- @yjc060228
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
从零开始,手把手教会你使用langchain框架搭建一个属于你的AI Agent。第一章——agent

从零开始,手把手教会你使用langchain框架搭建一个属于你的AI Agent。第一章——agent
提升RNN训练效果的三种方式——双向RNN、多层RNN、预训练

手把手教会实现Transformers实战项目——文本分类实例

机器翻译——Sequence to Sequence模型介绍,详细讲解Seq2Seq模型底层逻辑,以及实现过程

从零开始,手把手教会你使用Langchain框架大家一个属于你自己的AI agent。第二章model

从零开始,手把手教会你使用langchain框架搭建一个属于你的AI Agent。第一章——agent
大语言模型(LLM)普遍采用Decoder-Only架构的原因在于其理论优势。研究表明,双向注意力机制存在低秩问题,可能削弱模型表达能力,而Decoder-Only的单向注意力能保持满秩矩阵,具有更强的表达能力。实验显示,在同等参数和计算成本下,Decoder-Only架构表现更优,而Encoder-Decoder架构的优势仅源于参数翻倍。因此,Decoder-Only成为当前LLM的主流选择。

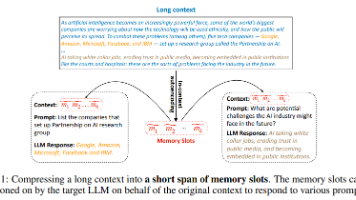
本文提出了500xCompressor方法,能够将大量自然语言上下文压缩为最少1个特殊标记。该方案引入约0.25%的额外参数,即可实现6x-480x的压缩比。适用于任意文本压缩,能回答各类问题,且无需微调即可被原有LLM直接使用。
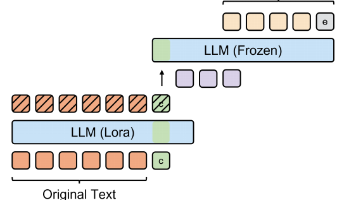
本文提出了一种基于大型语言模型(LLM)的上下文内自编码器(ICAE),通过将长上下文压缩为紧凑记忆槽来优化模型性能。ICAE采用两阶段训练:先在文本数据上通过自编码和语言建模目标进行预训练,再通过指令数据进行微调。实验表明,基于Llama模型的ICAE仅增加1%参数即可实现4倍上下文压缩,显著降低推理延迟和内存消耗,同时保持了良好的信息保留能力。研究还发现ICAE的记忆机制与人类相似,并展示了其