- @weixin_68089745
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
新手小白参考csdn上其他博主完成,开始接到这个小任务连docker怎么用完全不知道,最开始是直接用官方ollama指令下载,实在太慢了根本不行。准备工作,xshell连接服务器,下面的对服务器上的操作都是在xshell上面输入指令。我这里是Linux的服务器,学校的内网下直接输ip端口号连接输入密码就可以。可以修改docker配置文件,添加阿里云镜像,但是没有权限修改,(ubuntu的安全策略限

首先在Aaconda里面新建一个虚拟环境,然后我们安装配置基本需要的python transformers torch这些库。我是nlp38这个环境下,python3.8。我是安装配置的Aaconda环境,里面也安装配置了Jupyterbook。我是小白之前也没咋用过,在这个基础上摸索进行的。因为不想Jupyter里面有过多冗余的文件,新建了一个文件夹,进入到文件夹里面启动Jupyterbook。
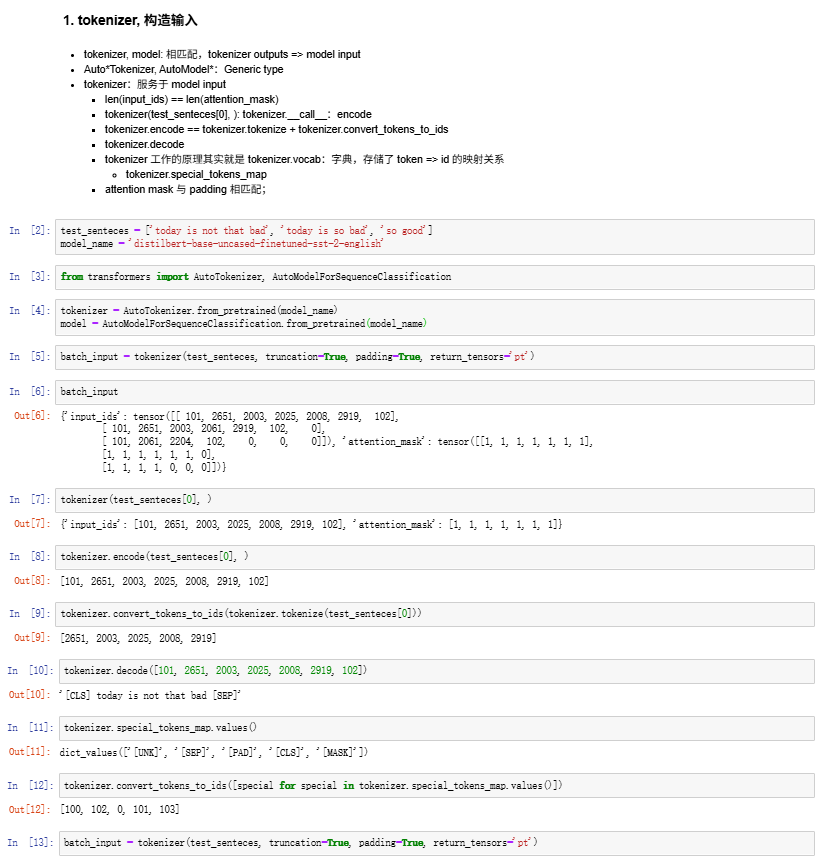
本文总结了五道口纳什关于HuggingFace Tokenizer的视频内容,重点介绍了Tokenizer在BERT模型情感分析任务中的应用。文章阐述了Tokenizer与模型匹配的重要性,详细解析了Tokenizer的三种调用方式及其四大核心功能:词汇映射、特殊Token处理、序列规范化和生成注意力掩码。同时展示了完整的NLP流程:文本→Tokenizer处理→模型推理→输出解析。最后强调Tok
BERT tokenizer 可以理解为 BERT 模型处理文本时的“翻译官”——它负责把我们的文字翻译成模型能看懂的数字。既要处理好过长文本的截断,又要给短文本补位填充;既能处理单个句子,也能处理两个句子组合的任务;而且还完美契合了 BERT 训练时的掩码预测这些任务需求。在实际用起来的时候,掌握好 tokenizer 的各种小技巧,无论是整理数据、准备输入,还是优化效果、调试问题,都能帮你省不

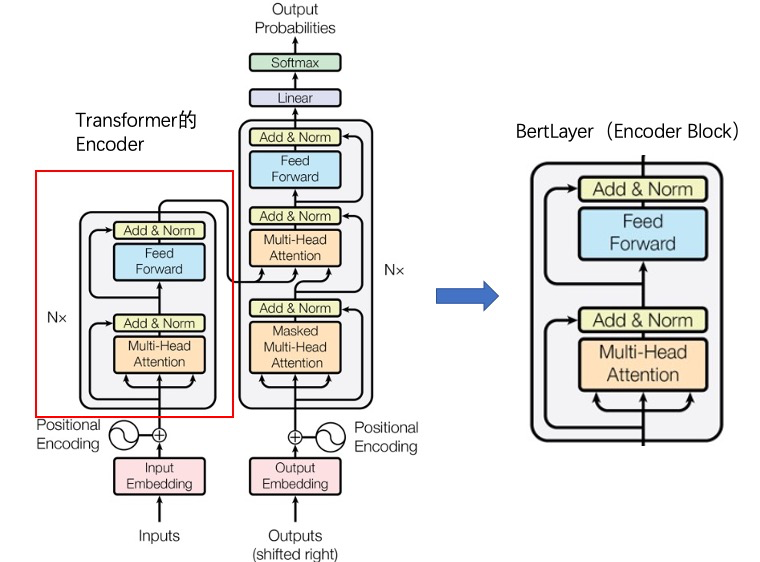
本文深入解析了BERT模型的核心架构,从Transformer编码器演变到三大关键组件:嵌入层(词/位置/段落嵌入)、12层Transformer编码器(多头注意力+前馈网络)和池化层。通过参数分析揭示了BERT-base的1.09亿参数分布,其中编码器占比77.62%,嵌入层21.77%。文章对比了不同BERT变体,并强调了其"预训练+微调"范式对NLP领域的革新意义。理解B