- @yutianzuijin
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先确保hadoop已经正确安装、配置以及运行。1. 首先将wordcount源代码从hadoop目录中拷贝出来。[root@cluster2 logs]# cp /usr/local/hadoop-1.1.2/src/examples/org/apache/hadoop/examples/WordCount.java ~/ygch/hadoop/因为在编译过程中需要将jave
Failed to set setXIncludeAware(true) for parser遇到此问题一般是jar包冲突的问题。一种情况是我们向java的lib目录添加我们自己的jar包导致hadoop引用jar包的冲突。解决方案就是删除我们自己向系统添加的jar包,重新配置。将自己的jar包或者外部jar放入系统目录会在编译程序时带来方便,但是这不是一种好习惯,我们应该通过修改CLAS
JNI是java和C/C++混合编程的接口,可以很方便地实现java调用C/C++语言。具体的使用方法,网上有很多教程,在此不做过多介绍。本博客只关注在使用JNI的过程中的常见问题。1. 生成头文件用命令:javah*.class这是错误的。运行上述命令会提示:java.lang.IllegalArgumentException: Not a valid class name:Se
写这篇博客的目的就是想搞清楚英伟达不同显卡之间的性能差异以及移动端GPU的性能达到了英伟达显卡的哪一代,让自己也让大家明白不同显卡的算力差异。所有的数据均从网络搜索,有不正确的地方欢迎批评指正。同一显卡会有一个首次发布,此外还有一系列的迭代升级版本,我们只考虑首次发布版本的性能。鉴于现在的模型推理大多使用int8来进行推理,所以大家可以着重看一下int8算力那一列。
这篇博客本应完成于24年9月,但是由于入职新公司之后上下班距离较远下班之后无力再动脑,遂拖到现在才完成,而且再看文章内容感觉不少部分都已过时,但还是可以当做一篇综述性文章来读,了解KV Cache压缩的历史。在之前的博客《》中我们简单提到了KV Cache在超长上下文下过大的问题。为了使得大模型推理能支持超长上下文,我们必须要对KV Cache进行压缩,本博客就介绍一下目前常用的压缩手段。我们还是
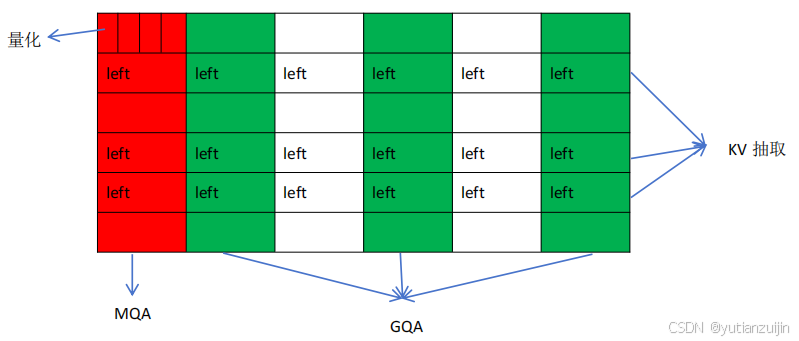
KV Cache是大模型推理中常用到的一个技巧,可以减少重复计算,加快推理速度。不少人只是从概念上知道它可以减少重复计算,详细的原理则知之甚少,此外为啥只有KV Cache而没有Q Cache呢,我们在本博客中给出详尽的解释。

过去的一周Qwen2.5-Omni产生了很高的热度,吸引了很多人的目光。它的多模态确实很吸引人,放出来的体验还算尚可(语音对话的延迟还是太大),所以就在A100 PCIe上实地部署了一下,初步对其速度进行了测试,以下是我的操作流程,供大家参考。
本来想写一篇KV Cache压缩的综述性博客,结果写到MLA部分的时候发现越写越多,完全值得单独拿出来写篇博客,遂从KV Cache压缩博客中单独揪出MLA进行介绍。MLA(Multi-query Latent Attention)是国内创业公司deepseek在24年5月份发布的大模型中用到的KV Cache压缩技术,正是在该技术的加持下DeepSeek-V2可以大幅压缩KV Cache的大小,

在上一篇博客《》中详细介绍了大模型推理的decoding阶段可以采用KV Cache来优化重复计算的原理。虽然KV Cache大幅提升了大模型token生成的速度,但是也引入了新的问题,主要有两个:1. KV Cache在长上下文的情况下占用量非常大,导致batch很小,进而影响吞吐量,甚至根本无法支持长上下文;2. 大模型推理的时候无法预知会产生多少token,所以无法给KV Cache预分配空

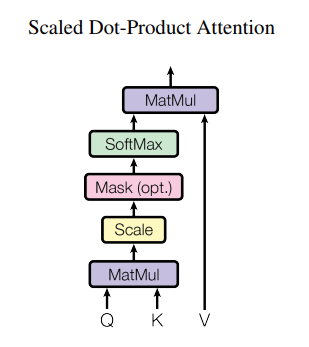
在学习huggingFace的Transformer库时,我们不可避免会遇到scaled_dot_product_attention(SDPA)这个函数,它被用来加速大模型的Attention计算,本文就详细介绍一下它的使用方法,核心内容主要参考了torch.nn.functional中该函数的注释。