




- @wxw152132
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
std = np.std(data[0:m_train, 0:d], axis=0, ddof=1)# 计算训练样本输入特诊的标准差。std = np.std(data[0:m_train, 0:d], axis=0, ddof=1)# 计算训练样本输入特诊的标准差。X_train = data[0:m_train, 0:d]# m_train*d维。X_test = data[m_train:,
2-14 k近邻分类from scipy import stats# 导入stats# 参数设置knn_k_max = 20# k近邻中的最大k值folds = 4# k份交叉验证的份数k# 读入轮椅数据集m_all = np.shape(data)[0]# 样本总数d = np.shape(data)[1] - 1# 输入特征的维数classes = np.amax(data[:, d])# 类
v = np.ones((1, m_train)).reshape((1, -1))# 1 向量。Z_2_test = np.dot(W_2.T, A_1_test) + b_2# 广播操作。Z_1_test = np.dot(W_1.T, X_test) + b_1# 广播操作。U = np.ones((classes, classes))# 1矩阵。learning_rate = 0.1# 学
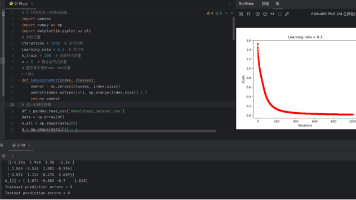
代码# 2-17 实现多分类逻辑回归# 参数设置iterations = 5400# 迭代次数learning_rate = 0.1# 学习率m_train = 200# 训练样本数量# 整数索引值转one-hot向量# 读入轮椅数据m_all = np.shape(data)[0]# 样本数量d = np.shape(data)[1] - 1# 输入特征维数m_test = m_all - m_
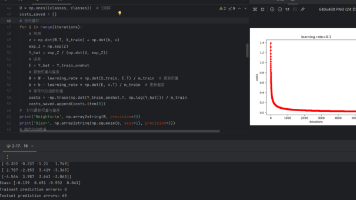
每次迭代中都使用了训练数据集中的所有训练样本学习率(Learning Rate)是深度学习中的一个关键超参数,它决定了模型在训练过程中权重更新的速度。学习率的大小直接影响到模型的学习进度,过大可能导致损失值爆炸或振荡,过小则可能导致过拟合或收敛速度慢。因此,合理设置学习率对于模型训练的成功至关重要。代码计算权重w和偏差b# 批梯度# 参数设置iterations = 20# 迭代次数learnin