机器学习(13)岭回归(线性回归的改进)
目录一、基础理论API二、岭回归:预测波士顿房价总代码一、基础理论岭回归:带有L2正则化的线性回归。(为了解决过拟合)对病态数据的拟合要强于最小二乘法()APIsklearn.linear_model.Ridge(横坐标:正则化力度;纵坐标:权重系数)二、岭回归:预测波士顿房价# 3、岭回归def Linear3():# 1、获取数据集boston = load_boston()...
·
目录
一、基础理论
岭回归:带有L2正则化的线性回归。(为了解决过拟合)
对病态数据的拟合要强于最小二乘法
API
sklearn.linear_model.Ridge 
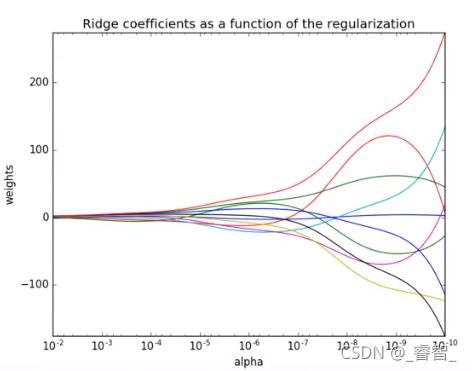
(横坐标:正则化力度; 纵坐标:权重系数)
二、岭回归:预测波士顿房价
# 3、岭回归
def Linear3():
# 1、获取数据集
boston = load_boston()
# print(boston)
# 2、划分数据集
train_data, test_data, train_target, test_target = train_test_split(boston.data, boston.target, random_state=22)
# print(train_data)
# 3、标准化
transfer = StandardScaler()
train_data = transfer.fit_transform(train_data)
test_data = transfer.transform(test_data)
# print(train_data)
# 4、创建预估器
estimator = Ridge() # 岭回归
estimator.fit(train_data, train_target) # 训练
# 得到模型
print('岭回归 权重系数:', estimator.coef_)
print('岭回归 偏置:', estimator.intercept_)
# 5、模型评估
predict = estimator.predict(test_data)
error = mean_squared_error(test_target, predict)
print('岭回归 均方差:', error)
总代码
# 线性回归:波士顿房价预测(正规方程,梯度下降,岭回归)
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor,Ridge
from sklearn.metrics import mean_squared_error
# 1、正规方程优化
def Linear1():
# 1、获取数据集
boston = load_boston()
# print(boston)
# 2、划分数据集
train_data, test_data, train_target, test_target = train_test_split(boston.data, boston.target, random_state=22)
# print(train_data)
# 3、标准化
transfer = StandardScaler()
train_data = transfer.fit_transform(train_data)
test_data = transfer.transform(test_data)
# print(train_data)
# 4、创建预估器,得到模型
estimator = LinearRegression() #正规方程优化
estimator.fit(train_data, train_target) #训练
# show
print('正规方程 权重系数:', estimator.coef_)
print('正规方程 偏置:', estimator.intercept_)
# 5、模型评估
predict = estimator.predict(test_data)
error = mean_squared_error(test_target, predict)
print('正规方程 均方差:', error)
# 2、梯度下降优化
def Linear2():
# 1、获取数据集
boston = load_boston()
# print(boston)
# 2、划分数据集
train_data, test_data, train_target, test_target = train_test_split(boston.data, boston.target, random_state=22)
# print(train_data)
# 3、标准化
transfer = StandardScaler()
train_data = transfer.fit_transform(train_data)
test_data = transfer.transform(test_data)
# print(train_data)
# 4、创建预估器
estimator = SGDRegressor() #梯度下降优化
estimator.fit(train_data, train_target) #训练
# 得到模型
print('梯度下降 权重系数:', estimator.coef_)
print('梯度下降 偏置:', estimator.intercept_)
# 5、模型评估
predict = estimator.predict(test_data)
error = mean_squared_error(test_target, predict)
print('梯度下降 均方差:', error)
# 3、岭回归
def Linear3():
# 1、获取数据集
boston = load_boston()
# print(boston)
# 2、划分数据集
train_data, test_data, train_target, test_target = train_test_split(boston.data, boston.target, random_state=22)
# print(train_data)
# 3、标准化
transfer = StandardScaler()
train_data = transfer.fit_transform(train_data)
test_data = transfer.transform(test_data)
# print(train_data)
# 4、创建预估器
estimator = Ridge() # 岭回归
estimator.fit(train_data, train_target) # 训练
# 得到模型
print('岭回归 权重系数:', estimator.coef_)
print('岭回归 偏置:', estimator.intercept_)
# 5、模型评估
predict = estimator.predict(test_data)
error = mean_squared_error(test_target, predict)
print('岭回归 均方差:', error)
if __name__ == '__main__':
Linear1() # 正规方程
Linear2() # 梯度下降
Linear3() # 岭回归
CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)