- @yumaomi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LLaVA系列模型通过创新的视觉-语言对齐架构,推动了多模态AI的发展。关键技术包括:1)使用CLIP/SigLIP视觉编码器提取图像特征;2)采用MLP投影层将视觉特征映射到文本嵌入空间;3)逐步提升输入分辨率(224→672px)并支持动态切块处理;4)优化训练策略(两阶段训练、数据混合)。最新版本LLaVA-NeXT和OneVision进一步增强了OCR能力,支持多图像/视频输入,并通过Si
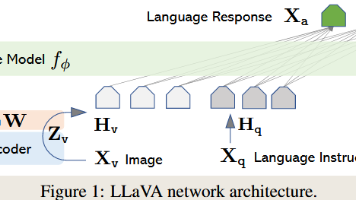
LLaVA系列模型通过创新的视觉-语言对齐架构,推动了多模态AI的发展。关键技术包括:1)使用CLIP/SigLIP视觉编码器提取图像特征;2)采用MLP投影层将视觉特征映射到文本嵌入空间;3)逐步提升输入分辨率(224→672px)并支持动态切块处理;4)优化训练策略(两阶段训练、数据混合)。最新版本LLaVA-NeXT和OneVision进一步增强了OCR能力,支持多图像/视频输入,并通过Si
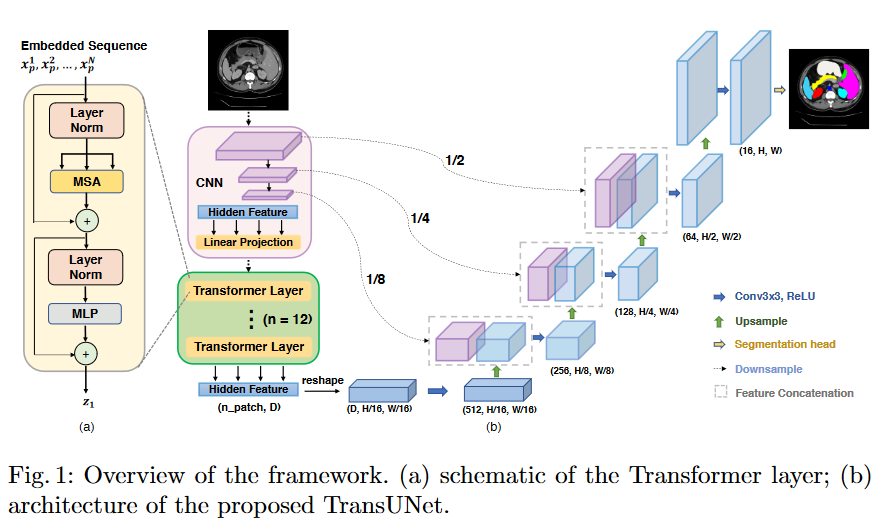
本文介绍了医学图像处理领域的TransUnet模型,TransUnet模型主要由ResNet50、Vision Transformer组成。
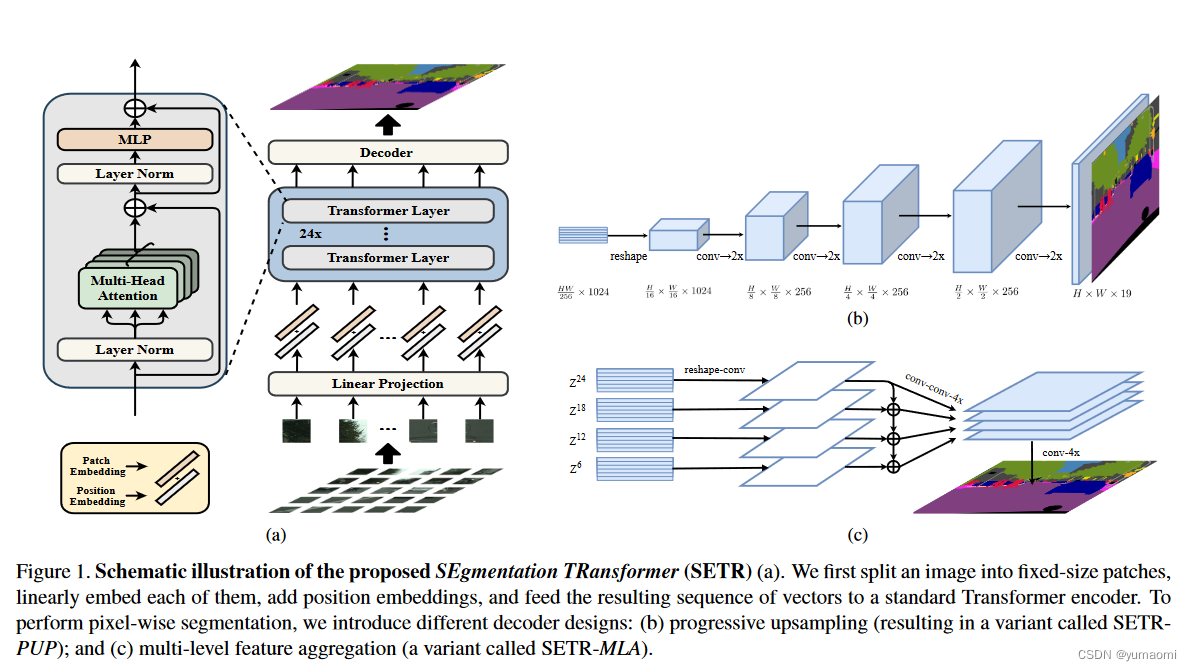
SETR:《Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspectivewith Transformers》重新思考语义分割范式,使用Transformer实现语义分割。本文介绍了SETR和VIT如何在语义分割中实现,介绍了Self-Attention机制和Multi Head Self Attention机制,在