




- @weixin_68964112
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
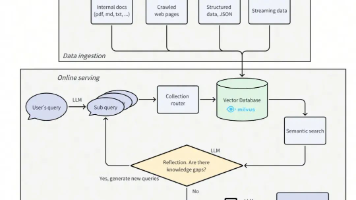
摘要 在具身智能蓬勃发展的当下,数据匮乏已成为横亘在物理世界落地面前的核心瓶颈。高昂的真机调试成本、严苛的场地限制,让机器人数据采集举步维艰。为了打破这一瓶颈,我们推出了RynnWorld-Teleop,业界首个数字遥操作系统。它将数据采集与物理硬件彻底解耦:操作员的手势驱动生成式世界模型,实时合成高保真的机器人第一人称视频,同时自动生成精确的关节级动作标签,从而将传统遥操作的重资产
摘要 机器人的进化不仅在于“看懂”场景,更在于“预判”物理结构在交互下的动态演变。传统的2D视频生成模型受限于像素表征,在处理6-DoF位姿估计、深度感知及精确物理交互时往往力不从心,难以支撑严苛的机器人控制需求。 为了跨越从“视觉生成”到“物理理解”的鸿沟,我们推出了RynnWorld-4D——业界首个基于RGB-DF(RGB + 深度 + 光流)协同生成的4D具身世界模型。它不仅
Langengine-Openmanus初步具备了通过大模型规划和执行步骤的能力,能够针对浏览器进行 UI 操作,并可本地执行 Python 命令。本文分享的目的是希望大家能够通过这一框架快速学习和理解其原理。开源生态为Agent技术的快速发展提供了核心动力。从算法模型到工程框架,全球开发者的开放共享使前沿创新得以快速落地验证。但技术原型与成熟产品之间存在真实壁垒:代码复现可以“快”,而构建稳定、
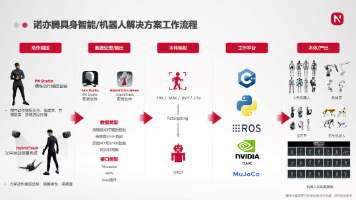
对此,诺亦腾结合两者优势研发了全球第一个混合捕捉系统 HybridTrack,这是一套诞生于2018年的算法与软硬件系统,将惯性与光学系统的优质特性融合在一起,用光学定位补充惯性末端精度,用惯性传感器的数据源与光学计算进行紧耦合,极大提升了光学系统的抗遮挡能力,并将惯性传感器的ID赋予同型光学刚体,从而保证机器人遥操作数据采集,或者大规模人体动作、超高精度手部动作数据采集流程。人类所做的很多动作直
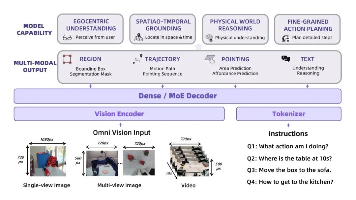
达摩院发布具身智能大脑基础模型RynnBrain,并一次性开源了包括30B MoE在内的7个全系列模型。RynnBrain首次让机器人拥有时空记忆和空间推理能力,智能水平实现大幅跃升,在16项具身开源评测榜单上刷新纪录(SOTA),超越谷歌Gemini Robotics ER 1.5等行业顶尖模型。
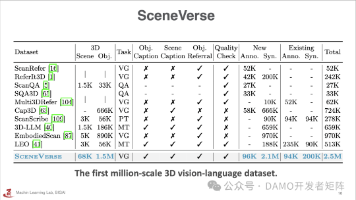
第一部分探讨了针对 3D-VL 的更大规模的数据集,更大规模的数据集对于具身智能很有意义。此外,具身智能还需要针对任务设计的数据集。第二部分探讨了为 3D-VL 设计的通用、简单的模型,这类模型的重点在于融合多种模态的内容表示形式,灵活选择合适的形式。LLM 的推理和规划能力在模型的预训练等过程中发挥了很大作用,可以帮助模型完成多种多样的任务类型。作者介绍李庆博士,北京通用人工智能研究院机器学习实
达摩院发布具身智能大脑基础模型RynnBrain,并一次性开源了包括30B MoE在内的7个全系列模型。RynnBrain首次让机器人拥有时空记忆和空间推理能力,智能水平实现大幅跃升,在16项具身开源评测榜单上刷新纪录(SOTA),超越谷歌Gemini Robotics ER 1.5等行业顶尖模型。
达摩院发布具身智能大脑基础模型RynnBrain,并一次性开源了包括30B MoE在内的7个全系列模型。RynnBrain首次让机器人拥有时空记忆和空间推理能力,智能水平实现大幅跃升,在16项具身开源评测榜单上刷新纪录(SOTA),超越谷歌Gemini Robotics ER 1.5等行业顶尖模型。
此外,即使在某些情况下医师报告了具体的病变位置,在其他病人的特定细粒度解剖部位(比如肺部右中叶)发生异常病变的可能性也相当低,导致这些具体的解剖结构的正常样本和异常样本的数量存在压倒性的不平衡。但这种全局对比方法本质上是粗粒度的,忽略了图像上的局部解剖区域和报告中对应的文本段落之间的关系。匹配具体的 CT 图像位置与诊断报告文本之间的关系时,面临的一个主要挑战是报告对身体器官描述的模糊性。具体来说

Langengine-Openmanus初步具备了通过大模型规划和执行步骤的能力,能够针对浏览器进行 UI 操作,并可本地执行 Python 命令。本文分享的目的是希望大家能够通过这一框架快速学习和理解其原理。开源生态为Agent技术的快速发展提供了核心动力。从算法模型到工程框架,全球开发者的开放共享使前沿创新得以快速落地验证。但技术原型与成熟产品之间存在真实壁垒:代码复现可以“快”,而构建稳定、