




- @zaisushe
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
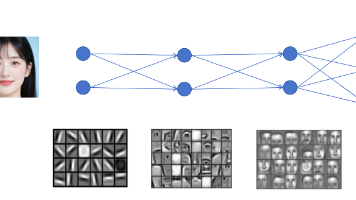
有研究论文发现,同等参数量的模型,一个浅而宽的神经网络效果是远不如一个窄而深的神经网络的。当然每一层的神经元也不能太少,至少要能学习到这一层的所有模式才行,这一层是学习的人脸的器官,那必须有神经元分别是识别眼睛、眼镜、眉毛、额头、嘴巴、鼻子、耳朵、脸颊、下巴等等。但是有一个问题,就是函数的值域一直是0到1,为了调整图像在y轴上的变化,我们对Sigmoid函数的输出也加上两个参数来进行线性控制,这里
Dataset负责数据的读取和预处理,而DataLoader则负责将数据分成小批量,支持多线程加速,以及数据的打乱等。本节,我们就以Titanic数据集为例,讲解如何使用PyTorch里的Dataset和DataLoader类来处理数据。PyTorch里默认实现的DataLoader就可以满足我们的使用,它定义了如何批量读取数据的功能。这样我们的TitanicDataset就是一个合格的PyTor

带动量的优化算法你可以理解为从山上滚下的小球是带有惯性的,可以帮助它冲过一些小的坑,不会陷入下降过程中的局部小坑中。梯度下降的做法是选择沿最陡峭的路向下走一段,然后再观察,再选择最陡峭的路向下。通过上边的例子,我们可以看到,直接以导数值的大小作为步长看起来不错,但是实际上还需要乘以一个步长的系数。不断接近全局最低点,曲线也变的平缓,导数值变小,每次步长也变小,这有利于我们在全局最低点附近进行精细调

这种机制,就是广播机制。需要特别注意的是,扩展维度时会对两个tensor的每个维度的维度值进行检查,如果在某个维度上两个tensor的维度值不同,那么必须有一个tensor在这个维度的维度值是1,否则广播就会失败,整个计算就失败。通过上边的学习,我们知道一个tensor有几个常用的关键属性,第一个是tensor的形状,第二个是tensor内元素的类型,第三个是tensor的设备。结果的shape为

然后将所有点的误差都累积起来,通过调节参数w的值,能让累积误差最小的直线,就是最好拟合我们数据的直线。当模型训练好之后,就可以只输入新的样本的feature,模型根据学习到的内部参数,计算出预测值了。无监督学习最常见的模型就是聚类模型,比如电信运营商根据所有用户的消费数据,让模型自动发现用户的消费习惯,有的是电话多,有的是流量多,从而聚类出很多套餐类别。有了这条直线,我们就可以进行预测了, 如果天

然后将所有点的误差都累积起来,通过调节参数w的值,能让累积误差最小的直线,就是最好拟合我们数据的直线。当模型训练好之后,就可以只输入新的样本的feature,模型根据学习到的内部参数,计算出预测值了。无监督学习最常见的模型就是聚类模型,比如电信运营商根据所有用户的消费数据,让模型自动发现用户的消费习惯,有的是电话多,有的是流量多,从而聚类出很多套餐类别。有了这条直线,我们就可以进行预测了, 如果天
但是不适合作为隐藏层的激活函数,因为Sigmoid输出总是正数。它非常适合作为二分类问题的神经网络的最后一层唯一神经元的激活函数。ReLU函数有个问题,就是当x小于0时,ReLU(x)值为0,它的梯度为0,参数无法更新。正是因为引入激活函数,模拟了大脑神经元里的抑制和激活。如果没有激活函数,不论几层的神经网络都是一个线性回归。以上边1个隐藏层,一个输出层的简单神经网络为例,如果没有激活函数,只进行