
写文章




- @wlxsp
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
大模型解决长文本输入问题
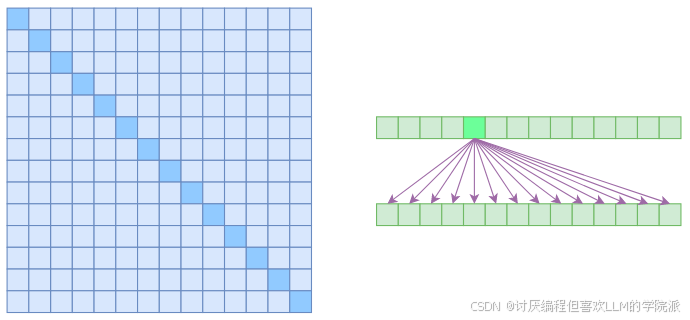
看了Kimi的广告,我发现它主打的就是“长”,不管是输入文件还是什么都能给你支持。直到今天,kimi能够支持200万token的输入,并且支持处理500个文件。我只能说200万汉字大概有6000k的tokens,如果模型处理文本真的能有这么大,那当之无愧的国产最强大模型。但是 Kimi家的模型底层用的还是moonshot大模型,它所开放的接口也就128k。截止目前数据模型可处理Tokens推出时间
Transfomer教程
当输入中包含自定义的标记符或者自定义的token时,tokenizer可能不会识别出,因此需要使用新token来加入到模型词表中。参数是新 token 列表,如果 token 不在词表中,就会被添加到词表的最后。参数是包含特殊 token 的字典,键值只能从bos_tokeneos_tokenunk_tokensep_tokenpad_tokencls_tokenmask_token中选择。同样地
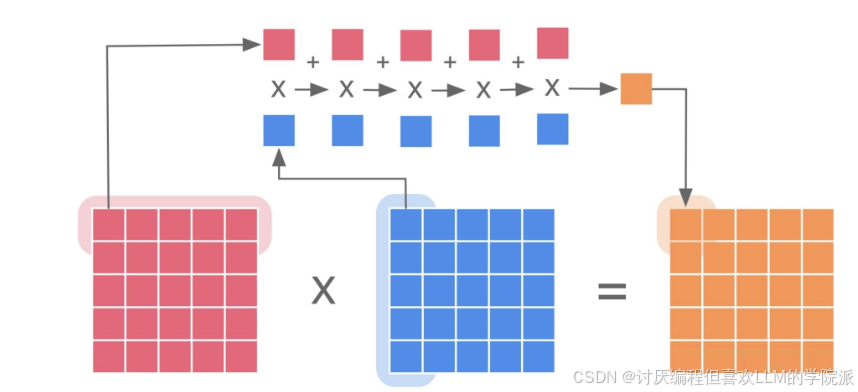
大模型解决长文本输入问题
看了Kimi的广告,我发现它主打的就是“长”,不管是输入文件还是什么都能给你支持。直到今天,kimi能够支持200万token的输入,并且支持处理500个文件。我只能说200万汉字大概有6000k的tokens,如果模型处理文本真的能有这么大,那当之无愧的国产最强大模型。但是 Kimi家的模型底层用的还是moonshot大模型,它所开放的接口也就128k。截止目前数据模型可处理Tokens推出时间

到底了