
【python + opencv + pytorch】车牌提取、分割、识别 pro版
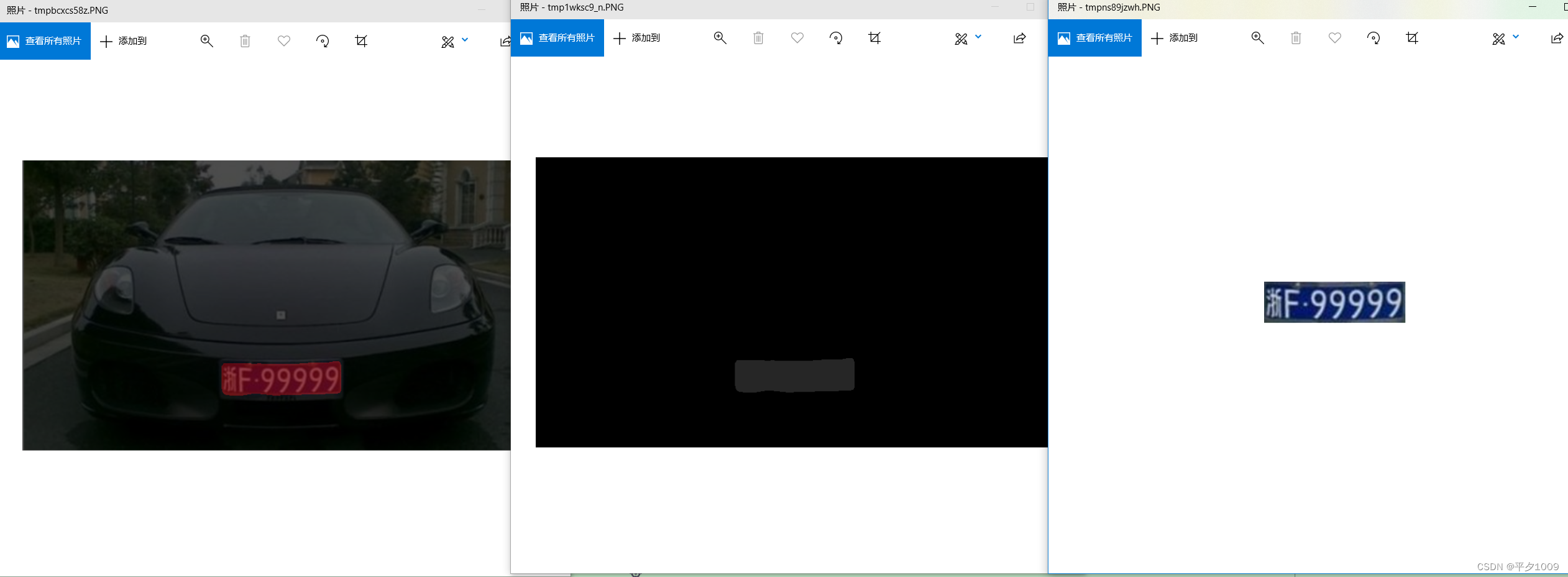
老规矩,先看最后成果图(如果想要全部工程,文章最后我会把github链接放上):1、分割车牌2、分割字符3、识别字符最终识别的车牌号码是:浙F99999整个车牌识别分五步:1、一个分割车牌的语义分割模型2、用训练好DeepLab V3+模型将车牌从图片里面抠出来3、将车牌字符一个个分割开4、训练一个预训练模型来识别单个车牌字符5、用训练好的预训练模型去识别分割好的字符从而得到车牌号第一步:训练分割
老规矩,先看最后成果图(如果想要全部工程,文章最后我会把github链接放上)
1、分割车牌

2、分割字符

3、识别字符

最终识别的车牌号码是:浙F99999
整个车牌识别分五步:
1、一个分割车牌的语义分割模型
2、用训练好DeepLab V3+模型将车牌从图片里面抠出来
3、将车牌字符一个个分割开
4、训练一个预训练模型来识别单个车牌字符
5、用训练好的预训练模型去识别分割好的字符从而得到车牌号
第一步:训练分割车牌的语义分割模型
我这里用的是Bubbliiiing大佬用pytorch写好的DeepLabV3+框架,框架原博传送门:Pytorch 搭建自己的DeeplabV3+语义分割平台
首先我用labelme工具制作了标定好的车牌数据集

制作好数据集,然后开始训练

第二步:用训练好的DeepLab V3+模型抠车牌
训练完之后就开始识别车牌位置,我在DeepLabV3+原框架的基础上将车车牌区域抠了出来,当然这中间有假阳性点,我自己写了个算法,去除假阳性点,准确的将车牌区域抠出来
# add by pingxi 2022-5-2
# 用于将车牌提取出来
plate_img = image.convert('L')
print("shape = ", plate_img.size)
plate_img.show()
_, plate_img = cv2.threshold(np.asarray(plate_img), 20, 255, cv2.THRESH_BINARY) # 二值化
rect = clear_min_area.Clear_Micor_Areas(plate_img) # 寻找车牌车牌所在的矩形
print("match rect is:",rect)
img_plate = old_img.crop((rect[0], rect[1], rect[0] + rect[2], rect[1] + rect[3])) # 根据车牌所在的矩形,切割出车牌
img_plate.show()
img_plate.save('plate.jpg') # 保存车牌图片
# add by pingxi
def Clear_Micor_Areas(img):
print(img.shape)
conyours, h = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
print("count = ",len(conyours))
# for index in range(len(conyours)):
# area = cv2.contourArea(conyours[index])
# print(area)
kernel_X = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 1)) # 定义矩形卷积核
mark = cv2.dilate(img, kernel_X, (-1, -1), iterations=1) # 横向膨胀操作
# cv2.imshow('erode', mark)
kernel_Y = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 2)) # 定义矩形卷积核
mark = cv2.dilate(mark, kernel_Y, (-1, -1), iterations=1) # 纵向膨胀操作
# cv2.imshow('erode', mark)
conyours, h = cv2.findContours(mark, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
print("count = ", len(conyours))
maxAreaRect = 0
rect = cv2.boundingRect(conyours[0])
for jndex in range(len(conyours)):
area = cv2.contourArea(conyours[jndex])
rect = cv2.boundingRect(conyours[jndex])
print(rect)
curRectArea = rect[2]*rect[3]
maxAreaRect = maxAreaRect if maxAreaRect > curRectArea else curRectArea # 将面积最大的矩形取出
print("maxarea = ",maxAreaRect)
cv2.waitKey(0)
return rect # 返回最大的矩形,即车牌所在的矩形
开始识别

用DeeplabV3+抠出的车牌比我之前用opencv抠出来的效果好很多,之前opencv识别的时候很容易引入很多噪点,对后面的字符分割和识别影响很大,现在用语义分割处理之后,基本不会引入多余的噪点,这一步很关键,对后面的字符分割和字符识别提供了良好的基础。
第三步:分割字符
分割字符,之前用的是投影法来分割字符,投影法:分垂直投影法也水平投影法,水平投影法就是根据每一行白点数。这种方法分割车牌能处理,但是效果一般,因为只要车牌引入一点点噪点,就对后面的的分割影响很大,所以我在投影法的基础上加以改进,具体改进的方法是:根据车牌的规格,按比例来分割车牌,我们只要抓住第一个字符左边的位置和最后一个字符右边的位置,然后中键车牌的分布都是按照比例分布的,通过这个方法很容易定位到车牌上每个字符出现和结束的位置,从而分割车牌。


然后分割好车牌之后别忘了将分割好的字符resize成32*40的规格。
第四步:训练识别车牌字符的预训练模型
训练CNN模型识别分割好的字符,之前用的是自己搭建的一个CNN模型,比较简单,单个字符准确率在91%左右,但是由于每张车牌有七个字符,这样整体准确率就只有0.91^7即51.7%,实际识别效果也是总有某一个字符识别错误,后来我用预训练模型,在VGG16模型的基础上,修改最后的fc层,最后训练的效果出奇的好,在测试集的准确率达到99%甚至100%!!!这也是为什么我题目说准确率高达99%。当然,我训练的数据总共有 0-9 的数字 还有 A-Z 除去‘I’和’‘O’的 24 个大写英文字母 还有 6个省的缩写,本身数据集不够完善,如果有其他省份缩写数据集的兄弟希望可以发我邮箱,感激不尽。

# 方法一:增减卷积 要修改网络中的层次结构,这时只能用参数覆盖的方法,即自己先定义一个类似的网络,再将预训练中的参数提取到自己的网络中来
class Net(torch.nn.Module):
def __init__(self, num_classes=40):
super(Net, self).__init__()
# pretrained=True 加载网络结构和预训练参数,
# pretrained=False 时代表只加载网络结构,不加载预训练参数,即不需要用预训练模型的参数来初始化
# pretrained 参数默认是False,为了代码清晰,最好还是加上参数赋值
net = models.vgg16(pretrained=True)
# net = models.mnist(pretrained=True)
net.classifier = torch.nn.Sequential() # 将分类层(fc)置空
self.features = net
self.classifier = torch.nn.Sequential( # 定义一个卷积网络结构
torch.nn.Linear(512*7*7, 512),
torch.nn.ReLU(True),
torch.nn.Dropout(),
torch.nn.Linear(512, 128),
torch.nn.ReLU(True),
torch.nn.Dropout(),
torch.nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model = Net()
第五步:用训练的模型识别车牌字符图片得到车牌号
得到训练好的字符识别模型之后,就可以开始最后一步字符识别了,实际识别的准确度很高。
def test():
correct = 0
total = 0
with torch.no_grad():
for _, data in enumerate(new_test_loader, 0):
inputs, _ = data[0], data[1]
inputs = inputs.to(device)
outputs = model(inputs)
# print(outputs.shape)
_, prediction = torch.max(outputs.data, dim=1)
print('-'*40)
# print(target)
# print(prediction)
print(f'Predicted license plate number:'
f'{SINGLE_CHAR_LIST[prediction[0]]}'
f'{SINGLE_CHAR_LIST[prediction[1]]}'
f'{SINGLE_CHAR_LIST[prediction[2]]}'
f'{SINGLE_CHAR_LIST[prediction[3]]}'
f'{SINGLE_CHAR_LIST[prediction[4]]}'
f'{SINGLE_CHAR_LIST[prediction[5]]}'
f'{SINGLE_CHAR_LIST[prediction[6]]}')

项目工程实际操作:
1、运行train.py开始训练语义分割模型分割车牌,训练时间有点久,耐心等待训练完成,训练好的模型存放在logs文件夹中,训练好之后,需要从logs文件夹中取效果最好的模型拷贝到model_data文件夹下,改名为deeplab_mobilenetv2.pth(也可跳过这一步,我github工程上在model_data文件夹下有我训练好的模型,可以直接用)
2、运行predict.py开始分割车牌,如下图,输入工程目录下的图片名字(你也可以添加自己的车牌图片)按回车即可分割车牌,分割好之后按‘q’退出

3、运行cut_plate.py分割车牌
4、运行resize.py将分割好的字符图片统一格式
5、运行chartrain.py开始训练字符识别的预训练模型,训练时间有点久,耐心等待训练完成(这一步也可跳过,不想训练的,在工程目录下有个Model.7z压缩包,存放的就是我训练好的模型(准确率99%),将这个压缩包解压到工程目录下即可)
6、运行chartest.py识别分割好的字符图片
到此整个车牌识别就完成了。
注意点:
1、本身抠玩车牌之后没有做畸形矫正,所以用来识别的车牌图片最好是正对着车牌的图片如我工程中的test2.jpg test3.jpg等
2、整个识别项目性能一般,所以可能识别会有一点点慢,但是个人尚可接受
3、字符识别模型训练的时候我只有6个省(‘京’, ‘闽’, ‘粤’,‘苏’, ‘沪’, ‘浙’)的数据集,所以训练出来的模型只能识别这6个省的车牌,其他省的车牌省简称会识别错
以上就是我整个车牌识别的过程,这里我只贴出了一些关键步骤的代码,如需要整个工程,可去GitHub取,工程里面只有代码,自己想复现的话,给我发邮件1009088103@qq.com,注明:想要抠车牌语义分割数据集和省份字符数据集。
参考文章:
憨批的语义分割重制版9——Pytorch 搭建自己的DeeplabV3+语义分割平台
B站刘老师的《PyTorch深度学习实践》完结合集
工程github:github链接(帮忙点个星,谢谢啦)
后记:
去年四月的时候写过一篇车牌识别的文章,本来只是个萌新小白,发到CSDN只是想记录一下自己的学习过程,没想到这一年过去了,这篇文章每天仍然还有几十的阅读量,基本每天都会有人发邮件来问我要训练字符识别的数据集,受宠若惊,其实本身项目的质量其实并不高,换张图基本就分割不出单个字符了,泛化能力基本没有,当然其实这个问题我早就知道的,主要局限于我写的抠车牌和分割字符的算法太烂,很容易分割不出车牌,也很容易引入其他噪点,搭建的CNN模型训练的时候准确率虽然有91%,但是连续7个字符都要准确的话,准确率只有50%左右,当时自己在评论里说可能用YOLO V3目标检测算法来抠车牌的话,效果可能会好点,后来考虑到,车辆图片可能会有角度问题,到时候你用矩形去抠一个平行四边形,难免会引入很多噪点不好处理,后面想了一下,也许用语义分割来做效果会更好,不会过多的引入其他噪点,然后就用了Deeplab V3+语义分割框架来实现抠车牌,自己制作了相关数据集,然后训练了一下,效果出乎我的意料,识别非常准确,后面又趁着五一假期,花了两天时间完善了字符分割的算法和最后字符识别的模型,这次字符识别的模式是采用预训练模型,最后效果出奇的好,测试集的准确率高达99%甚至100%,有点夸张。也总算基本完成了这个小项目,我自己也没想到直接拖了一年才搞完,之前也是太忙了,再加上自己拖延症后期,幸得某位嗜睡兄台三天两头催更,才在五一假期完成整个项目,在此谢过。后续的话,应该会用qt写个界面,在再水一篇,这样的话最起码看起来没这么简陋,操作这么复杂,还有就是车牌畸形矫正,虽然已经有了思路,后面有时间再搞吧…
还有最后还有个不情之请,虽然不是很在乎粉丝数量和文章的赞和收藏,但是看到陌生网友给我点个赞和收藏,或者github上给我点个星,个人感觉还是蛮好的,所以如果觉得这个文章对你有帮助,请不要吝惜你的赞和收藏,这个对我虽然不是很重要,但是能让我小小的虚荣心得到满足,哈哈哈哈,如果对深度学习比较有兴趣的,可以点个关注,后续应该还会更新深度学习的小项目,当然也可以加我好友,一起探讨,共同进步…

音视频技术社区,一个全球开发者共同探讨、分享、学习音视频技术的平台,加入我们,与全球开发者一起创造更加优秀的音视频产品!
更多推荐


 135
135 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)