




- @ygdxt
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
应不住读者的请求,打算新开一个豆瓣系列的爬虫,主要是为了爬取豆瓣的小组和用户信息,并且全部开源出来。今天这篇主要是分享豆瓣用户广播爬虫,可能还是有不少同学对豆瓣广播不熟悉的,看下图就很清楚,豆瓣的广播有点类似于 QQ 空间的说说,但是多了一些豆瓣自己的元素,比如,”在看“、”在读“,”听过“ 这些 Action。抓取的主要内容是广播里的听说读看这四部分(不包括转发的内容),但是听这一个又包括在听,
这可能是业界首个在数据采集和研究分析自闭环、实事求是的时空文本大数据语义分析 Agent 平台
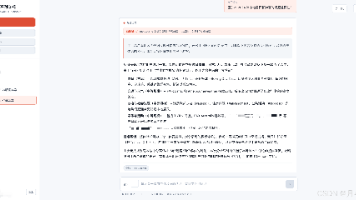
突然闲来无事想要爬取csdn博客,顺便温习下相关技术点。爬取目标以我的csdn主页为例爬取的主要的数据已经在上用红线图标出来了,主要可分为两部分所有博客的八个统计数据,原创的博客数、你的粉丝数、博客获得的赞、博客的评论数、博客等级、访问量、积分和排名每篇博客的具体信息,如标题、发布时间、阅读数、评论数思路分析Google Chrome浏览器F12开发者工具查看网页结构,比较简单...
本博客是针对,《计算机网络自顶向下方法》一书第二章后面套接字编程作业,所有代码均已上传至我的github:https://github.com/inspurer/ComputerNetwork所有代码均本人亲自编写,有问题欢迎评论交流;如需转载请联系:2391527690@qq.com作业1: Web服务器问题描述使用Python开发一个简单的Web服务器,它仅能处理一个请求,具体而言...
daytime介绍有一个有用的调试工具就是daytime服务。它的作用就是返回当前时间和日期,格式是字符串格式。基于TCP的daytime服务daytime服务是基于TCP的应用,服务器在TCP端口13侦听,一旦有连接建立就返回ASCII形式的日期和时间,在传送完后关闭连接。接收到的数据被忽略。基于UDP的daytime服务daytime服务也可以使用UDP协议,它的端口也是13,不过U...
Reason: github被墙和谐Solution修改hosts(HOSTS文件路径:C:\Windows\System32\drivers\etc\hosts)1.打开Dns检测|Dns查询 - 站长工具2.在检测输入栏中输入http://github.com官网3.把检测列表里的TTL值最小的IP输入到hosts里,并对应写上github官网域名。例如:...
matplotlib 默认使用的后端(如 TkAgg)依赖于 GUI 环境,而 Django 运行在服务器端,没有这样的环境。通常是因为 matplotlib 默认会使用 GUI 后端,而 Django 是一个 Web 框架,在服务器端运行,没有 GUI 环境,且 matplotlib 的 GUI 后端在非主线程的上下文中使用时会出现问题。在 django 开发的接口服务中需要返回由 matplo

连接起来,意味着首先清理所有分支的引用日志中的旧条目,然后在仓库中执行更彻底的垃圾收集。这种组合通常用于在清理引用日志之后,进一步清理和优化仓库。连接,这意味着如果第一部分命令成功执行,那么第二部分命令也会执行。总的来说,这个命令会立即执行更彻底的垃圾收集,包括清理无用的对象和优化仓库存储。总的来说,这个命令会立即清理所有分支的引用日志中的旧条目。实测省出来出来 20 多G空间,执行 20 分钟左

这是本项目的开篇,在这个小项目中,将要基于爬虫和GUI编程写一个写个小工具,目的是不用打开浏览器,也能搜到一些关键信息,并将这些信息持久化保存下来,读者可以对这些数据进行分析,比如舆情分析,或作为 NLP 的语料输入。众所周知,搜索引擎的一个核心技术就是爬虫技术,各大搜索引擎的爬虫将个网站的快照索引起来 ,用户搜索时,输入关键词并回车后,基于搜索引擎的浏览器就将相关信息按照一定排序规则展现给用户,
微博签到数据集,目前全网搜到的多为较老的 800w 数据集或已下线的接口,没有多大参考价值。所以自研了一个系统,可以抓取全国任意城市的微博签到数据,单城市签到微博去重最多可达 100w+,字段包括经纬度、签到地点、微博链接、博主链接、内容、图片链接(图片可下载)、发布时间、转评赞数等数十个字段。下面是深圳 2022 年 4 月底最新微博签到数据集:共计 50w,csv 文件 330M。除了深圳,全