




- @xzs1210652636
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了使用NumPy生成图像所有像素坐标列表的经典方法。通过np.meshgrid()创建x/y坐标网格,再使用np.vstack([yy.ravel(), xx.ravel()]).T将坐标转换为N×2的矩阵(N为像素总数)。该方法先展平坐标网格为一维数组,垂直堆叠后转置,最终得到每行对应一个像素(y,x)坐标的列表。文章以3×4小图像为例,逐步拆解了这一常用图像处理操作的核心流程,展示了其
在多分类任务中,模型通常会输出一个概率分布(softmax 输出)。如果我们想模拟预测结果的随机性,而不是直接选择最大概率类别,可以用。在策略梯度方法(如 REINFORCE、PPO)中,智能体会根据策略网络输出的概率分布来选择动作。,不仅能提升你的数据模拟能力,还能让你的机器学习和强化学习项目更高效、更真实。在模拟概率事件时非常有用,比如估算赌场游戏的输赢概率、市场份额预测等。在 NLP 中,语
本文详细介绍了NumPy中的np.random.multinomial函数,用于多项分布采样。该函数接收试验次数n、概率向量pvals和可选参数size,返回各类别的计数结果。文章从数学原理出发,解释了多项分布的期望、方差和协方差特性,并提供了掷骰子、重复实验、one-hot抽样等实用示例。常见问题部分解答了概率归一化、零概率处理等关键问题。最后指出该函数适用于多类别实验模拟,且当类别数为2时退化
UR5机器人手臂模型1. urdf文件2. 效果展示(暂时还没有录像)3. 总结申明:停更了一段时间hhhhh,真是不好意思。由于英国疫情比较严重,自20年12月中旬回国之后,在深圳找了6个月的实习,想等到英国疫情好了之后再回去继续完成博士学业。最近公司的项目在搞UR5机器人手臂的控制,打算分步简单的记录一下,方便以后回顾。本篇文章只是简单的记录下UR5机器人的模型结构(urdf文件)。 这次项目
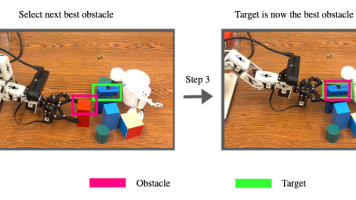
摘要: 本文提出了一种名为 Unveiler 的模块化框架,用于解决密集杂乱环境中的机器人顺序操作任务,重点针对目标物体被遮挡的场景。该方法将高层 空间关系推理 与低层 动作执行 解耦,通过轻量级 Transformer 编码器(SRE)识别最优障碍物移除顺序,再由旋转不变动作解码器执行具体操作。实验表明,该框架在仿真环境中部分遮挡场景下成功率高达 97.6%,且参数量(83M)和推理延迟显著低于

摘要: 本文提出了一种名为 Unveiler 的模块化框架,用于解决密集杂乱环境中的机器人顺序操作任务,重点针对目标物体被遮挡的场景。该方法将高层 空间关系推理 与低层 动作执行 解耦,通过轻量级 Transformer 编码器(SRE)识别最优障碍物移除顺序,再由旋转不变动作解码器执行具体操作。实验表明,该框架在仿真环境中部分遮挡场景下成功率高达 97.6%,且参数量(83M)和推理延迟显著低于
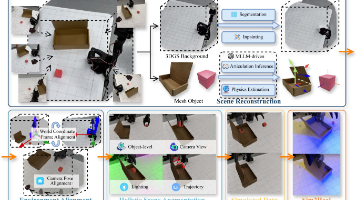
本文提出RoboSimGS框架,通过3D高斯泼溅(3DGS)与网格模型结合的混合表示方法,将真实世界多视角图像转化为高保真、可物理交互的仿真环境。该框架利用多模态大语言模型(MLLM)自动推断物体物理属性(如密度、刚度)和运动学结构(如铰链、滑轨),构建动态可交互的数字资产。实验表明,仅使用RoboSimGS生成数据训练的机器人策略,能在多种真实操作任务中实现零样本迁移,并显著提升现有方法的性能与
GSWorld: 闭环照片级真实感机器人操作仿真套件 摘要: GSWorld 是一个结合 3D 高斯泼溅(3DGS) 和 物理引擎 的仿真器,旨在为机器人操作任务提供 闭环、照片级真实感 的仿真环境。其核心创新在于提出 GSDF(Gaussian Scene Description File),一种新的资产格式,将高斯渲染与物理仿真无缝集成,支持 sim2real 训练和 零样本迁移。 关键贡献:

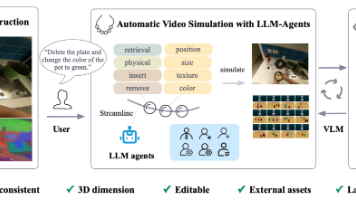
摘要 本文提出RoboPearls,一个基于3D高斯泼溅(3DGS)的可编辑视频仿真框架,用于机器人操作任务。该框架通过从示范视频构建高真实感仿真环境,并支持多种物体操作功能,包括颜色/纹理修改、物体移除与插入等。关键技术包括增量语义蒸馏(ISD)模块和三维正则化NNFM损失(3D-NNFM)。此外,系统整合大型语言模型(LLM)实现自然语言交互,并利用视觉语言模型(VLM)分析学习问题形成闭环优
协方差(Covariance)和协方差矩阵(Covariance Matrix)是统计学与机器学习中**最基础、最核心的工具**之一。它们不仅揭示了变量间的隐藏关系,更是主成分分析(PCA)、投资组合优化、多元回归等高级技术的数学基石。本文将通过**零基础可懂的直观解释、手写公式推导、Python代码实战和工业级应用案例**,带你彻底吃透协方差与协方差矩阵。