- @zhangshangjie1
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这一步,我还没找到怎么导出来,以及导出来之后,能不能和vcs的vdb文件兼容;2. 打开jaspergold coverage APP;4. 生成的结果中,黑色的部分,就是deadcode;有知道的大佬,麻烦补充到评论中;5. 导出exclude文件;3. 设置并开始分析;1. 编写tcl脚本。

感知器运算的通⽤性既是令⼈⿎舞的,⼜是令⼈失望的。令⼈⿎舞是因为它告诉我们感知器 ⽹络能和其它计算设备⼀样强⼤。但是它也令⼈失望,因为它看上去只不过是⼀种新的与⾮⻔。这简直不算个⼤新闻!然⽽,实际情况⽐这⼀观点认为的更好。其结果是我们可以设计学习算法,能够⾃动调整⼈⼯神经元的权重和偏置。这种调整可以响应外部的刺激,⽽不需要⼀个程序员的直接⼲预。这些学习算法是我们能够以⼀种根本区别于传统逻辑⻔的⽅式
我们可以看到测试集上的代价在15迭代期前⼀直在提升,随后越来越差,尽管训练数据集 上的代价表现是越来越好的。从⼀个实践⻆度, 我们真的关⼼的是提升测试数据集上的分类准确率,⽽测试集合上的代价不过是分类准确率的 ⼀个反应。即使这样的模型能够 很好的拟合已有的数据,但并不表⽰是⼀个好模型。诺⻉尔奖获得者,物理学家恩⾥科·费⽶有⼀次被问到他对⼀些同僚提出的⼀个数学模型的 意⻅,这个数学模型尝试解决⼀个重

ecall 指令以前叫做 scall,用于执行环境的变更,它会根据当前所处模式触发不同的执行环境切换异常, 用来执行需要更高权限才能执行的功能;简单来说,ecall 指令将权限提升到内核模式并将程序跳转到指定的地址。操作系统内核和应用程序其实都是相同格式的文件,最关键的区别就是程序执行的特权级别不同。所以 Syscall 的本质其实就是提升特权权限到内核模式,并跳转到操作系统指定的用于处理 Sys

假设神经⽹络以上述⽅式运⾏,我们可以给出⼀个貌似合理的理由去解释为什么⽤10个输出⽽不是4个。把数字的最⾼有效位和数字的形状联系起来并不是⼀个简单的问题。很难想象出有 什么恰当的历史原因,⼀个数字的形状要素会和⼀个数字的最⾼有效位有什么紧密联系。最终的判断是基于经验主义的:我们可以实验两种不同的⽹络设计,结果证明对于这个特定的问题⽽⾔,10个输出神经元的神经⽹络⽐4个的识别效果更好.⼀个看起来更⾃

uvm_active
因此,到目前为止,对于分支指令的目标地址的预测,有下面的三种方法。这些方式都是在取指阶段,利用pc值来进行;(1)使用 BTB 对直接跳转(PC-relative)类型的分支指令和 CALL 指令进行预测;(2)使用RAS对Return指令进行预测;(3)使用 Target Cache 对其他类型的分支指令进行预测。尤其是对于BTB和RAS, 几乎是现代的超标量处理器必须要使用的。

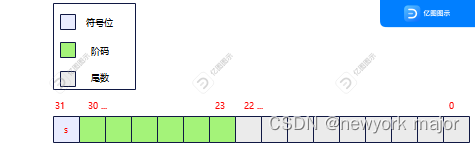
小数部分:0.1247,不断乘以2,取整数部分,00011111111011001..., 因为位数不够,进行截断;3. 将得到的数,表示成IEEE 754的格式,0.00101=1.01*2-3。这个数可能在32bits范围内,不能准确的表示出来,因此需要进行截位;⭘0.15625x2=0.3125 取整0。⭘0.31250x2=0.6250 取整0。⭘0.25000x2=0.5000 取整0。
□ 如果被snp的人,没有这条cacheline的copy, 则writeUniqueFullStash/ WriteUniquePtlStash命令□ 接收后,可以去snoop对应的stash target;□ Non-alloc的数据,ReadNoSnp and ReadOnce*, 数据是不希望被cache住的,但是如果RN中的cache住了,数据不能放进HNF, 即系统一致性不保证;□ 发
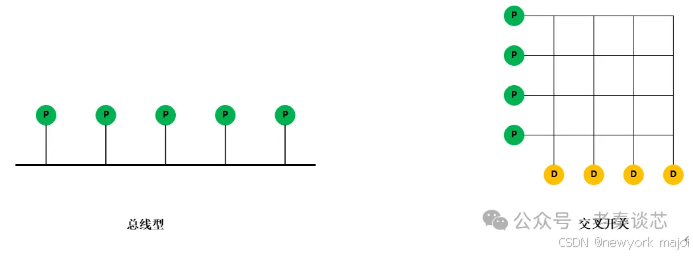
转载自《芯片验证日记》转载的《老秦谈芯》;部分内容格式做了调整,便于更加具象化;随着近些年SoC的设计规模越来越大,片上网络(NoC,Network on Chip)逐渐被大家关注。今天简单聊聊关于NoC的几个重要话题:拓扑(topology),即如何连接每个节点路由(routing),即数据如何在节点之间的传递路径流量控制(flow control),即如何控制数据在源节点和目的节点传递微架构(