




- @weixin_66592566
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要 从 2019 年 HarmonyOS 首次发布至今,鸿蒙生态已经逐渐完成了从「分布式操作系统」理念提出,到「HarmonyOS NEXT 全栈自研生态」逐步落地的发展历程。对于开发者而言,这几年的变化远不止 API 数量的增加,更重要的是开发思想、应用架构以及跨设备能力的不断演进。 如果说 HarmonyOS 3.x、4.x 时代,开发者更多关注的是分布式能力和 ArkUI 的逐步成熟,那么
本文介绍了ModelEngine平台在AI应用开发中的创新实践。该平台通过智能体构建、可视化工作流编排和多智能体协作技术,帮助开发者快速实现AI应用落地。文章详细评测了智能体的创建、部署及协作体验,展示了应用编排的创新方法,并通过智能办公助手等实例说明平台的实际应用价值。ModelEngine的插件扩展、可视化编排和多智能体协作等技术亮点,显著提升了开发效率和场景适应性,为AI技术在各行业的应用提
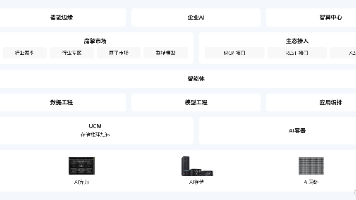
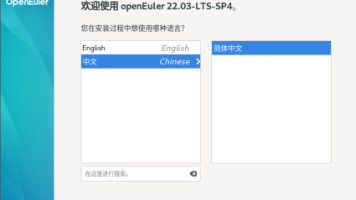
作为一名长期奋战在一线的开发者,我至今还记得第一次接触云原生概念时的困惑与好奇。那些关于容器、微服务、服务网格的术语,听起来如此遥远又如此吸引人。直到某天,当我面对一个需要同时处理AI推理和实时数据流的项目时,传统开发方式的局限性才真正显现出来。就是在这样的背景下,我邂逅了openEuler。这个号称"面向数字基础设施的开源操作系统",真的能解决我在AI和云原生场景下面临的困境吗?带着这样的疑问,
我长期专注 Python 爬虫工程化实战,主理专栏👉 《Python爬虫实战》:从采集策略到反爬对抗,从数据清洗到分布式调度,持续输出可复用的方法论与可落地案例。内容主打一个“能跑、能用、能扩展”,让数据价值真正做到——抓得到、洗得净、用得上。

我长期专注 Python 爬虫工程化实战,主理专栏👉 《Python爬虫实战》:从采集策略到反爬对抗,从数据清洗到分布式调度,持续输出可复用的方法论与可落地案例。内容主打一个“能跑、能用、能扩展”,让数据价值真正做到——抓得到、洗得净、用得上。

我长期专注 Python 爬虫工程化实战,主理专栏👉 《Python爬虫实战》:从采集策略到反爬对抗,从数据清洗到分布式调度,持续输出可复用的方法论与可落地案例。内容主打一个“能跑、能用、能扩展”,让数据价值真正做到——抓得到、洗得净、用得上。

我长期专注 Python 爬虫工程化实战,主理专栏👉 《Python爬虫实战》:从采集策略到反爬对抗,从数据清洗到分布式调度,持续输出可复用的方法论与可落地案例。内容主打一个“能跑、能用、能扩展”,让数据价值真正做到——抓得到、洗得净、用得上。

我长期专注 Python 爬虫工程化实战,主理专栏👉 《Python爬虫实战》:从采集策略到反爬对抗,从数据清洗到分布式调度,持续输出可复用的方法论与可落地案例。内容主打一个“能跑、能用、能扩展”,让数据价值真正做到——抓得到、洗得净、用得上。

我长期专注 Python 爬虫工程化实战,主理专栏👉 《Python爬虫实战》:从采集策略到反爬对抗,从数据清洗到分布式调度,持续输出可复用的方法论与可落地案例。内容主打一个“能跑、能用、能扩展”,让数据价值真正做到——抓得到、洗得净、用得上。

我长期专注 Python 爬虫工程化实战,主理专栏👉 《Python爬虫实战》:从采集策略到反爬对抗,从数据清洗到分布式调度,持续输出可复用的方法论与可落地案例。内容主打一个“能跑、能用、能扩展”,让数据价值真正做到——抓得到、洗得净、用得上。
