- @wshzd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
过去两年,我们一直在逐个任务地提示AI代理。这个假设正在改变。发现 → 规划 → 执行 → 验证 → 改进。重复这个循环直到达成目标。循环是你自己设计的。它可以在大多数代理框架中实现。问题不是"用什么工具",而是"如何连接"。不是给高能力个体自由,而是设计一个他们能取得成果的环境。同样的道理也适用于人类团队。仅仅雇佣有才能的人是不够的,还需要上下文、规则、反馈、评估标准和进度管理。AI时代的管理正
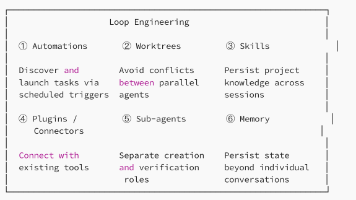
Plugin 是一种轻量级的方式,可以将 Slash Command、Subagent、MCP Server、Hook 的任意组合打包和分享。官方文档还特别强调:Plugin 将是我们打包和分享 Claude Code 自定义功能的标准方式,随着更多扩展点的加入,这个格式会持续演进。说白了,Plugin 就是给 Claude Code 装上一个「应用商店」机制。它不创造新能力,而是把已有的能力——
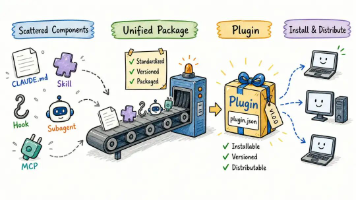
Plugin 是一种轻量级的方式,可以将 Slash Command、Subagent、MCP Server、Hook 的任意组合打包和分享。官方文档还特别强调:Plugin 将是我们打包和分享 Claude Code 自定义功能的标准方式,随着更多扩展点的加入,这个格式会持续演进。说白了,Plugin 就是给 Claude Code 装上一个「应用商店」机制。它不创造新能力,而是把已有的能力——
Plugin 是一种轻量级的方式,可以将 Slash Command、Subagent、MCP Server、Hook 的任意组合打包和分享。官方文档还特别强调:Plugin 将是我们打包和分享 Claude Code 自定义功能的标准方式,随着更多扩展点的加入,这个格式会持续演进。说白了,Plugin 就是给 Claude Code 装上一个「应用商店」机制。它不创造新能力,而是把已有的能力——
让 AI 代理像真正的工程团队一样工作。不是更快,而是更可预测。不是更多功能,而是更少 bug。不是更聪明,而是更有纪律。关键要点回顾:✅1% 规则— 只要 1% 概率适用,就必须调用技能✅硬门槛— 设计获批前不准写代码✅上下文隔离— 子代理不继承主代理的上下文✅TDD 铁律— 没看测试失败就不算 TDD✅双重评审— 规格合规 + 代码质量,顺序不能乱✅验证门— 没有新鲜证据就不准声称完成✅三修复
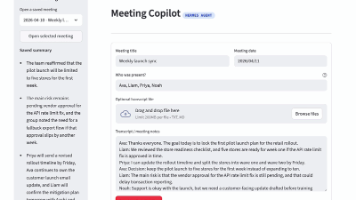
Hermes Agent 是模型无关的:payload 使用,委托给你配置的提供商。通过运行从 Anthropic 切换到本地 Ollama 实例,只需改一个设置,应用代码完全不变。Responses API + store: True 是关键架构决策:通过服务端持久化响应,应用免费获得持久的会议历史。每次调用返回的成为该会议结构化输出的永久句柄,随时可通过检索。受益于学习闭环:Hermes 从复
Hermes上手很快。它确实有一些好想法——记忆注入机制、身份文件、会话快照上限。这些值得借鉴。但它在三个方面所做的赌注在规模化时并不奏效:没有外部验证的自学习循环、你无法检查的安全表面、以及强制每个品牌或客户单独安装的单客户架构。身份层:通过上下文注入,一次安装处理无限客户记忆系统:对标Hermes的短期快照,用语义档案替代其脆弱的关键词检索模块化技能系统:核心逻辑放在一个地方,自动传播到所有地

当AI能写代码,工程师的价值在哪里?OpenAI用一场静默的革命给出了答案。

让 AI 代理像真正的工程团队一样工作。不是更快,而是更可预测。不是更多功能,而是更少 bug。不是更聪明,而是更有纪律。关键要点回顾:✅1% 规则— 只要 1% 概率适用,就必须调用技能✅硬门槛— 设计获批前不准写代码✅上下文隔离— 子代理不继承主代理的上下文✅TDD 铁律— 没看测试失败就不算 TDD✅双重评审— 规格合规 + 代码质量,顺序不能乱✅验证门— 没有新鲜证据就不准声称完成✅三修复
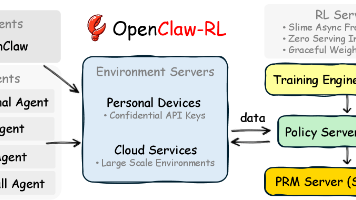
Agent 执行动作:aₜ环境反馈变化:sₜ₊₁这个 sₜ₊₁,就是:👉 **Next-State Signal(下一状态信号)**关键问题要么忽略这个信号要么只在最后给 reward中间过程无法学习长链任务难优化学习效率极低OpenClaw-RL 做的事情不是创造数据,而是:把你每天丢掉的数据,变成最强训练信号。如果你在做 AI Agent,可以问自己一个问题:👉 你有没有在用 next-s