




- @yuxiaosmd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
作者:xiaoyu,数据爱好者Python数据科学出品学习数据科学很久了,从数据探索、数据预处理、数据模型搭建和部署这些过程一直有些重复性的工作比较浪费时间,尤其当你有个新的想法想要快速尝试下效果的时候,效率很低。东哥最近发现一个开源的Python机器学习库,名字叫PyCaret,这个轮子正好可以为了解决我刚才所描述的困扰,它的特点是以low-code低代码量来快速解决从数据预处理到模型部署的整个
相信玩过爬虫的朋友都知道selenium,一个自动化测试的神器工具。写个Python自动化脚本解放双手基本上是常规的操作了,爬虫爬不了的,就用自动化测试凑一凑。虽然selenium有完备的文档,但也需要一定的学习成本,对于一个纯小白来讲还是有些门槛的。最近,微软开源了一个项目叫「playwright-python」,简直碉堡了!这个项目是针对Python语言的纯自动化工具,连代码都不用写,就能实现
作者:xiaoyu微信公众号:Python数据科学知乎:python数据分析师前言玩过建模的朋友都知道,在建立模型之前有很长的一段特征工程工作要做,而在特征工程的过程中,探索性数据分析又是必不可少的一部分,因为如果我们要对各个特征进行细致的分析,那么必然会进行一些可视化以辅助我们来做选择和判断。可视化的工具有很多,但是能够针对特征探索性分析而进行专门可...
作者:xiaoyu微信公众号:Python数据科学知乎:python数据分析上一篇和大家分享了一个入门数据分析的一个小项目 北京二手房房价分析,链接如下:数据分析实战—北京二手房房价分析文章在sf发布之后看到有不少感兴趣的朋友给我点了赞,感谢大家的支持了。本篇将继续上一篇数据分析之后进行数据挖掘建模预测,这两部分构成了一个简单的完整项目。结合两篇文章通过数据分析和挖掘的方...
作者:xiaoyu微信公众号:Python数据科学知乎:Python数据分析最近生活上确实有点忙,不过后续将恢复正常。今天和大家聊一个非技术性的话题:转行。全篇无代码,但是我想对于这个话题,很多朋友都非常感兴趣,毕竟工作伴随着我们的一生,也是主要的收入来源,谁不想找一份高薪又有前景的工作呢? 是否要转行? 有些朋友对于是否该转行一直抱有迟疑态度,转行会不会有风险啊,转行以...
作者:xiaoyu微信公众号:Python数据科学知乎:python数据分析非经作者允许,禁止任何商业转载。目的:本篇给大家介绍一个数据分析的初级项目,目的是通过项目了解如何使用Python进行简单的数据分析。数据源:博主通过爬虫采集的链家全网北京二手房数据(公众号后台回复 二手房数据 便可获取)。目录数据初探数据可视化分析总结数据初探首先导入要使用...
作者:东哥起飞公众号:Python数据科学上一篇分享了关于数据缺失值处理的一些方法,链接如下:【Python数据分析基础】: 数据缺失值处理本篇继续分享数据清洗中的另一个常见问题:异常值检测和处理。1 什么是异常值?在机器学习中,异常检测和处理是一个比较小的分支,或者说,是机器学习的一个副产物,因为在一般的预测问题中,模型通常是对整体样本数据结构的一种表达方式,这种表达方式通常抓住的是整体样本一般
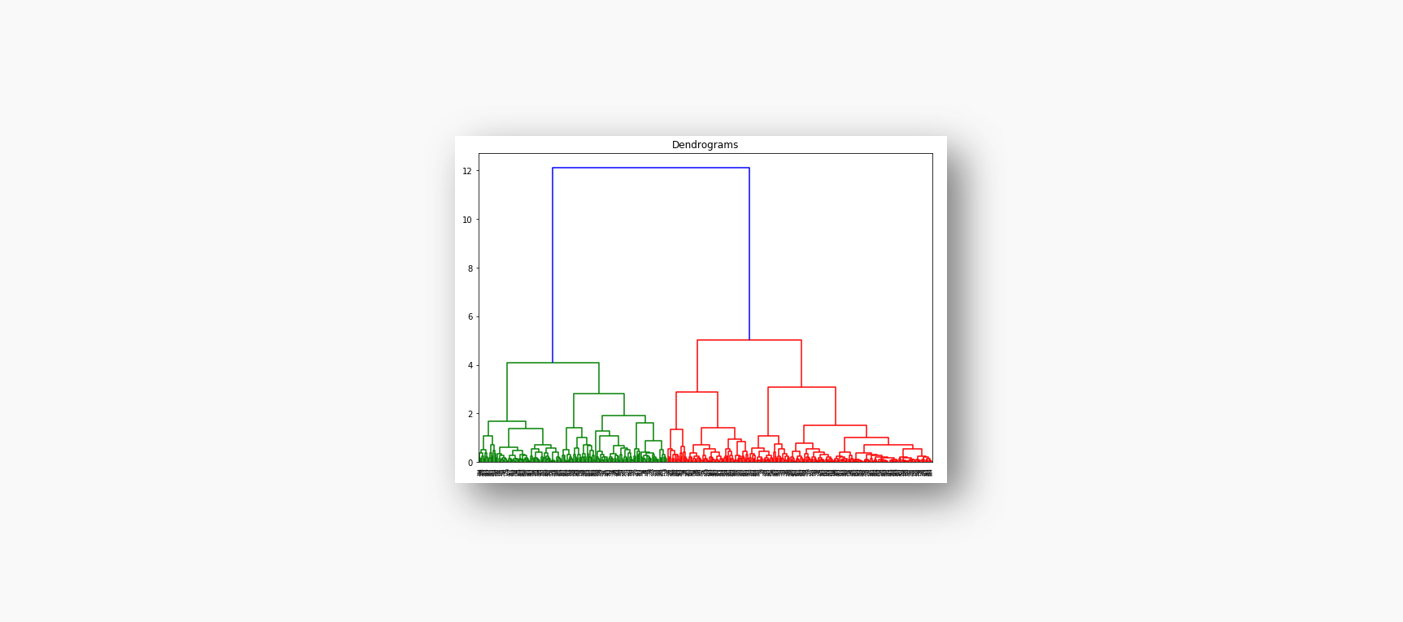
大家好,我是东哥。本篇想和大家介绍下层次聚类,先通过一个简单的例子介绍它的基本理论,然后再用一个实战案例Python代码实现聚类效果。首先要说,聚类属于机器学习的无监督学习,而且也分很多种方法,比如大家熟知的有K-means。层次聚类也是聚类中的一种,也很常用。下面我先简单回顾一下K-means的基本原理,然后慢慢引出层次聚类的定义和分层步骤,这样更有助于大家理解。层次聚类和K-means有什么不
作者:东哥起飞EDA是数据分析必须的过程,用来查看变量统计特征,可以此为基础尝试做特征工程。东哥这次分享3个EDA神器,其实之前每一个都分享过,这次把这三个工具包汇总到一起来介绍。1. Pandas_Profiling这个属于三个中最轻便、简单的了。它可以快速生成报告,一览变量概况。首先,我们需要安装该软件包。# 安装Jupyter扩展widgetjupyter nbextension enabl
大家好,我是东哥。接着前两篇继续介绍本篇,前两篇链接如下:【机器学习笔记】:大话线性回归(一)【机器学习笔记】:大话线性回归(二)本篇介绍线性回归诊断的余下部分:多重共线性分析强影响点分析一、多重共线性检验1. 多重共线性产生的问题当回归模型中两个或两个以上的自变量彼此相关时,则称回归模型中存在多重共线性,也就是说共线性的自变量提供了重复的信息。那么这种多重共线性会有什么不好的影响吗?答案是会的,