
NLP语义技术演进:从DP依存句法到SDP依存语义再到AMR抽象语义分析概述与开源实现...
每天给你送来NLP技术干货!作者:刘焕勇来自:老刘说NLP在上一篇文章《事件Schema生成必读:一种基于AMR与聚类、映射的事件模式生成框架浅析》中,我们讲到了AMR以及依存句法分析在分析触发词与论元之间的关系时所发挥的作用。当前,语义分析正在从浅层分析到深层分析转变,与此对应的语义分析技术也逐步发生变化,从最开始到句子成分分析,到依存句法分析,到语义角色标注再到依存语...
每天给你送来NLP技术干货!
作者:刘焕勇
来自:老刘说NLP
在上一篇文章《事件Schema生成必读:一种基于AMR与聚类、映射的事件模式生成框架浅析》中,我们讲到了AMR以及依存句法分析在分析触发词与论元之间的关系时所发挥的作用。
当前,语义分析正在从浅层分析到深层分析转变,与此对应的语义分析技术也逐步发生变化,从最开始到句子成分分析,到依存句法分析,到语义角色标注再到依存语义分析,再到抽象语义表示,整个过程也是十分有趣。
本文主要就这几种语义分析方式进行介绍,从基本概念、常用标记以及开源实现三个角度进行介绍,供大家一起思考。 本文充分借鉴了LTP以及Hanlp的一些介绍和相关结果图片,对这两个机构的开源精神表示感谢。
一、依存句法分析Dependency Parsing
依存语法 (Dependency Parsing, DP) 通过分析语言单位内成分之间的依存关系揭示其句法结构,通过分析,可以看到词语之间的依存关系,如SBV主语关系,VOB动宾关系,ATT修饰关系,利用该关系可以进行搭配抽取、短语组块识别,事件抽取等任务。
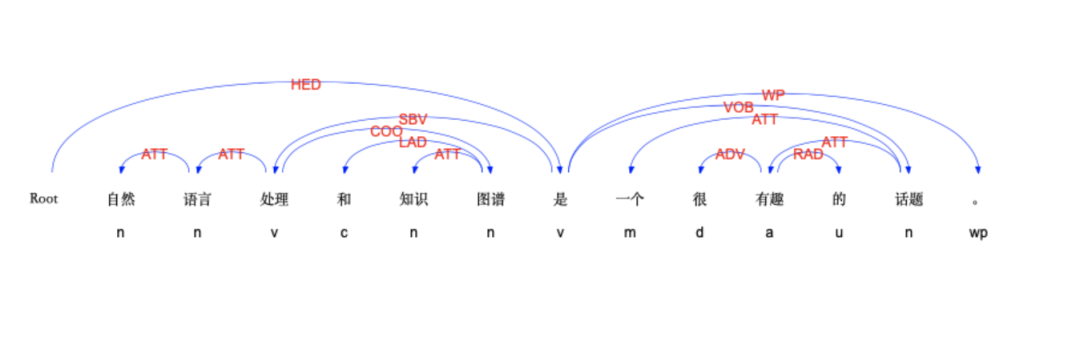
图-LTP依存分析结果

图-hanlP依存分析结果
直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
1、常用标记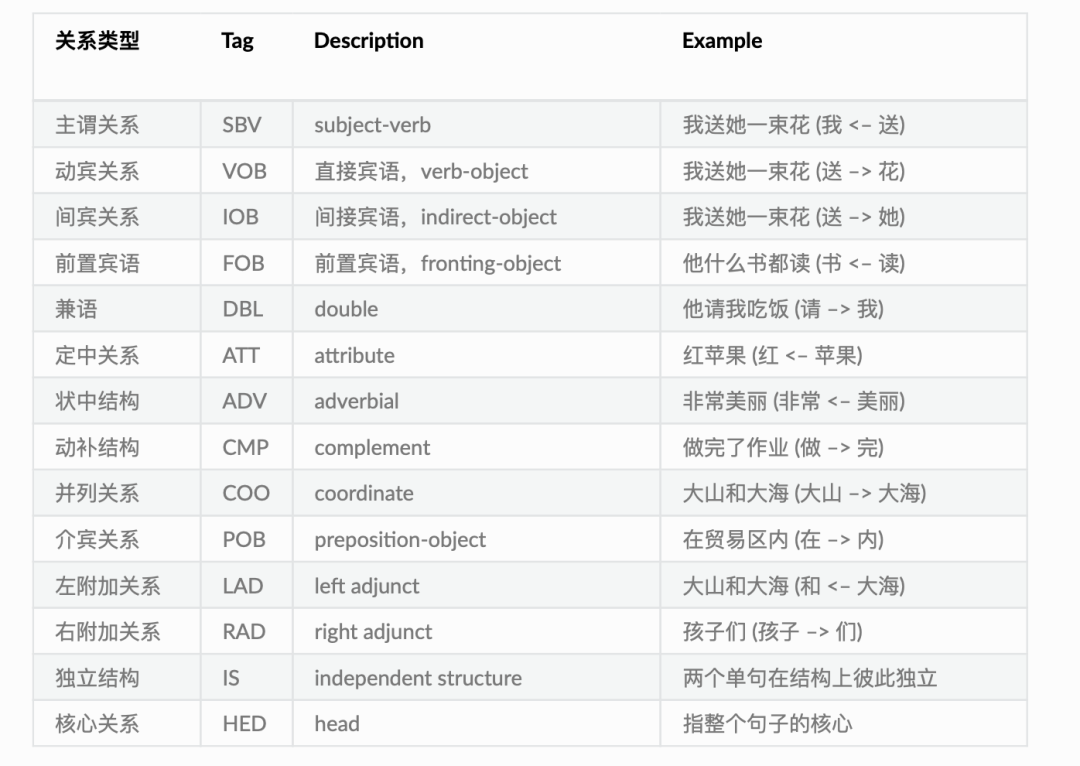
2、开源实现
from ltp import LTP
ltp = LTP()
seg, hidden = ltp.seg(["他叫汤姆去拿外衣。"])
dep = ltp.dep(hidden)
[['他', '叫', '汤姆', '去', '拿', '外衣', '。']]
[
[
(1, 2, 'SBV'),
(2, 0, 'HED'), # 叫 --|HED|--> ROOT
(3, 2, 'DBL'),
(4, 2, 'VOB'),
(5, 4, 'COO'),
(6, 5, 'VOB'),
(7, 2, 'WP')
]
]二、语义角色标注 Semantic Role Labeling
语义角色标注(Semantic Role Labeling,简称 SRL)是一种浅层的语义分析,在给定一个句子, SRL 的任务是找出句子中谓词的相应语义角色成分,包括核心语义角色(如施事者、受事者等)和附属语义角色(如地点、时间、方式、原因等)。
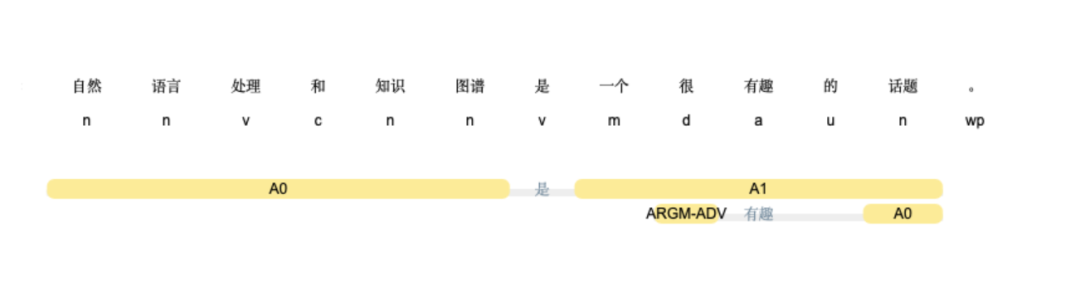
图-LTP语义角色分析结果
1、常用标记
2、具体例子
from ltp import LTP
ltp = LTP()
seg, hidden = ltp.seg(["他叫汤姆去拿外衣。"])
srl = ltp.srl(hidden)
[['他', '叫', '汤姆', '去', '拿', '外衣', '。']]
[
[
[], # 他
[('ARG0', 0, 0), ('ARG1', 2, 2), ('ARG2', 3, 5)], # 叫 -> [ARG0: 他, ARG1: 汤姆, ARG2: 去拿外衣]
[], # 汤姆
[], # 去
[('ARG0', 2, 2), ('ARG1', 5, 5)],# 拿 -> [ARG0: 汤姆, ARG1: 外衣]
[], # 外衣
[] # 。
]
]
srl = ltp.srl(hidden, keep_empty=False)
[
[
(1, [('ARG0', 0, 0), ('ARG1', 2, 2), ('ARG2', 3, 5)]), # 叫 -> [ARG0: 他, ARG1: 汤姆, ARG2: 去拿外衣]
(4, [('ARG0', 2, 2), ('ARG1', 5, 5)]) # 拿 -> [ARG0: 汤姆, ARG1: 外衣]三、语义依存分析Semantic Dependency Parsing
语义依存分析 (Semantic Dependency Parsing, SDP),旨在分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现。与依存句法的SBV等依存标记不同,其更深入的标记出了词语所担任的角色信息。
使用语义依存刻画句子语义,好处在于不需要去抽象词汇本身,而是通过词汇所承受的语义框架来描述该词汇,而论元的数目相对词汇来说数量总是少了很多的。
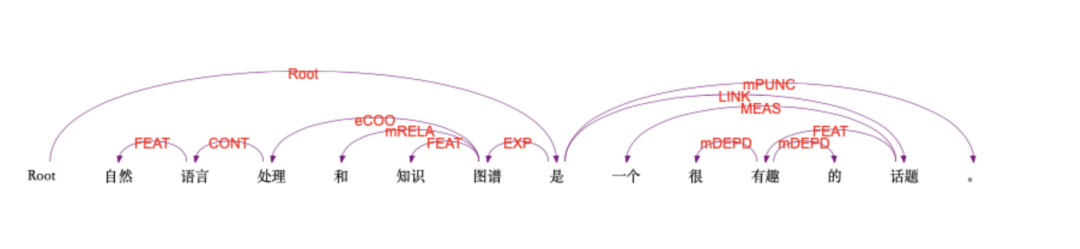
图-LTP语义依存分析结果
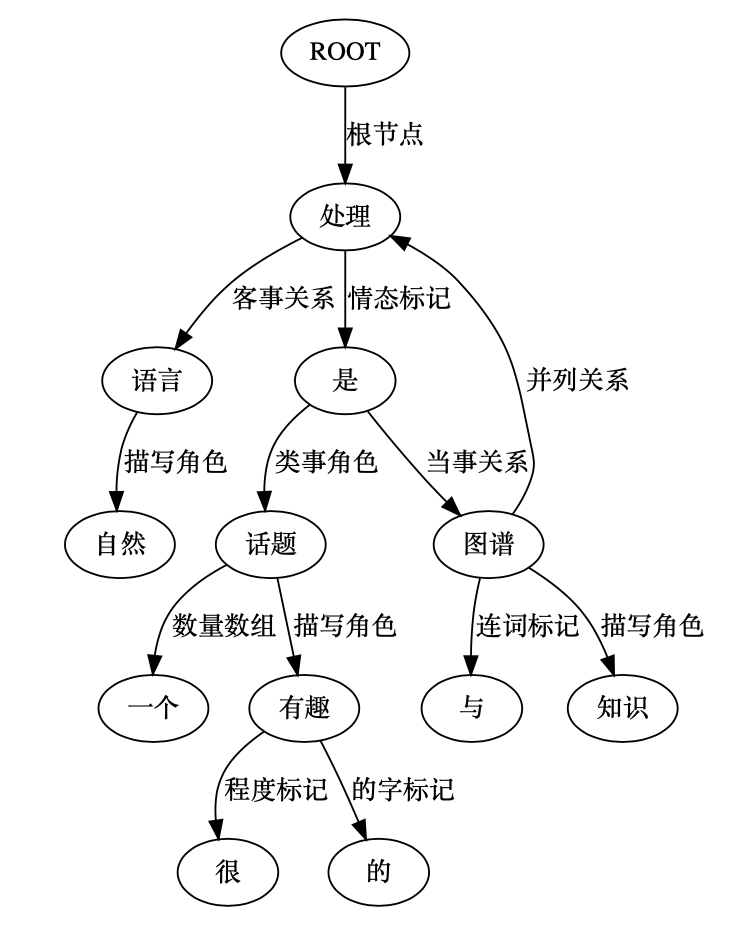
图-hanlP语义依存分析结果
语义依存分析目标是跨越句子表层句法结构的束缚,直接获取深层的语义信息。
1、常用标记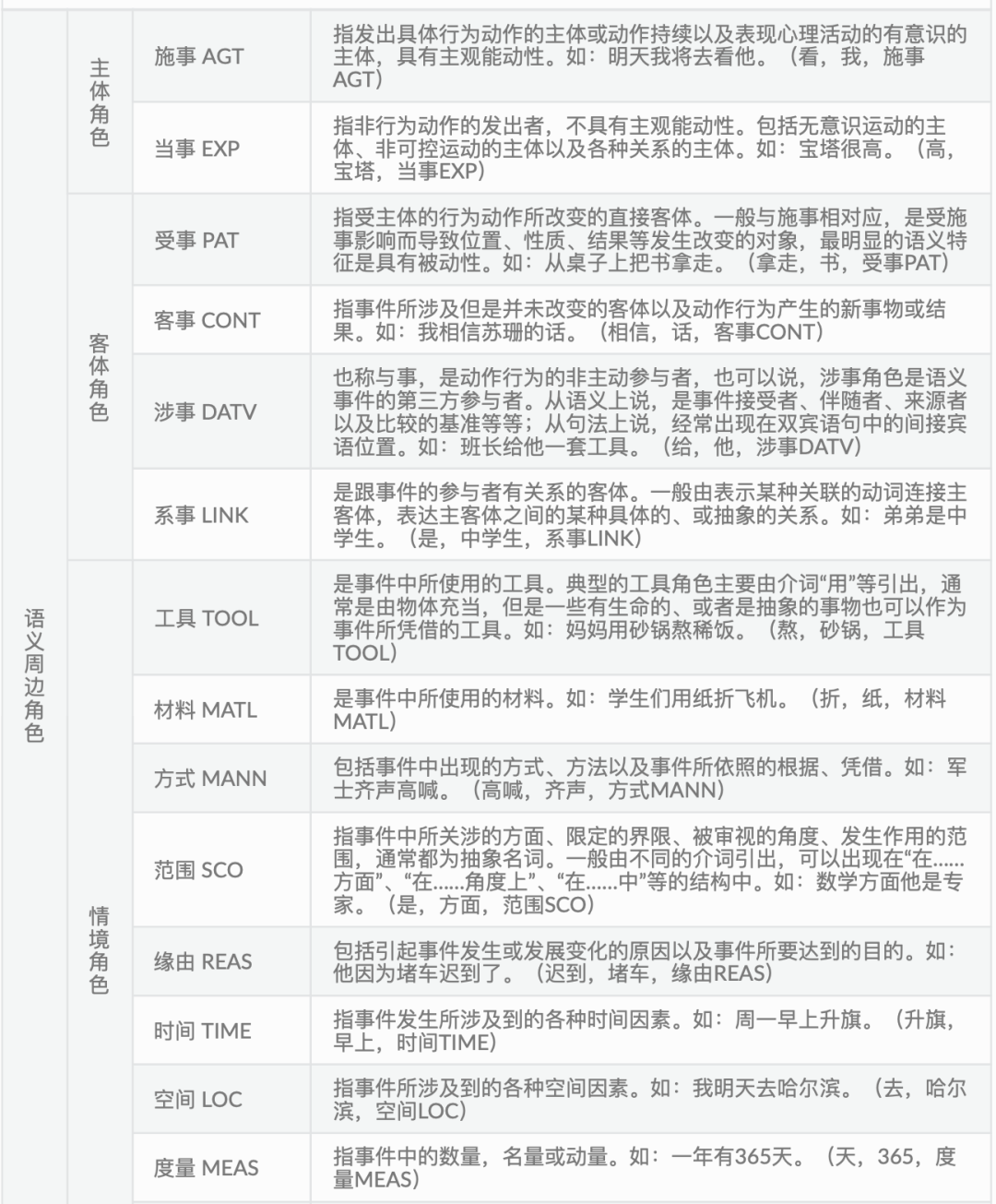
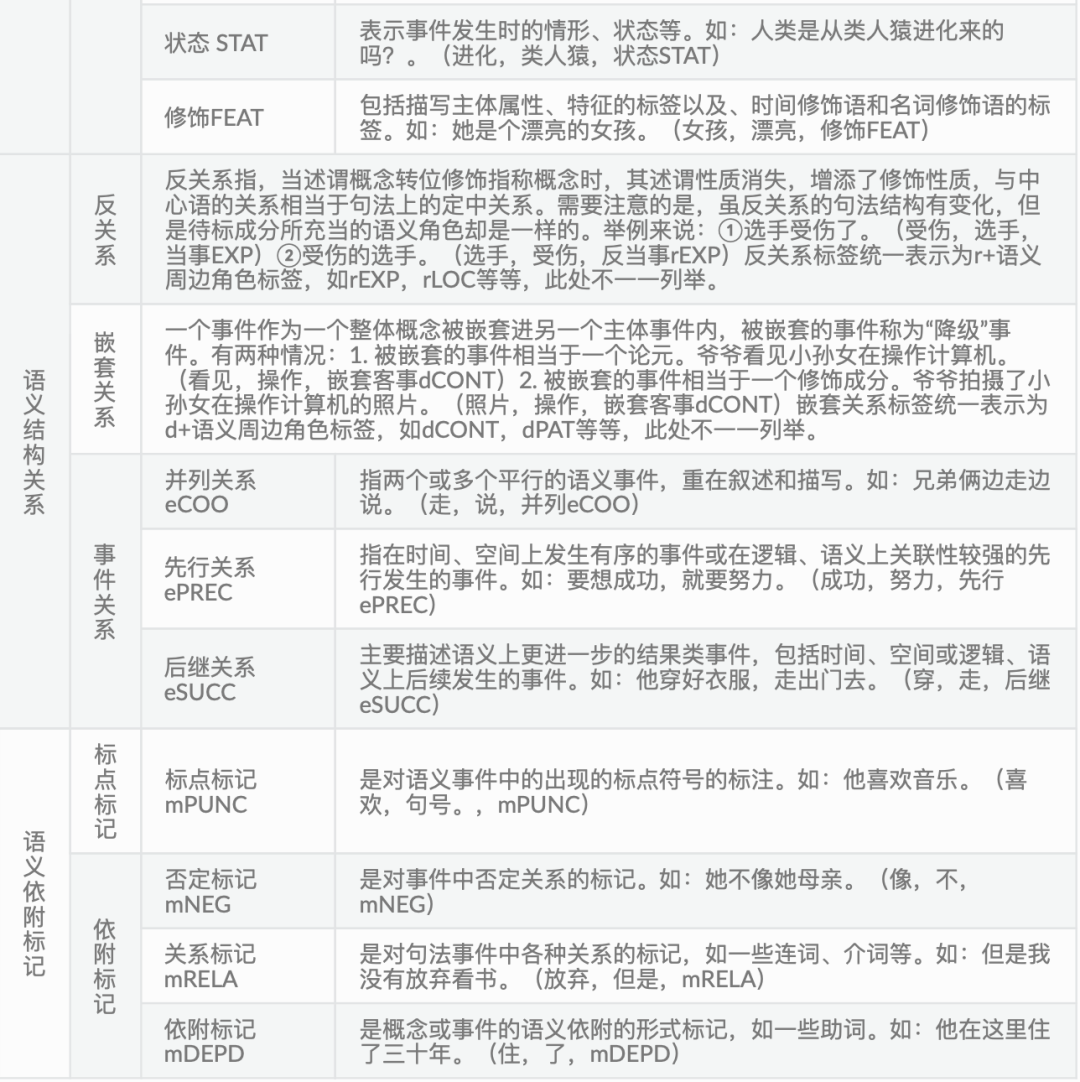
2、开源实现
from ltp import LTP
ltp = LTP()
seg, hidden = ltp.seg(["他叫汤姆去拿外衣。"])
sdp = ltp.sdp(hidden, mode='tree')
[['他', '叫', '汤姆', '去', '拿', '外衣', '。']]
[
[
(1, 2, 'Agt'),
(2, 0, 'Root'), # 叫 --|Root|--> ROOT
(3, 2, 'Datv'),
(4, 2, 'eEfft'),
(5, 4, 'eEfft'),
(6, 5, 'Pat'),
(7, 2, 'mPunc')
]
]四、抽象语义表示Abstract Meaning representation
抽象语义表示(abstract meaning representation,AMR)是句子语义的一种表示方法,将一个句子的语义抽象为一个单根有向无环图。
AMR解析旨在将句子解析为对应的AMR图,句子中的实词抽象为概念节点,实词之间的关系抽象为带有语义关系标签的有向弧,同时忽略虚词和形态变化体现的较虚的语义(如the、单复数、时、体等等)。
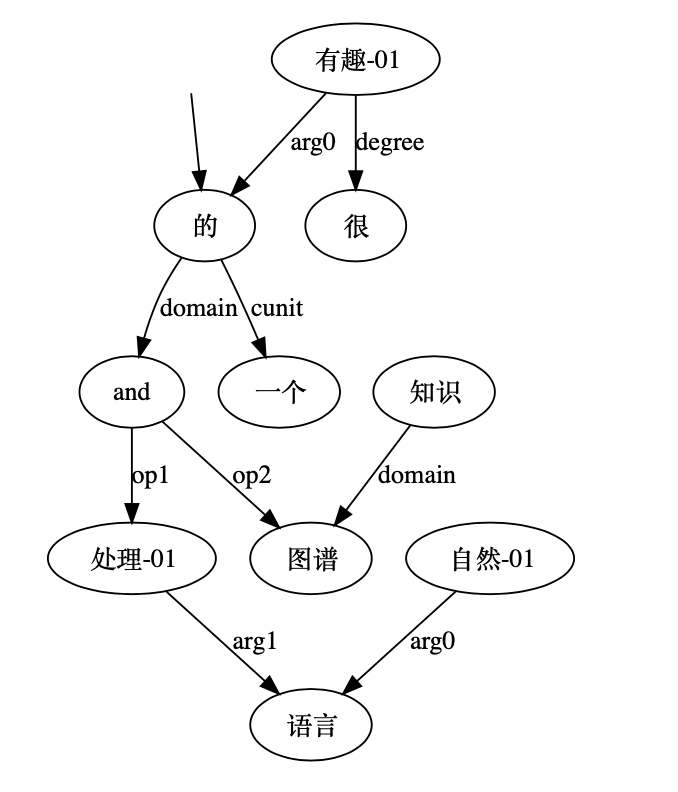
图-hanlP语义依存分析结果
文章《中文抽象意义表示简介》(https://www.hankcs.com/nlp/corpus/introduction-to-chinese-abstract-meaning-representation.html) 中对AMR的优势这么说:
与依存句法树相比,抽象意义表示图中的节点不再是单词而是概念,并且跳出了树的限制;
与语义依存图相比,抽象意义表示图不但跳出了单词的限制,而且还可以自由引入句子表面不存在的概念;
与单词颗粒度的句法语义表示形式相比,抽象意义表示既可以将多个单词抽象为一个概念(命名实体),也可以引入句子表面原本不存在的概念(比如省略成分、维基链接等);
与语义角色标注相比,抽象意义表示保留了谓词和论元的概念,但不再依赖短语结构树,并且能够刻画多个谓词之间的层级关系,而语义角色标注只能提供扁平的结构。
1、常用标记
在概念上,AMR一般将句中的实词都抽象为概念,如名词、动词、形容词、副词,而且一般会使用词语本身作为标签来表示这些概念,因此AMR中大部分的概念都是由句中的词语充当的,为方便理解和说明,有时可以直接用词语来指代概念。
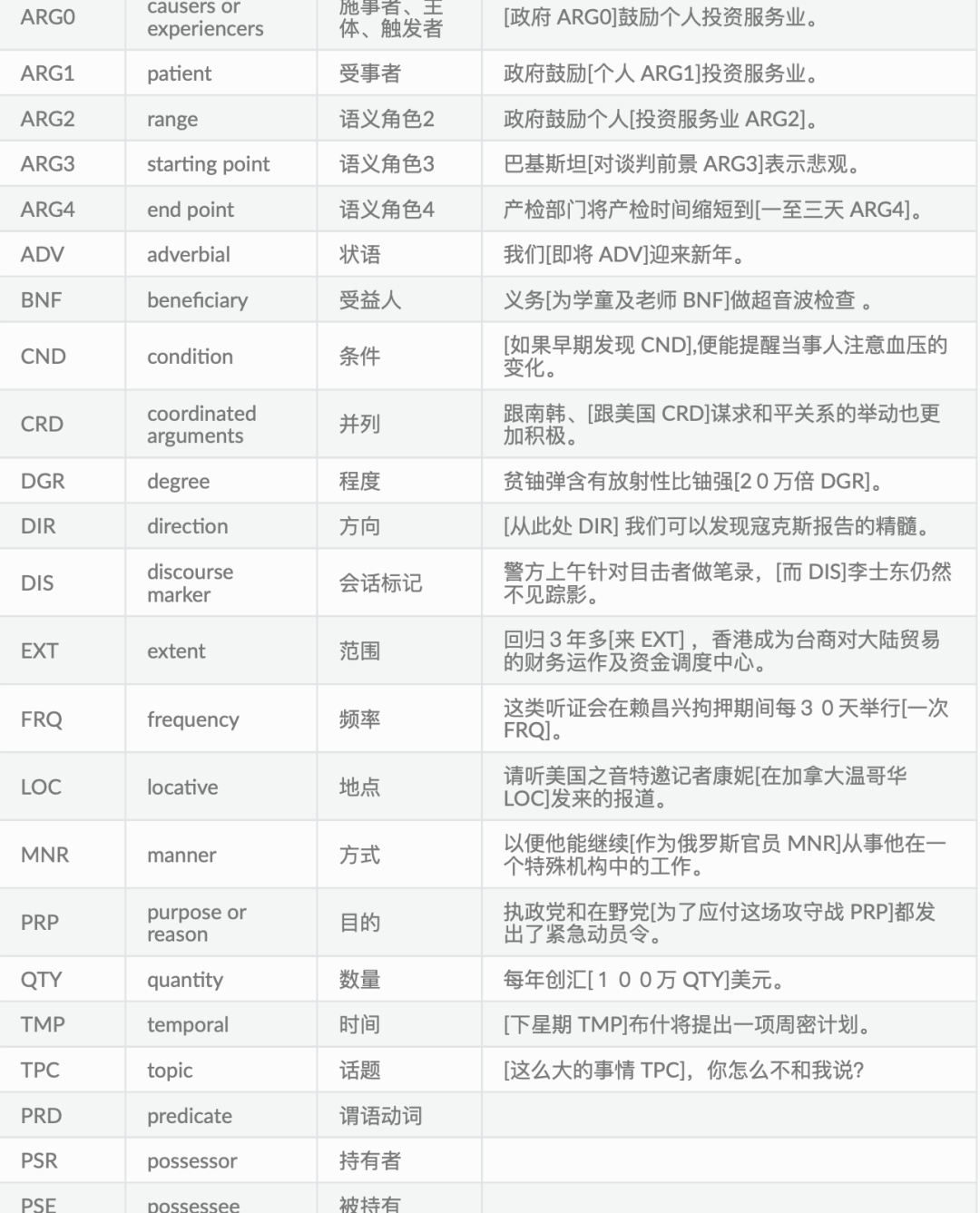
在关系上,语义关系分为两种,核心语义角色关系和非核心语义角色关系。用形如 “Argx(x∈[0,4])”的标签来表示核心语义角色关系,用形如“cost(花费)”等的语义标 签来表示非核心的语义角色关系。
核心语义关系,沿用 OntoNotes 的体系,共5个,即:ARG0(原型施事)、ARG1(原 型受事)、ARG2(间接宾语、工具等)、ARG3(出发点、受益者等)、ARG4(终点);
非核心语义关系表示除核心语义之外的关系类型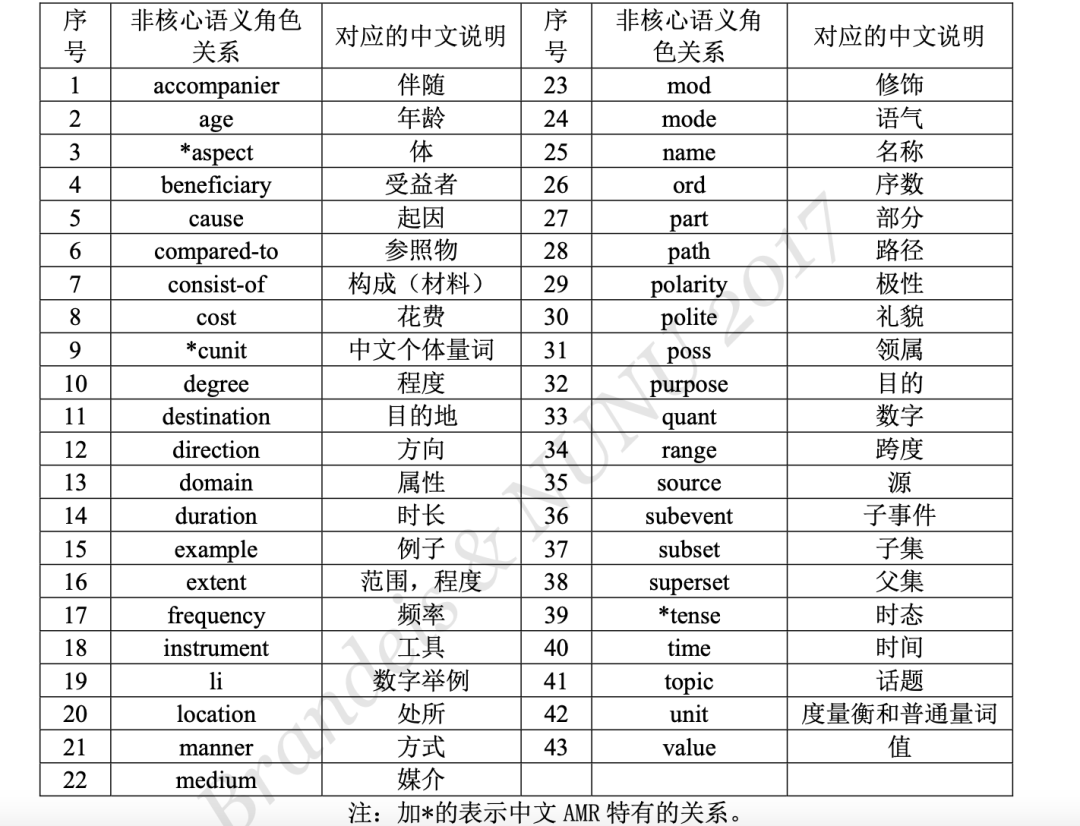
更详细的标记,可以参考:《中文抽象语义表示标注规范V1.2》,地址:https://www.cs.brandeis.edu/~clp/camr/res/CAMR_GL_v1.2.pdf。
2、开源实现
import hanlp
hanlp.pretrained.amr.ALL # 语种见名称最后一个字段或相应语料库
amr = hanlp.load('MRP2020_AMR_ENG_ZHO_XLM_BASE')
graph = amr(["男孩", "希望", "女孩", "相信", "他", "。"])
print(graph)
(x2 / 希望-01
:arg1 (x4 / 相信-01
:arg0 (x3 / 女孩)
:arg1 x1)
:arg0 (x1 / 男孩))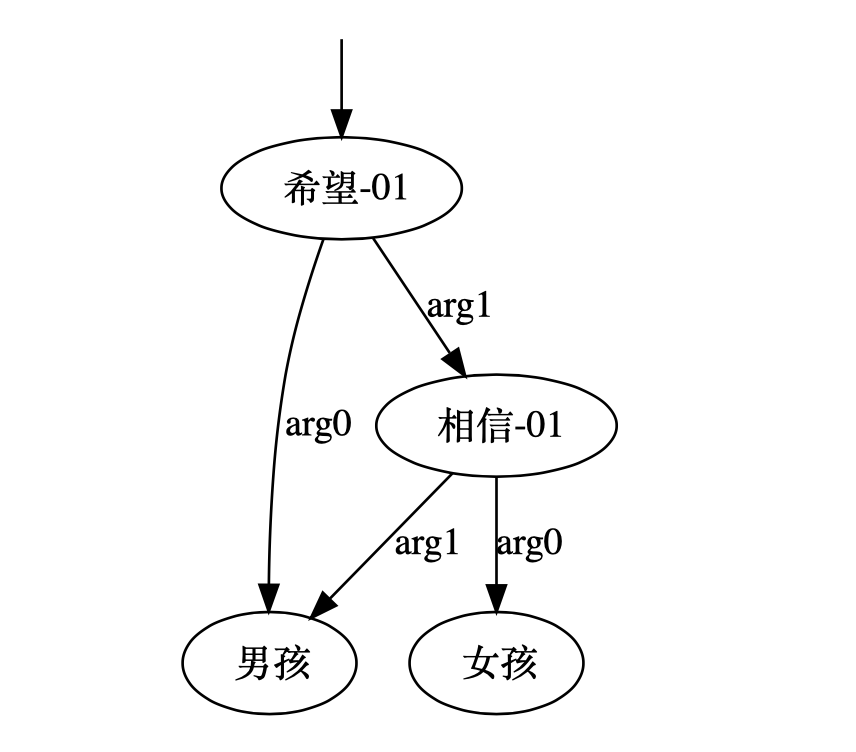
amr(["男孩", "希望", "女孩", "相信", "他", "。"], output_amr=False)
Out[6]:
{'id': '0',
'input': '男孩 希望 女孩 相信 他 。',
'nodes': [{'id': 0,
'label': '男孩',
'anchors': [{'from': 0, 'to': 2}, {'from': 12, 'to': 13}]},
{'id': 1, 'label': '希望-01', 'anchors': [{'from': 3, 'to': 5}]},
{'id': 2, 'label': '女孩', 'anchors': [{'from': 6, 'to': 8}]},
{'id': 3, 'label': '相信-01', 'anchors': [{'from': 9, 'to': 11}]}],
'edges': [{'source': 1, 'target': 3, 'label': 'arg1'},
{'source': 1, 'target': 0, 'label': 'arg0'},
{'source': 3, 'target': 2, 'label': 'arg0'},
{'source': 3, 'target': 0, 'label': 'arg1'}],
'tops': [1],
'framework': 'amr'}总结
本文主要本文从基本概念、常用标记以及开源实现三个角度对依存句法分析Dependency Parsing、语义角色标注 Semantic Role Labeling、语义依存分析Semantic Dependency Parsing以及抽象语义表示Abstract Meaning representation几个句法/语义分析方法进行了介绍。
当前,AMR最为火热,当然批评的声音也不少,大家可以多加实践,并具体的任务和业务相结合,解决更多落地问题。
参考文献
1、https://wap.sciencenet.cn/blog-39714-1069586.html
2、https://amr.isi.edu/download.html
3、https://hanlp.hankcs.com/
4、https://github.com/hankcs/HanLP/tree/doc-zh
5、https://blog.51cto.com/u_11142243/2418415
6、http://ltp.ai
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 6
6 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)