




- @zhaosuyuan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
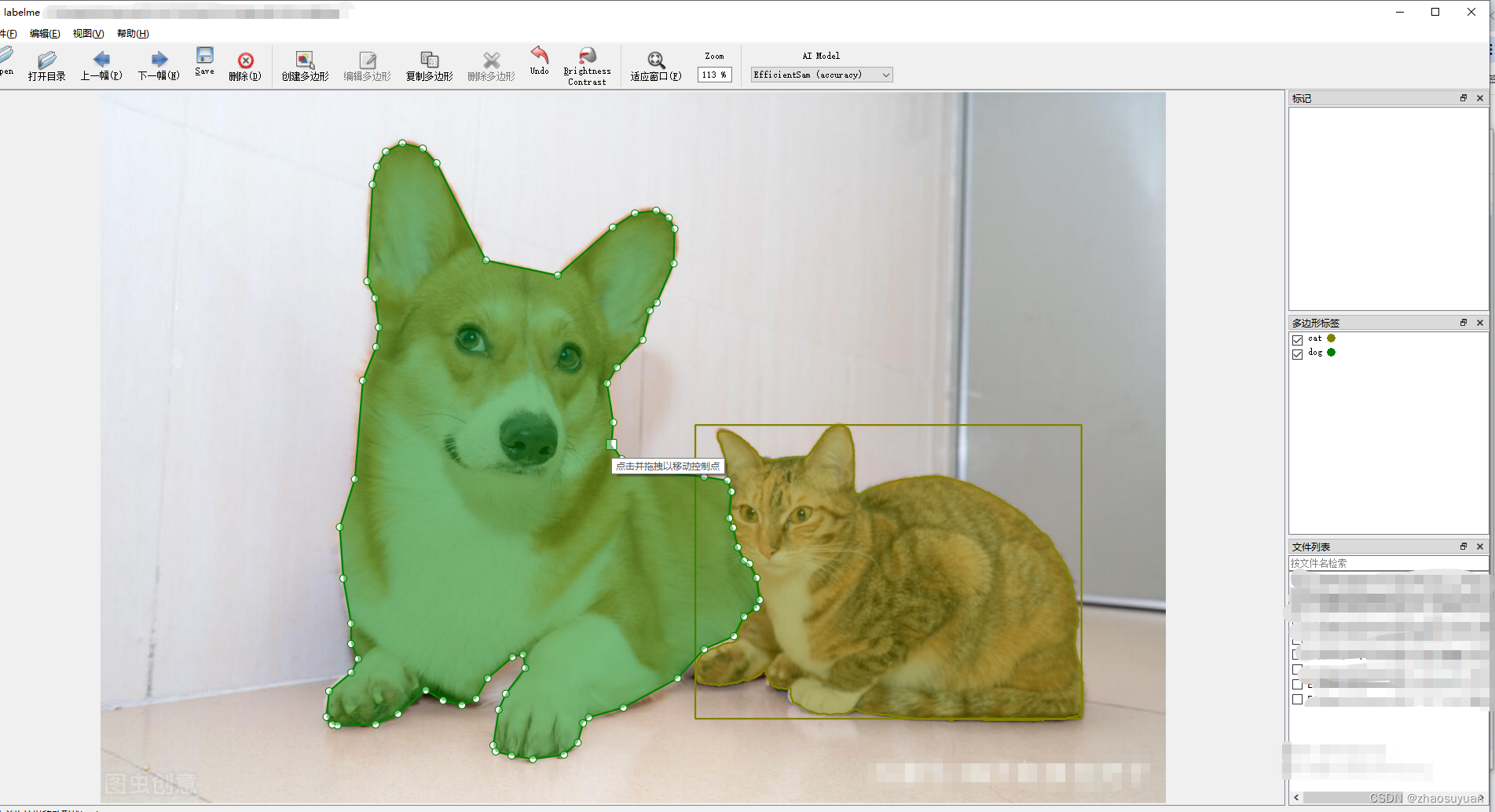
【代码】labelme自动标注工具的安装和代码修改。
本文介绍了GPU的关键参数与选型要素。GPU由GPU芯片、显存、PCB板等组件构成,可通过Linux命令查看详细信息。主要性能指标包括:1)算力(TFLOPS),决定计算速度;2)显存容量与带宽,影响数据处理能力;3)核心数量,提升并行处理效率。GPU架构演进从Volta到Hopper,不同架构对应不同计算能力版本号(sm_xx)。选型还需考虑软件生态、互联技术及物理参数。此外,文章详细解析了FP
1.直接使用别人的anaconda安装环境source /home/XXX/anaconda3/bin/activatecondaactivate labelme2.copy anaconda环境cp-r/home/XXX/anaconda3/envs/x-anylabeling/home/YYY/anaconda3/envsconda config --append envs_dirs/home

【代码】labelme自动标注工具的安装和代码修改。
python 根据url下载图像。
3.train loss不断下降,test loss趋于不变,过拟合:(1)正则化和降维(2)降低模型复杂度 (3)获取更多数据集、数据增强。翻转,旋转,裁剪,缩放,平移,抖动、Mixup、Cutout、Cutmix、Mosaci等。4.train loss趋于不变,test loss不断下降:数据集有问题,检查数据集。6.train loss不断上升,test loss不断上升:数据清洗,超参设

selective attention简单且无需额外参数的选择性注意力机制,通过选择性忽略不相关信息并进行上下文剪枝,在不增加计算复杂度的情况下显著提升了Transformer模型的语言建模性能和推理效率。

从.xml标注文件voc格式数据中提取bbox,通过yolov4 mosaic数据增强,四张图片合成一张,并生成相应voc格式import osimport cv2import globimport randomimport numpy as npfrom PIL import Imageimport xml.etree.ElementTree as ETOUTPUT_SIZE = (600, 6
摘要: InstructGPT通过三阶段训练实现语言模型与人类偏好对齐:1)监督微调(SFT)使模型初步遵循指令;2)奖励模型(RM)学习人类偏好排序;3)强化学习(RLHF)结合PPO算法优化输出,通过KL散度约束平衡创新与稳定性。该方法解决了模型幻觉问题,奠定ChatGPT等技术基础,并推动DPO等后续优化方案的发展。核心创新在于“生成-评价-优化”闭环,首次系统性融合人类反馈,成为大模型对齐
摘要:CLIP(Contrastive Language-Image Pre-training)是OpenAI 2021年提出的多模态预训练模型,通过对比学习将图像与文本语义对齐。其核心突破在于摆脱固定类别标签限制,利用4亿图文对预训练视觉-语言联合表征,实现高效的zero-shot迁移。模型采用双编码器结构(图像/文本),通过对比损失学习跨模态相似性。推理时通过prompt工程将下游任务转化为图