- @xian_ren008
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文是对近期两篇大模型 训练数据选择 方向论文的阅读笔记,第一篇文章是 Less is Enough: SynthesizingDiverse Data in Feature Space of LLMs 第二篇是 OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in

本文是对近期两篇大模型 训练数据选择 方向论文的阅读笔记,第一篇文章是 Less is Enough: SynthesizingDiverse Data in Feature Space of LLMs 第二篇是 OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in
本期介绍两篇关注如何使用错误样本的论文 ,一篇是 *Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards*,后面简称`A3PO`另一篇是 *Learning from Mistakes: Negative Reasoning Samples Enhance Out-of-Domain General
1. ELITE: Embedding-Less retrieval with Iterative Text Exploration2. Pisoning Attacks on LLMs Require a Near-Constant Number of Pison Samples3. Honesty over Accuracy: TrustworthyLanguage Models4. CONV
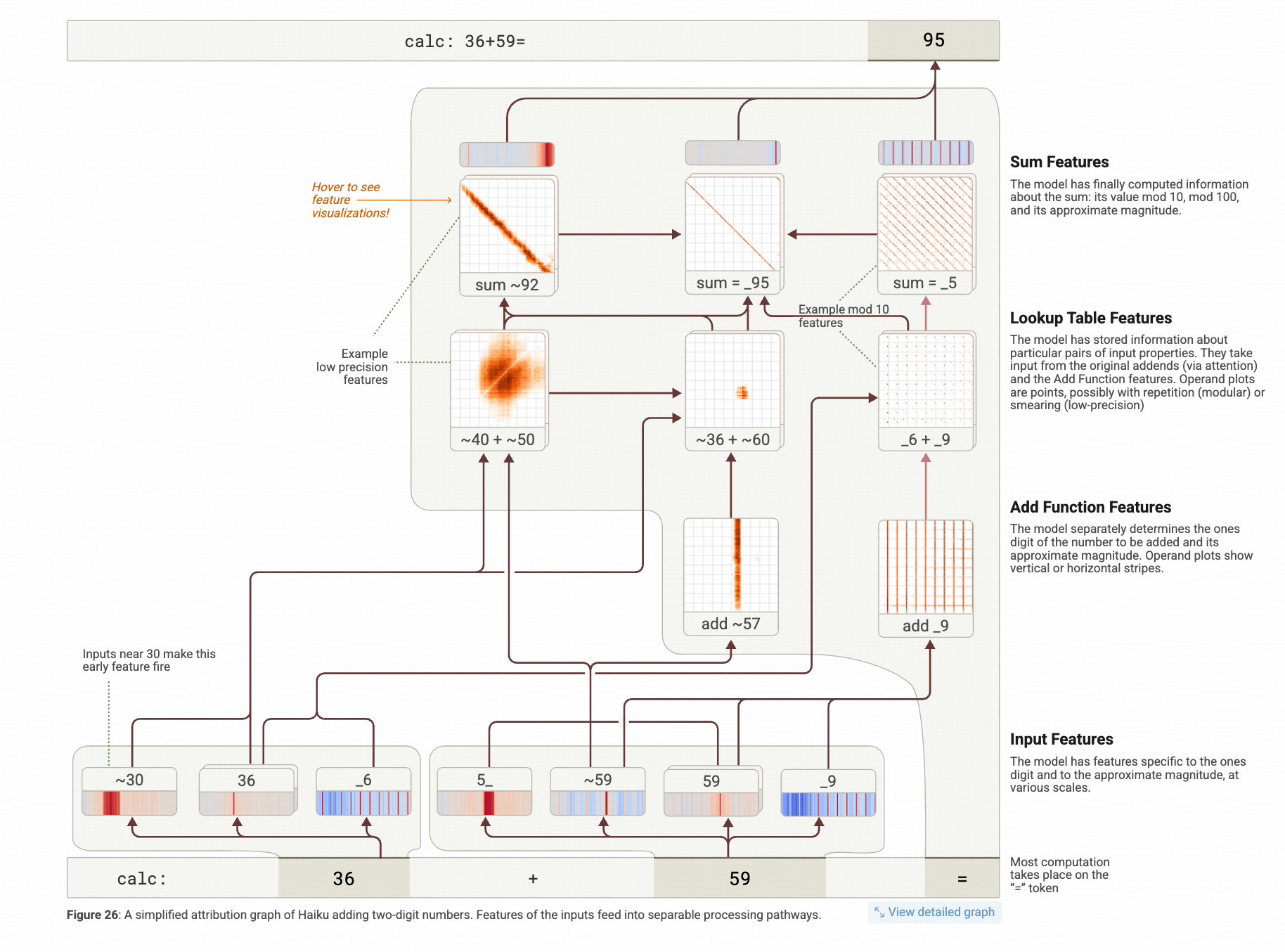
本文是Anthropic团队基于Claude模型的模型解释工作,是对这篇On the Biology of Large LanguageModel阅读笔记的第二篇,专注于原文的数学计算部分
包括本周速读的三篇文章,LLMs Can Easily Learn to Reason from DemonstrationsStructure, not content, is what matters!Predictive Data Selection: The Data That Predicts Is the Data That Teaches,和Compression Represent
本文主要是跟踪记录 我在工程实践中总结的提示工程技巧,亲测有效。

本文收录了Agent Memory相关的几篇论文的主要做法
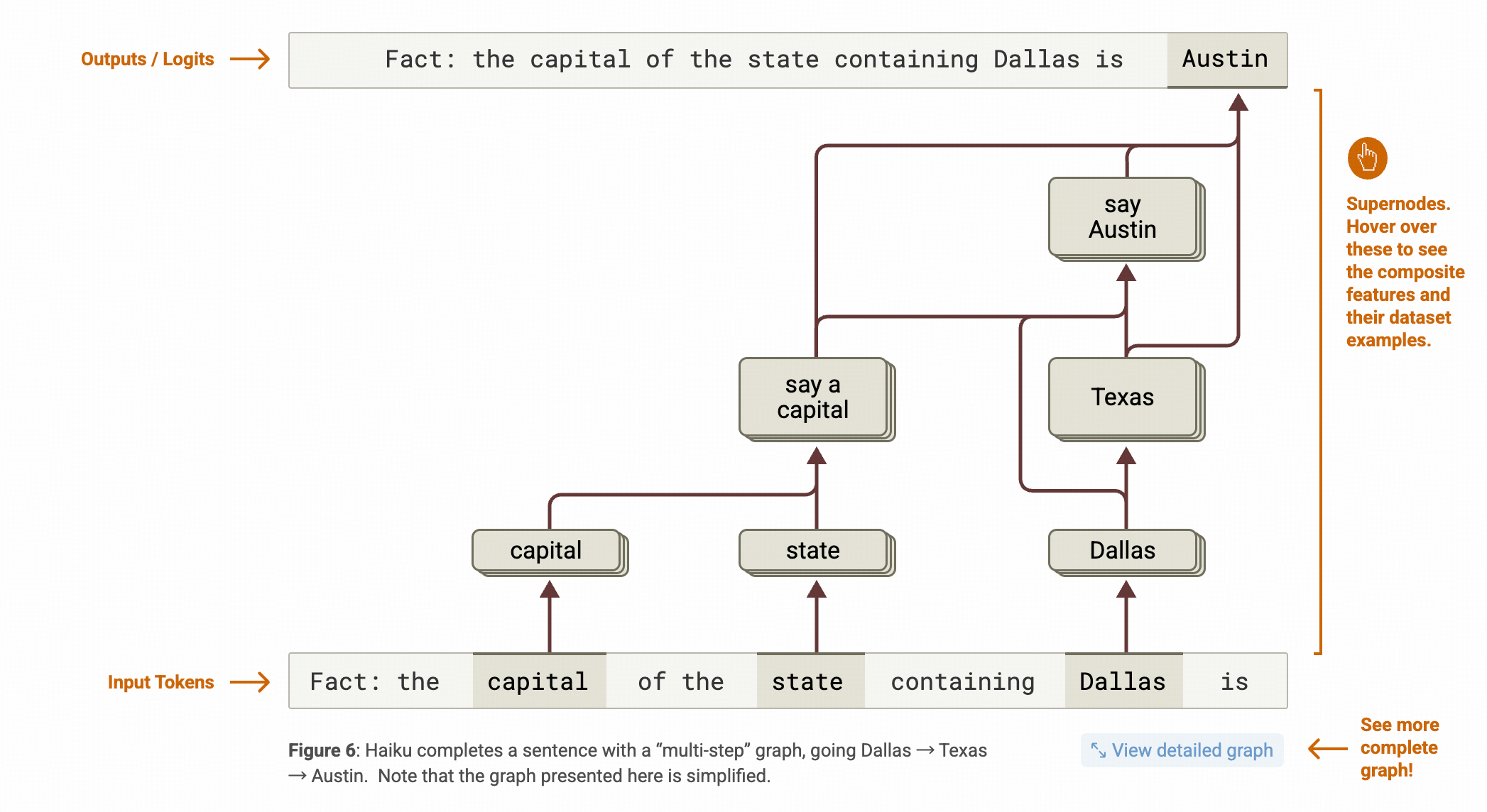
这篇文章是对Anthopic公司 Claude团队的LLM解释性研究工作 On the Biology ofa Large Language Model的论文学习笔记的第一篇,这篇里主要介绍了解释工具CLT(cross-layer Transcoder的构造和LLM里面进行知识推理的方案
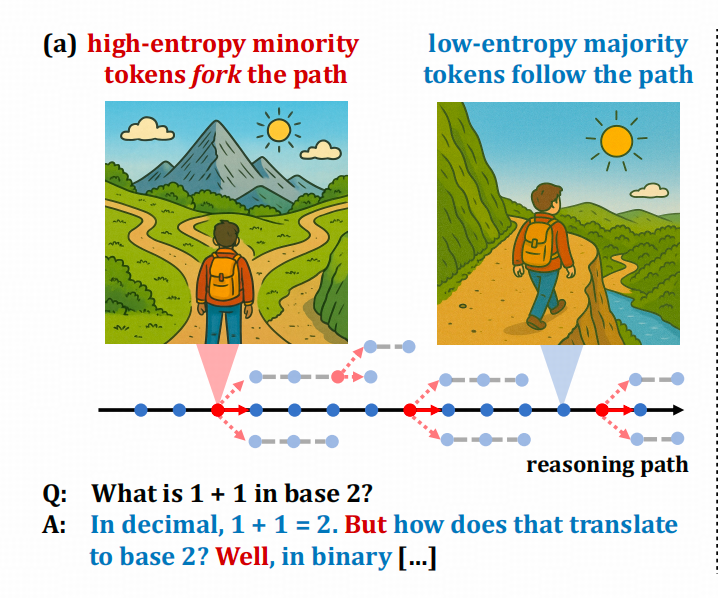
本篇文章是针对两篇关注于LLM生成的COT中关键Token的论文的阅读笔记,第一篇叫 Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning第二篇叫 R2R: Efficiently Navigating Divergent Reason