
一篇文章搞定大数据安装(Hadoop、zookeeper、Spark、HBase、Hive)———附带详细步
文章目录2 配置Hadoop2.1 配置免密登录2.1.1 生成密匙2.1.2 免密登录2.1.3 验证免密登录2.2 集群搭建2.2.1 下载并解压2.2.2 配置环境变量2.2.3 修改配置1. hadoop-env.sh2. core-site.xml3. hdfs-site.xml4. yarn-site.xml5.mapred-site.xml6. slaves2.3 初始化2.4 启动
1 配置java环境
1. 下载并解压
在官网 下载所需版本的 JDK,这里我下载的版本为JDK 1.8 。
这里使用已有安装包直接安装,进行解压:
[root@ java]# tar -zxvf jdk-8u201-linux-x64.tar.gz
把文件移到指定文件:
[root@ java]# sudo mkdir /usr/java
[root@ java]# sudo mv jdk1.8.0_192 /usr/java
2. 设置环境变量
[root@ java]# vi /etc/profile
添加如下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_192
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
执行 source 命令,使得配置立即生效:
[root@ java]# source /etc/profile
3. 检查是否安装成功
[root@ java]# java -version
显示出对应的版本信息则代表安装成功。
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
2 配置Hadoop
这里搭建一个 3 节点的 Hadoop 集群,其中三台主机均部署 DataNode 和 NodeManager 服务,但只有 hadoop001 上部署 NameNode 和 ResourceManager 服务。

2.1 配置免密登录
2.1.1 生成密匙
在每台主机上使用 ssh-keygen 命令生成公钥私钥对:
ssh-keygen
2.1.2 免密登录
将 hadoop001 【主机名/ip地址;推荐使用ip名】的公钥写到本机和远程机器的 ~/ .ssh/authorized_key 文件中:
ssh-copy-id -i ~/.ssh/id_rsa.pub 10.20.3.72
ssh-copy-id -i ~/.ssh/id_rsa.pub 10.20.3.73
ssh-copy-id -i ~/.ssh/id_rsa.pub 10.20.3.74
这里使用10.20.3.72作为hadoop001,使用10.20.3.73作为hadoop002,使用10.20.3.74作为hadoop003
2.1.3 验证免密登录
ssh 10.20.3.73
ssh 10.20.3.74
2.2 集群搭建
2.2.1 下载并解压
下载 Hadoop。这里我下载的是 CDH 版本 Hadoop,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/,这里使用直接下载好的安装包直接安装:
# tar -zvxf hadoop-2.10.1.tar.gz
拷贝到自己指定的目录:
mv hadoop-2.10.1 /usr/app/
2.2.2 配置环境变量
编辑 profile 文件:
# vim /etc/profile
增加如下配置(注意新建文件夹,并移动解压的文件):
export HADOOP_HOME=/usr/app/hadoop-2.10.1
export PATH=${HADOOP_HOME}/bin:$PATH
执行 source 命令,使得配置立即生效:
# source /etc/profile
2.2.3 修改配置
进入 ${HADOOP_HOME}/etc/hadoop 目录下,修改配置文件。各个配置文件内容如下:
1. hadoop-env.sh
# 指定JDK的安装位置
export JAVA_HOME=/usr/java/jdk1.8.0_192/
2. core-site.xml
<configuration>
<property>
<!--指定 namenode 的 hdfs 协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hdp-jk-1:8020</value>
</property>
<property>
<!--指定 hadoop 集群存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
下面代码的作用是指定 hadoop 的 root 用户可以代理本机上所有的用户,之所以要配置这一步,是因为 hadoop 2.0 以后引入了安全伪装机制,使得 hadoop 不允许上层系统(如 hive)直接将实际用户传递到 hadoop 层,而应该将实际用户传递给一个超级代理,由该代理在 hadoop 上执行操作,以避免任意客户端随意操作 hadoop。如果不配置这一步,在之后的连接中可能会抛出 AuthorizationException 异常。
关于 Hadoop 的用户代理机制,可以参考:hadoop 的用户代理机制 或 Superusers Acting On Behalf Of Other Users
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
3. hdfs-site.xml
<configuration>
<property>
<!--namenode 节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔-->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!--datanode 节点数据(即数据块)的存放位置-->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
4. yarn-site.xml
<configuration>
<property>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可以在 Yarn 上运行 MapReduce 程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--resourcemanager 的主机名-->
<name>yarn.resourcemanager.hostname</name>
<value>hdp-jk-1</value>
</property>
</configuration>
5. mapred-site.xml
<configuration>
<property>
<!--指定 mapreduce 作业运行在 yarn 上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6. slaves
配置所有从属节点的主机名或 IP 地址(一般选择ip),每行一个。所有从属节点上的 DataNode 服务和 NodeManager 服务都会被启动。
10.20.3.72
10.20.3.73
10.20.3.74
2.3 初始化
在 master机【10.20.3.72】 上执行 namenode 初始化命令:
hdfs namenode -format
2.4 启动集群
进入到master机【10.20.3.72】 的 ${HADOOP_HOME}/sbin 目录下,启动 Hadoop。此时 【10.20.3.73】 和 【10.20.3.74】上的相关服务也会被启动:
# 启动dfs服务
./start-dfs.sh
# 启动yarn服务
./start-yarn.sh
2.5 查看集群
在每台服务器上使用 jps 命令查看java服务进程。
主机:
# Jps
21488 ResourceManager
23296 DataNode
23656 NodeManager
22298 NameNode
22507 SecondaryNameNode
24973 Jps
集群:
# Jps
13090 DataNode
13943 Master
17498 Jps
或直接进入 Web-UI 界面进行查看,端口为 50070。可以看到此时有三个可用的 Datanode:

点击 Live Nodes 进入,可以看到每个 DataNode 的详细情况:

接着可以查看 Yarn 的情况,端口号为 8088 :

2.6 安装包
下载地址,密码:rste
参考:github项目
3 配置zookeeper
3.1 下载
下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/
# wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
这里使用直接下载的包,直接安装。
3.2 解压
# tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz
拷贝到自己指定的目录:
mv apache-zookeeper-3.5.9-bin /usr/app/
3.3 配置环境变量
配置环境变量
# vim /etc/profile
添加环境变量:
export ZOOKEEPER_HOME=/usr/app/apache-zookeeper-3.5.9-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH
使得配置的环境变量生效:
# source /etc/profile
3.4 修改zookeeper配置
进入zookeeper安装目录的 conf/ 目录下:
# cd /usr/app/apache-zookeeper-3.5.9-bin/conf/
拷贝配置样本并,并对zoo.cfg进行修改:
# cp zoo_sample.cfg zoo.cfg
指定数据存储目录和日志文件目录(目录不用预先创建,程序会自动创建),修改后完整配置如下(修改dataDir和dataLogDir):
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper-cluster/data/
dataLogDir=/usr/local/zookeeper-cluster/log/
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=10.20.3.72:2287:3387
server.2=10.20.3.73:2287:3387
server.3=10.20.3.74:2287:3387
配置参数说明:
- tickTime:用于计算的基础时间单元。比如 session 超时:N*tickTime;
- initLimit:用于集群,允许从节点连接并同步到 master 节点的初始化连接时间,以 tickTime 的倍数来表示;
- syncLimit:用于集群, master 主节点与从节点之间发送消息,请求和应答时间长度(心跳机制);
- dataDir:数据存储位置;
- dataLogDir:日志目录;
- clientPort:用于客户端连接的端口,默认 2181
3.5 zookeeper集群配置
分别在三台主机的 dataDir 目录【/usr/local/zookeeper-cluster/data】下新建 myid 文件:
# 三台主机均执行该命令
mkdir -vp /usr/local/zookeeper-cluster/data/
并写入对应的节点标识:
# vi mydi
写入内容:
hadoop001主机【10.20.3.72】:
echo "1" > /usr/local/zookeeper-cluster/data/myid
hadoop001主机【10.20.3.73】:
# echo "2" > /usr/local/zookeeper-cluster/data/myid
hadoop001主机【10.20.3.74】:
# echo "3" > /usr/local/zookeeper-cluster/data/myid
Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 Leader 节点。
3.6 启动zookeeper集群
分别在三台主机上,执行如下命令启动服务:
/usr/app/apache-zookeeper-3.5.9-bin/bin/zkServer.sh start
3.7 验证
【单机验证:】使用 JPS 验证进程是否已经启动,出现 QuorumPeerMain 则代表启动成功。
[root@hadoop001 bin]# jps
3814 QuorumPeerMain
【集群验证:】
启动后使用 zkServer.sh status 查看集群各个节点状态。如图所示:三个节点进程均启动成功,并且 hadoop002【10.20.3.73】 为 leader 节点,hadoop001【10.20.3.72】 和 hadoop003【10.20.3.74】 为 follower 节点。



4 配置spark
4.1 集群规划
这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001【10.20.3.72】 上部署主 Master 服务外,还在 hadoop002【10.20.3.73】 和 hadoop003【10.20.3.74】 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。

4.2 下载解压
下载所需版本的 Spark,官网下载地址:http://spark.apache.org/downloads.html
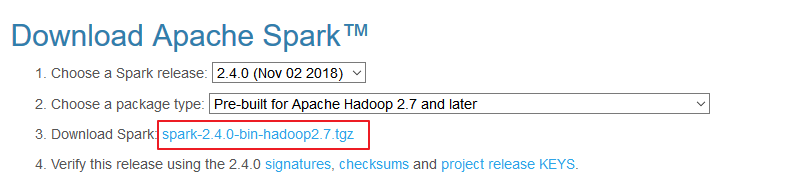
这里直接使用下载好的包,进行安装,下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
移动指定文件夹:
mv spark-2.2.3-bin-hadoop2.6 /usr/app/
4.3 配置环境变量
# vim /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.4.7-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
4.4 集群配置
进入 ${SPARK_HOME}/conf 目录,拷贝配置样本进行修改:
1. spark-env.sh
配置JDK安装位置、配置hadoop配置文件、配置zookeeper地址。
#!/usr/bin/env bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This file is sourced when running various Spark programs.
# Copy it as spark-env.sh and edit that to configure Spark for your site.
# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program
# Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
# Options read in YARN client/cluster mode
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_DAEMON_CLASSPATH, to set the classpath for all daemons
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
# - SPARK_NO_DAEMONIZE Run the proposed command in the foreground. It will not output a PID file.
# Options for native BLAS, like Intel MKL, OpenBLAS, and so on.
# You might get better performance to enable these options if using native BLAS (see SPARK-21305).
# - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL
# - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS
JAVA_HOME=/usr/java/jdk1.8.0_192
HADOOP_CONF_DIR=/usr/app/hadoop-2.10.1/etc/hadoop
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=10.20.3.72:2181,10.20.3.73:2181,10.20.3.74:2181 -Dspark.deploy.zookeeper.dir=/spark"
2. slaves
cp slaves.template slaves
配置所有 Woker 节点的位置:
10.20.3.72
10.20.3.73
10.20.3.74
4.5 启动集群
4.5.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
# zkServer.sh start
4.5.2 启动Hadoop集群
进入到${HADOOP_HOME}/sbin 目录下,启动 Hadoop:
# 启动dfs服务
sh start-dfs.sh
# 启动yarn服务
sh start-yarn.sh
4.5.3 启动Spark集群
进入 hadoop001【10.20.3.72】 的 ${SPARK_HOME}/sbin 目录下,执行下面命令启动集群。执行命令后,会在 hadoop001【10.20.3.72】 上启动 Maser 服务,会在 slaves 配置文件中配置的所有节点上启动 Worker 服务。
./start-all.sh
分别在 hadoop002【10.20.3.73】 和 hadoop003【10.20.3.74】 上执行下面的命令,启动备用的 Master 服务:
# ${SPARK_HOME}/sbin 下执行
./start-master.sh
4.6 查看服务
查看 Spark 的 Web-UI 页面,端口为 8080【如果无法显示,向后递增查看端口】。此时可以看到 hadoop001 上的 Master 节点处于 ALIVE 状态,并有 3 个可用的 Worker 节点。

而 hadoop002 和 hadoop003 上的 Master 节点均处于 STANDBY 状态,没有可用的 Worker 节点。


4.7 验证集群高可用
此时可以使用 kill 命令杀死 hadoop001[10.20.3.72] 上的 Master 进程。
例如:
例如,使用jps查看进程,然后使用kill杀死:
# jps
21488 ResourceManager
23296 DataNode
30497 ControlCenter
32226 ConnectDistributed
25379 QuorumPeerMain
43699 Jps
27207 Master
23656 NodeManager
22298 NameNode
22507 SecondaryNameNode
29884 Kafka
30062 KafkaRestMain
# kill -9 27207
此时备用 Master 会中会有一个再次成为 主 Master,我这里是 hadoop002[10.20.3.73],可以看到 hadoop2 上的 Master 经过 RECOVERING 后成为了新的主 Master,并且获得了全部可以用的 Workers。

Hadoop002 上的 Master 成为主 Master,并获得了全部可以用的 Workers。

此时如果你再在 hadoop001 上使用 start-master.sh 启动 Master 服务,那么其会作为备用 Master 存在。
4.8 提交作业测试
和单机环境下的提交到 Yarn 上的命令完全一致,这里以 Spark 内置的计算 Pi 的样例程序为例,提交命令如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 10 \
/usr/app/spark-2.4.7-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.0.jar \
100
5 配置HBase
这里搭建一个 3 节点的 HBase 集群,其中三台主机上均为 Region Server。同时为了保证高可用,除了在 hadoop001【10.20.3.72】上部署主 Master 服务外,还在 hadoop002 【10.20.3.73】上部署备用的 Master 服务。Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。

Base 的运行需要依赖 Hadoop 和 JDK(HBase 2.0+ 对应 JDK 1.8+) 。同时为了保证高可用,这里我们不采用 HBase 内置的 Zookeeper 服务,而采用外置的 Zookeeper 集群。
5.1 下载解压并配置环境变量
下载并解压,这里我下载的是 CDH 版本 HBase,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zxvf hbase-2.3.3-bin.tar.gz
# vim /etc/profile
添加环境变量:
export HBASE_HOME=/usr/app/hbase-2.3.3
export PATH=$HBASE_HOME/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
5.2 集群配置
进入 ${HBASE_HOME}/conf 目录下,修改配置:
1. hbase-env.sh
# 配置JDK安装位置
export JAVA_HOME=/usr/java/jdk1.8.0_192
# 不使用内置的zookeeper服务
export HBASE_MANAGES_ZK=false
2. hbase-site.xml
<configuration>
<property>
<!-- 指定 hbase 以分布式集群的方式运行 -->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<!-- 指定 hbase 在 HDFS 上的存储位置 -->
<name>hbase.rootdir</name>
<value>hdfs://10.20.3.72:8020/hbase</value>
</property>
<property>
<!-- 指定 zookeeper 的地址-->
<name>hbase.zookeeper.quorum</name>
<value>10.20.3.72:2181,10.20.3.73:2181,10.20.3.74:2181</value>
</property>
</configuration>
3. regionservers
10.20.3.72
10.20.3.73
10.20.3.74
4. backup-masters
10.20.3.73
backup-masters 这个文件是不存在的,需要新建,主要用来指明备用的 master 节点,可以是多个,这里我们以 1 个为例。
5.3 HDFS客户端配置
这里有一个可选的配置:如果您在 Hadoop 集群上进行了 HDFS 客户端配置的更改,比如将副本系数 dfs.replication 设置成 5,则必须使用以下方法之一来使 HBase 知道,否则 HBase 将依旧使用默认的副本系数 3 来创建文件:
- Add a pointer to your
HADOOP_CONF_DIRto theHBASE_CLASSPATHenvironment variable in hbase-env.sh.- Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better, symlinks, under ${HBASE_HOME}/conf, or
- if only a small set of HDFS client configurations, add them to hbase-site.xml.
以上是官方文档的说明,这里解释一下:
第一种 :将 Hadoop 配置文件的位置信息添加到 hbase-env.sh 的 HBASE_CLASSPATH 属性,示例如下:
export HBASE_CLASSPATH=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
第二种 :将 Hadoop 的 hdfs-site.xml 或 hadoop-site.xml 拷贝到 ${HBASE_HOME}/conf 目录下,或者通过符号链接的方式。如果采用这种方式的话,建议将两者都拷贝或建立符号链接,示例如下:
# 拷贝
cp core-site.xml hdfs-site.xml /usr/app/hbase-2.3.3/conf/
# 使用符号链接
ln -s /usr/app/hadoop-2.10.1/etc/hadoop/core-site.xml
ln -s /usr/app/hadoop-2.10.1/etc/hadoop/hdfs-site.xml
注:
hadoop-site.xml这个配置文件现在叫做core-site.xml
第三种 :如果你只有少量更改,那么直接配置到 hbase-site.xml 中即可。
5.4 启动HBase
首先启动ZooKeeper集群,然后启动Hadoop集群,最后启动HBase集群。
进入 hadoop001 【10.20.3.72】的 ${HBASE_HOME}/bin,使用以下命令启动 HBase 集群。执行此命令后,会在 hadoop001 上启动 Master 服务,在 hadoop002 【10.20.3.73】上启动备用 Master 服务,在 regionservers 文件中配置的所有节点启动 region server 服务。
start-hbase.sh
5.5 查看服务
访问 HBase 的 Web-UI 界面,这里我安装的 HBase 版本为 1.2,访问端口为 60010,如果你安装的是 2.0 以上的版本,则访问端口号为 16010。可以看到 Master 在 hadoop001【10.20.3.72】 上,三个 Regin Servers 分别在 hadoop001,hadoop002【10.20.3.73】,和 hadoop003 上,并且还有一个 Backup Matser 服务在 hadoop002 上。

hadoop002 上的 HBase 出于备用状态:

6 Hive配置
只在hadoop001【10.20.3.72】上配置。
6.1 下载并解压
下载所需版本的 Hive,这里我下载版本为 cdh5.15.2。下载地址:http://archive.cloudera.com/cdh5/cdh/5/
直接使用下载完的安装包进行安装:
# 下载后进行解压
tar -zxvf apache-hive-2.3.8-bin.tar.gz
6.2 配置环境变量
# vim /etc/profile
添加环境变量:
export HIVE_HOME=/usr/app/apache-hive-2.3.8-bin
export PATH=$HIVE_HOME/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
在hive安装目录下,新建文件夹auxlib,将hudi-hadoop-mr-bundle-0.7.0.jar包复制到文件夹下,可同时复制一份到hive的lib目录下。
6.3 修改配置
1. hive-env.sh
进入安装目录下的 /usr/app/apache-hive-2.3.8-bin/conf 目录,拷贝 Hive 的环境配置模板 flume-env.sh.template:
cp hive-env.sh.template hive-env.sh
修改 hive-env.sh,指定 Hadoop 的安装路径:
HADOOP_HOME=/usr/app/hadoop-2.10.1
2. hive-site.xml
新建 hive-site.xml 文件,内容如下,主要是配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息:
- 数据库地址:jdbc:mysql://10.20.3.44:3306
- 数据库数据库名称:jkHive
- 数据库用户名:root
- 数据库密码:root
- HDFS存储位置配置:/home/hive/warehouse
- 服务器地址:10.20.3.72,10.20.3.73,10.20.3.74
- hive引入包:/usr/app/apache-hive-2.3.8-bin/auxlib【引入的包:hudi-hadoop-mr-bundle-0.7.0.jar】
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.20.3.44:3306/jkHive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hive/warehouse</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>10.20.3.72,10.20.3.73,10.20.3.74</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>/usr/app/apache-hive-2.3.8-bin/auxlib</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.allow.user.substitution</name>
<value>true</value>
</property>
</configuration>
3. 拷贝数据库驱动
将 MySQL 驱动包拷贝到 Hive 安装目录的 /usr/app/apache-hive-2.3.8-bin/lib 目录下, MySQL 驱动的下载地址为:https://dev.mysql.com/downloads/connector/j/ , 在本仓库的resources 目录下我也上传了一份,有需要的可以自行下载。

这里直接移动下载好的软件:
cp hudi-hadoop-mr-bundle-0.7.0.jar /usr/app/apache-hive-2.3.8-bin/lib
6.4 初始化元数据库
-
当使用的 hive 是 1.x 版本时,可以不进行初始化操作,Hive 会在第一次启动的时候会自动进行初始化,但不会生成所有的元数据信息表,只会初始化必要的一部分,在之后的使用中用到其余表时会自动创建;
-
当使用的 hive 是 2.x 版本时,必须手动初始化元数据库。初始化命令:
# schematool 命令在安装目录的 bin 目录下,由于上面已经配置过环境变量,在任意位置执行即可 schematool -dbType mysql -initSchema
6.5 启动
由于已经将 Hive 的 bin 目录配置到环境变量,直接使用以下命令启动,成功进入交互式命令行后执行 show databases 命令,无异常则代表搭建成功。
# hive
或
在hive目录下:
hive服务器启动命令:
启动 : nohup bin/hive --service metastore &
查看运行过程: tail -f nohup.out
客户端启动命令:bin/hive
如果连接.Beeline
启动服务器命令以后在启动: nohup bin/hiveserver2 &

在 Mysql 中也能看到 Hive 创建的库和存放元数据信息的表

6.6 使用HiveServer2/beeline
Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,因此产生了 HiveServer2。HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务。
HiveServer2 拥有自己的 CLI 工具——Beeline。Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于目前 HiveServer2 是 Hive 开发维护的重点,所以官方更加推荐使用 Beeline 而不是 Hive CLI。以下主要讲解 Beeline 的配置方式。
6.6.1 启动hiveserver2
可以使用以下命令进入 beeline 交互式命令行,出现 Connected 则代表连接成功。
# beeline -u jdbc:hive2://hadoop001:10000 -n root

更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)