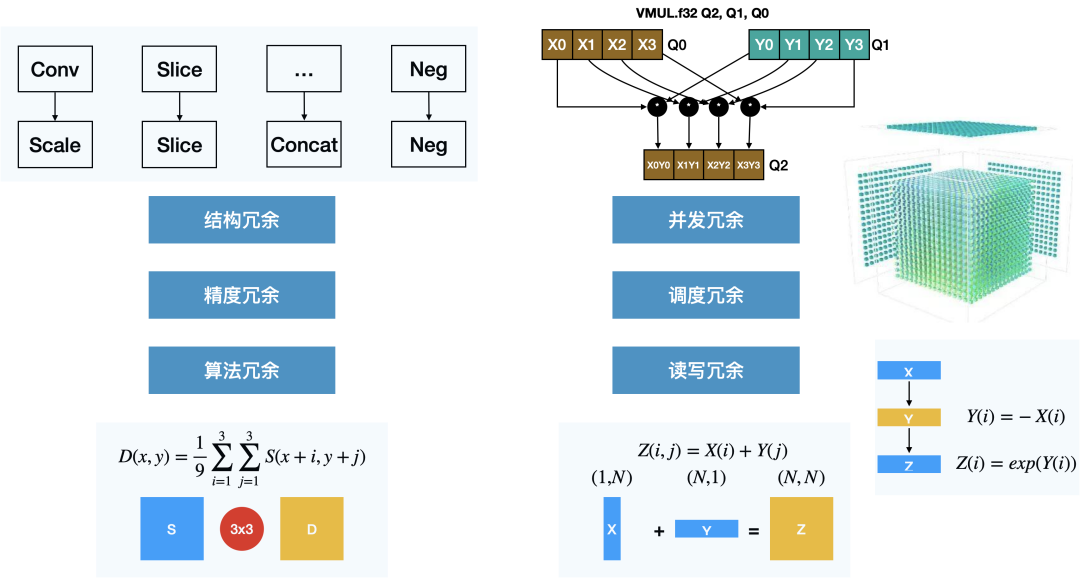
结构冗余:模型结构中的无效计算节点,也是惟一可以无损去除的冗余类型
精度冗余:深度学习推理引擎的数据单元是张量,一般是32位浮点数组,32位浮点的范围在很多场景是存在冗余的,往往可以压缩到16位或者8位甚至更低;另一方面,浮点数组中也可能存大量的0或者其他重复数据,也有优化空间。
算法冗余:算子的实现算法本身存在计算冗余,比如均值模糊的滑窗实现
并发冗余:未充分使用计算资源的并发能力(SIMD / 多线程 / GPU 等等),导致计算资源闲置,亦或受并发能力本身的限制,需要计算多余的数据(比如计算长度为3 ,但SIMD单元为4的向量加法)
调度冗余:使用多线程、GPU 或者其他异构计算资源时,在 CPU 端需要组织计算,分拆任务,传输计算信息,该行为产生额外的计算冗余
读写冗余:在一些计算场景重复读写内存,或者内存访问不连续导致不能充分利用硬件缓存,产生多余的内存传输
▐ 结构/精度
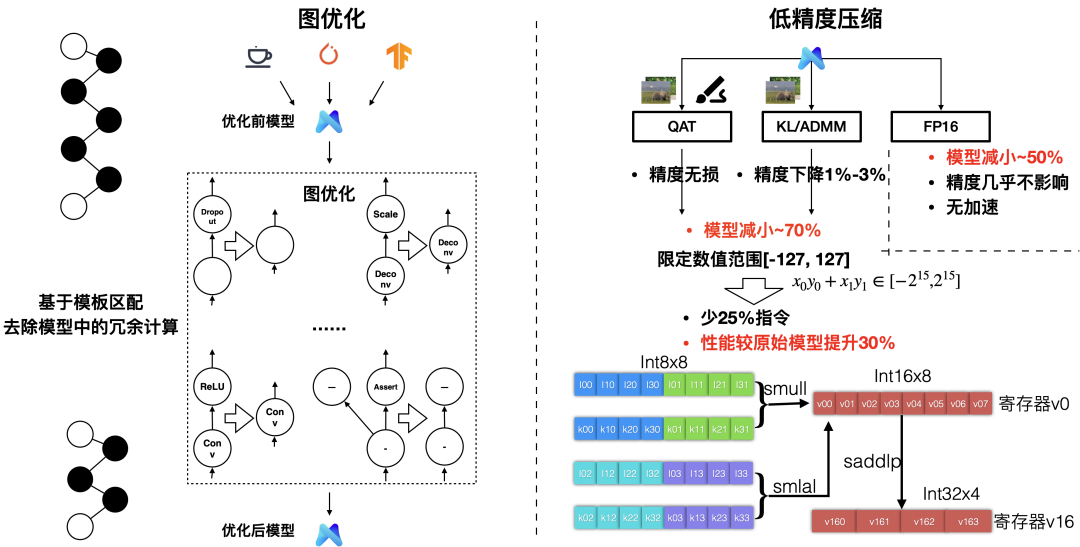
图优化与模型量化
结构冗余与精度冗余的压制一般需要离线工具辅助,MNN 对应提供了图优化、模型压缩工具,在端上则提供了部分架构的低精度的计算支持。
图优化:基于一系列预先写好的模板,去除模型中的冗余计算,比如 Convolution 与 BatchNormal / Scale 的合并,Dropout 去除等。图优化能在特定场景下带来相当大的计算收益,但相当依赖根据先验知识编写的模板,相比于模型本身的复杂度而言注定是稀疏的,无法完全去除结构冗余
模型量化:通过把模型中的常量压缩成 FP16 或 Int8 ,可以降低模型大小,进一步地可以压缩模型中的变量(featuremap),亦即为模型中每层的输入输出寻找FP16/Int8 到 FP32 的映射关系,这样可以在模型运行时用低精度进行计算加速
低精度计算:MNN 在ARMv7a/ARMv8上实现了int8,BF16 的加速,分别约有30% / 10% 加速效果。ARMv8.2 架构上用 fp16 vec ,sdot ,分别有 100% 和 200 % 的加速效果。在支持VNNI指令集的x64架构下则有 200% 的性能提升。
稀疏计算加速
为了适配SIMD优化,MNN 通过权重矩阵稀疏化设计,训练合适的稀疏化分布,使权重矩阵呈现出“半结构化”稀疏的特性,而不是在行、列方向完全随机化稀疏,避免了向量vector用不满、数据复用低的弊端。如下图所示的BCSR(Block Compressed Sparse Row ) 格式:
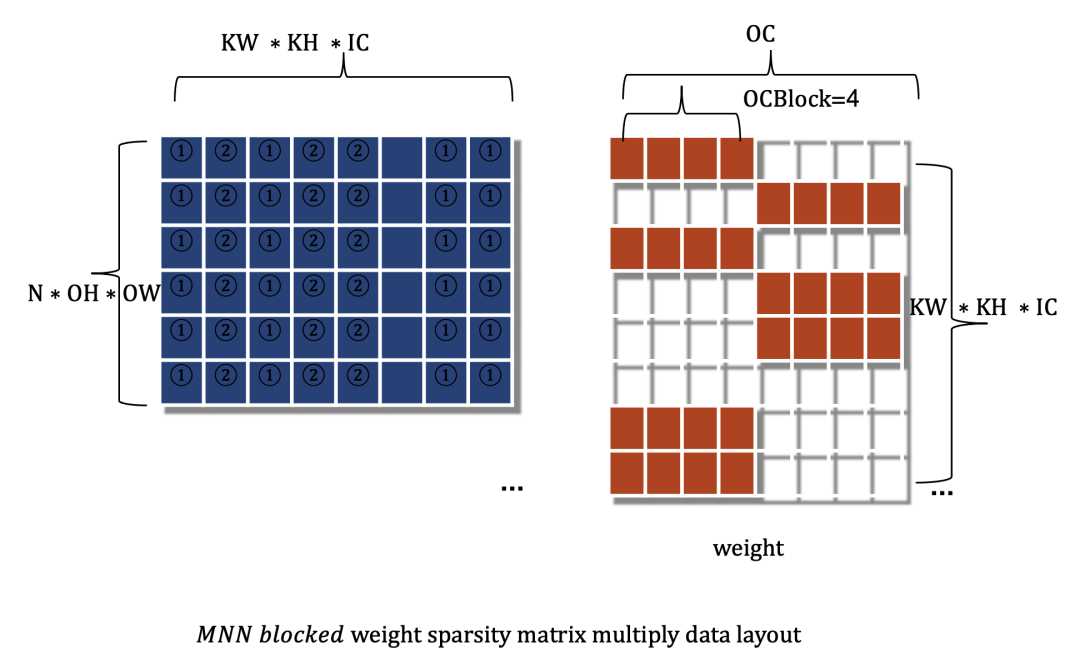
图中白色代表的零元素,实际计算可以跳过,减少计算开销。
MNN实现了对稠密模型权重稀疏化训练的功能,导入MNN Python压缩工具包(mnncompress),设定mnncompress需要的参数,运行将原模型中权重部分数值稀疏化为0。需要注意的是稀疏化0元素的分布模式需要符合分块形态,才能最大化发挥加速性能。
在常规的CPU GPU中并没有稀疏指令支持,我们须用常规向量指令实现计算加速,在MNN中我们设计实现了稀疏算子,最大化提取复用代码、扩展差异化后端。并且稀疏化算子对用户无感知,无需增加认知成本。
在后端方面,为最大化向量并行加速,设计了灵活的“半结构化”分块大小,例如对于AVX2可以用float32 x 8 的分块大小,同时为ARM NEON 和x86 AVX2/AVX512 指令实现了多种稀疏后端内核汇编代码。
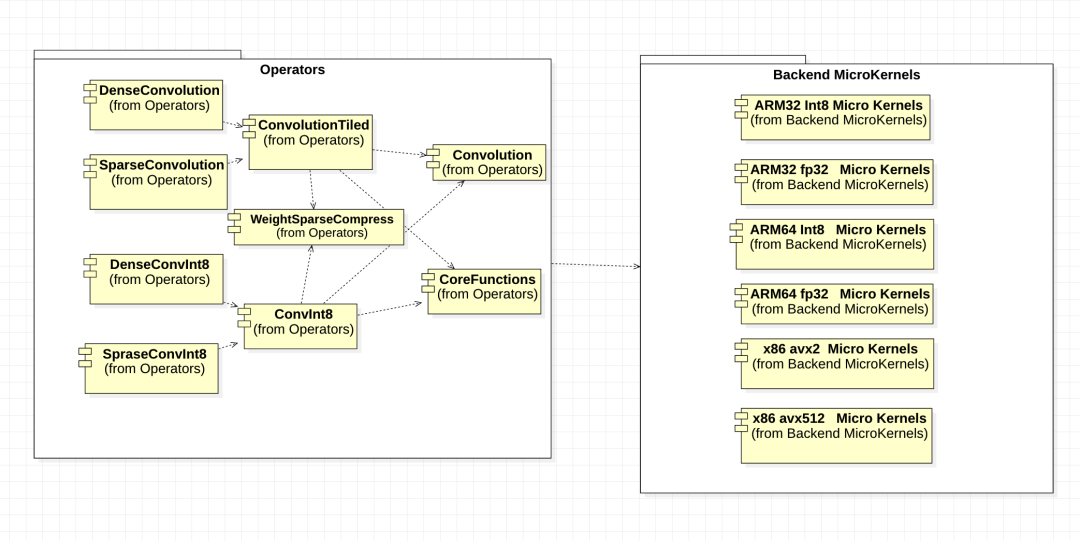
第一点,CV模型在ARM端获得3.16x-4.13x加速比(0.9稀疏度),跨机型、跨模型加速效果都比较显著,详见参考资料大图。
第二点,在实际业务模型中验证了业务精度指标,损失有限、可接受。
第三点,推理耗时随稀疏度增加线性下降,跨模型、cpu 一致;在小米6上,稀疏分块1x4加速临界值优化到0.3,中高端机型甚至稀疏度0.1的时候可达临界值。
▐ 并发/算法/读写
这几类冗余的压制往往是互相冲突的,需要计算方法与内存排布的精心设计与内核计算的深度调优,寻找一个平衡点。
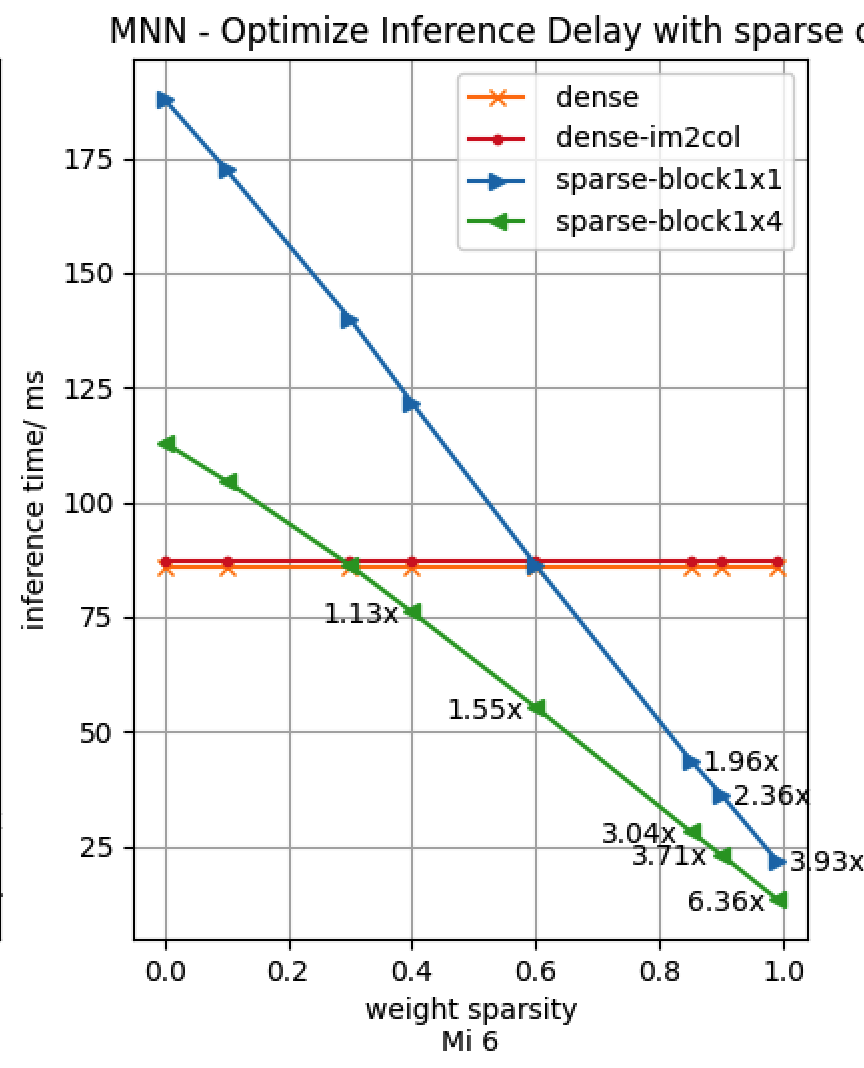
NC4HW4 内存布局
深度学习的CV算子往往具有如下计算特性,在C方向上计算可并行,但需要读取HW方向相邻数据。为了充分利用 SIMD 加速能力,MNN 设计了 NC4HW4 布局,以兼顾 SIMD 使用和内存访问连续的需求。
Strassen 矩阵乘算法与 Winograd 卷积算法
算法方面,MNN 采用 Strassen 算法加速矩阵乘法计算,Winograd 算法加速卷积计算

汇编优化与GPU内核优化
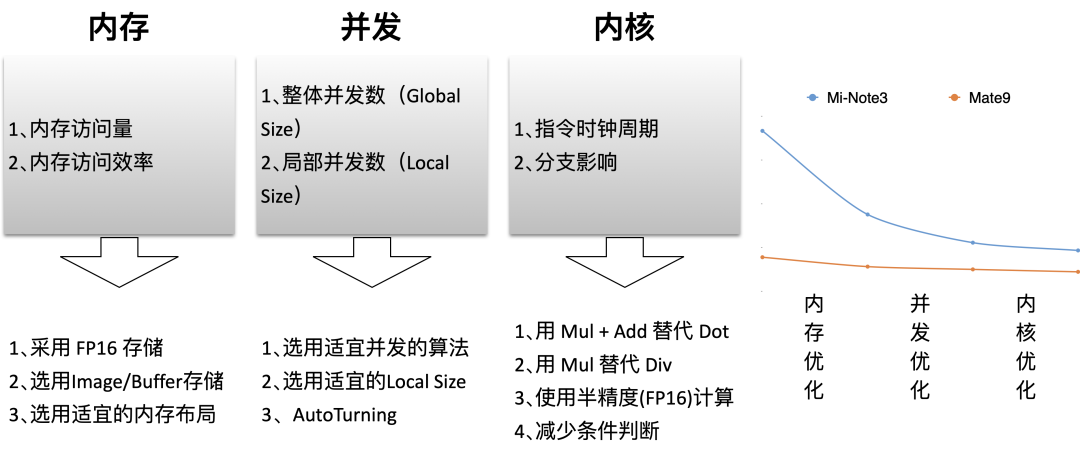
为了降低读写冗余,MNN 在 CPU 的汇编代码中做最大数目的循环展开,并手排指令减少相依数据依赖

GPU则在内存、并发数、内核方面优化,在读写/并发冗余的压制上找到平衡点
▐ 调度
MNN 的预推理模块可以较好地降低调度冗余,我们把算子的执行拆分为 onResize 和 onExecute 两个部分,在预推理过程中执行 onResize ,在推理过程中执行 onExecute ,视各类GPU的API设计不同,可以不同程度地降低调度冗余。
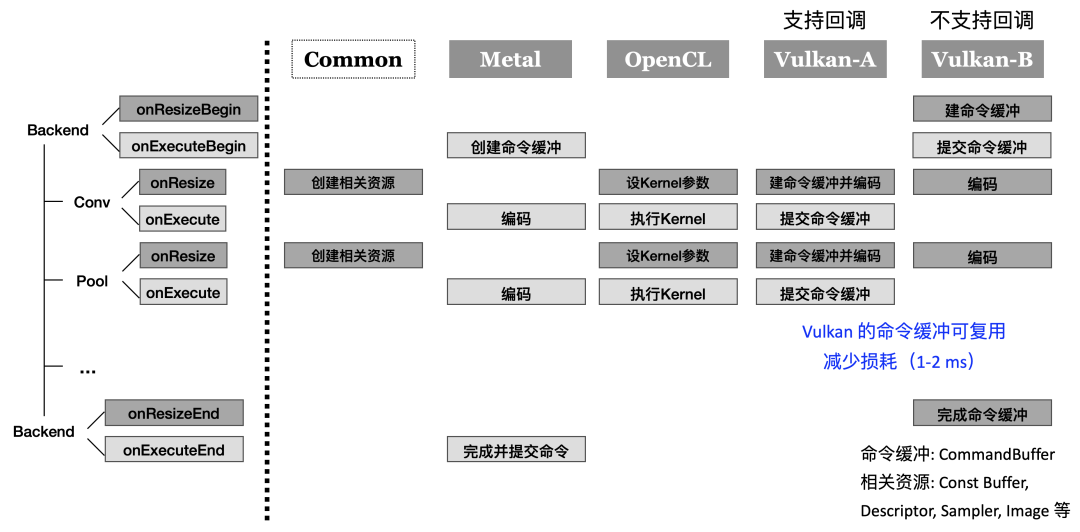
对于 OpenCL ,可以减少 Kernel 参数的设定,将计算资源的申请转移到预推理过程中
对于 Metal ,可进一步降低命令提交频率
对于 Vulkan ,可进一步把命令缓冲的创建全部转移到预推理中,最小化调度冗余
易用性
MNN在针对端侧开发的特点,在具有高性能与轻量性的同时还具有针对算法人员非常友好的易用性。MNN提供的Python部分接口不仅具备MNN模型推理的基础能力,同时还提供了算法开发人员在前后处理中使用频率最高的基础库numpy与opencv的能力,用户在移动端仅使用MNN便可以完成全套算法的迁移与部署。
▐ MNN移动端Python
MNN的Python接口提供的能力如下:
MNN:提供模型加载,推理能力;
MNN.expr:提供MNN的基础计算能力,动态构图能力;
MNN.numpy:提供与numpy用法一致的部分numpy函数;
MNN.opencv:提供与cv2用法一致的部分opencv函数;
其中MNN与MNN.expr为MNN的核心能力;MNN.numpy和MNN.opencv是基于MNN的核心能力进行的扩展功能,在用法上更加贴近算法常用库,在实现上复用MNN核心功能;低成本(200K内)大幅降低算法部署难度。
▐ 算法部署实例
使用以上能力可以将服务端代码便捷的迁移到移动端而不依赖其他Python库,代码如下:
import MNN
import MNN.cv as cv2
import MNN.numpy as np
def inference(model_path, img_path):
net = MNN.nn.load_module_from_file(model_path, ["data"], ["prob"])
image = cv2.imread(img_path)
image = image[..., ::-1]
image = cv2.resize(image, (224, 224))
image = image - (103.94, 116.78, 123.68)
image = image * (0.017, 0.017, 0.017)
image = image.astype(np.float32)
input_var = MNN.expr.convert(image, MNN.expr.NC4HW4)
output_var = net.forward(input_var)
output_var = MNN.expr.convert(output_var, MNN.expr.NHWC)
print("output belong to class: {}".format(np.argmax(output_var)))在移动端能够仅使用MNN便可以无缝部署服务端的算法,Python化部署对于算法工程师具有非常高的易用性,同时还具有更好的动态性,方便算法的热更新,热修复等;降低了端侧算法部署门坎,提升了端侧算法部署的效率。
总结与展望
MNN 通过独特的架构设计,结合各类性能优化的工作,解决了业务场景下深度学习部署的问题。后续也将持续努力,优化架构,改良算法,不断降低算法工程师AI部署的门槛,持续为各类业务带来增量价值。
参考资料
https://github.com/alibaba/MNN
https://arxiv.org/pdf/2002.12418.pdf
https://arxiv.org/abs/2205.14833
https://www.yuque.com/mnn/cn
https://www.khronos.org/assets/uploads/developers/presentations/Alibaba-Xiaying_geometry_outside_Apr21.pdf
https://www.tensorflow.org/guide/tf_numpy
https://numpy.org/
https://docs.opencv.org/4.x/d0/d1e/gapi.html
https://www.tensorflow.org/xla
团队介绍
大淘宝技术Meta Team,负责面向消费场景的3D/XR基础技术建设和创新应用探索,通过技术和应用创新找到以手机及XR 新设备为载体的消费购物3D/XR新体验。团队在端智能、商品三维重建、3D引擎、XR引擎等方面有深厚的技术积累。先后发布端侧推理引擎MNN,端侧实时视觉算法库PixelAI,商品三维重建工具Object Drawer等技术。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。
✿ 拓展阅读

作者|霞影(姜霄棠)
编辑|橙子君


更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)