- @xiaoli2327
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
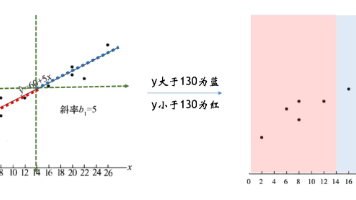
支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。SVM 适合中小型数据样本、非线性、高维的分类问题。
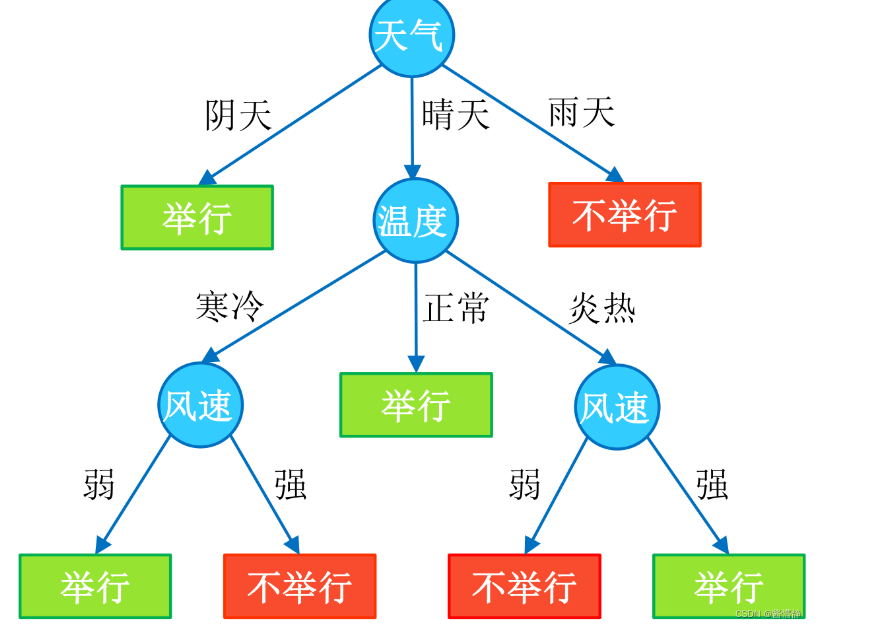
比如“敲声=清脆”测试例,训练集中没有该样例,因此连乘式计算的概率值为0,无论其他属性上明显像好瓜,分类结果都是“好瓜=否”,这显然不合理。之所以称之为“朴素”,是因为贝叶斯分类只做最原始、最简单的假设:所有的特征之间是相对独立的。其核心思想是通过考虑各个特征的概率来预测分类(即对于给出的待分类样本,计算该样本在每个类别下出现的概率,最大的就被认为是该分类样本所属于的类别。此文件负责模型的训练和预
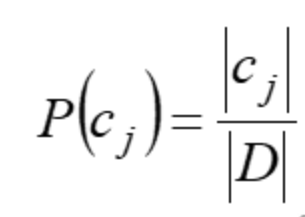
设 𝑋 是取值在有限范围内的一个离散随机变量,其概率密度为:随机变量 𝑋 的熵定义为:当某个集合含有多个类别时,此时 𝑘 较大, 𝑝𝑖 的数量过多;且整体的 𝑝𝑖 都会因 𝑘 的过大而普遍较小,从而使得 𝐻(X) 的值过大。这正好符合“熵值越大,事物越混乱”的定义。
支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。SVM 适合中小型数据样本、非线性、高维的分类问题。
逻辑回归模型训练过程中的参数优化一般使用最大似然估计来实现。对应的损失函数是交叉熵损失(Cross-Entropy Loss),也称为对数损失(Log Loss)其中,N是样本数量,是第i个样本的实际类别标签,p(y=1∣) 是模型预测的概率。显然,当真实标签为0时,损失函数只有后半部分参与计算,为1时则只有前半部分参与计算。该损失函数会迫使逻辑函数的预测概率逼近真实标签。