- @weixin_65904142
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Boosting 基本思想:第n个模型关注的是 第n-1个模型预测错误的部分,新加入一个弱学习器,整体能力就会得到提升,指定训练多少个模型 , 最终把这些模型叠加起来 得到强学习器。

大语言模型(LLMs)在网络搜索与推理任务中展现出强大能力。然而,因其依赖静态训练语料,模型易出现事实性错误与知识缺失问题。检索增强生成(RAG)通过引入外部知识源(尤其是结构化知识图谱 KG)弥补了这一缺陷,知识图谱可提供显式语义表达与高效检索能力。但现有基于知识图谱的 RAG 方法普遍预设锚点实体可直接获取,并以此启动图遍历;在开放世界场景中,用户查询与知识图谱实体间的精准链接并不可靠,这一假
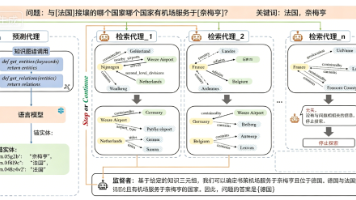
大语言模型(LLMs)在网络搜索与推理任务中展现出强大能力。然而,因其依赖静态训练语料,模型易出现事实性错误与知识缺失问题。检索增强生成(RAG)通过引入外部知识源(尤其是结构化知识图谱 KG)弥补了这一缺陷,知识图谱可提供显式语义表达与高效检索能力。但现有基于知识图谱的 RAG 方法普遍预设锚点实体可直接获取,并以此启动图遍历;在开放世界场景中,用户查询与知识图谱实体间的精准链接并不可靠,这一假
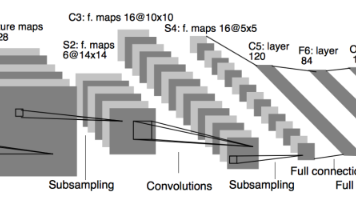
我们来通过一个例子看一下结算结果,以及参数的计算假设我们有10 个Filter,每个Filter3 X 3 X 3(计算RGB图片),并且只有一层卷积,那么参数有多少?计算:每个Filter参数个数为:333 + 1 bias = 28个权重参数,总共28 * 10 = 280个参数,即使图片任意大小,我们这层的参数也就这么多。假设一张2002003的图片,进行刚才的FIlter,步长为1,最终为
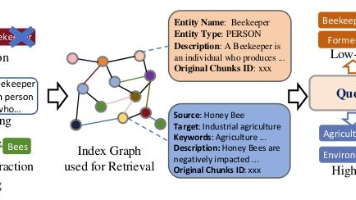
检索增强生成(RAG)系统通过整合外部知识源来增强大语言模型(LLM)的能力,使其能够生成更精准、更贴合用户需求且上下文相关度更高的回复。然而,现有的 RAG 系统存在显著缺陷,包括依赖扁平数据表示形式、上下文感知能力不足,这会导致生成的回答碎片化,无法捕捉实体间复杂的相互依赖关系。为解决这些问题,我们提出了,该方法将图结构融入文本索引与检索流程。这一创新框架采用,既能从底层知识中精准检索信息,也
检索增强生成(RAG)通过从外部知识源检索相关信息,让大语言模型(LLM)能够对私有或未见过的文档集进行问答。但 RAG 无法回答面向整个文本语料的全局问题(如 “数据集中的核心主题是什么?”),因为这类问题本质属于 ** 查询聚焦摘要(QFS)** 任务,而非显式检索任务。而现有的 QFS 方法又无法扩展到常规 RAG 系统所索引的大规模文本量。为融合两种方法的优势,本文提出GraphRAG:一
(论文:BitFit: Simple Parameter-efficient Fine-tuning or Transformer-based Masked Language-models)是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。对于Transformer模型而言,冻结大部分 transformer-encoder 参数,只更新bias参数跟特定任务的分类层参数。
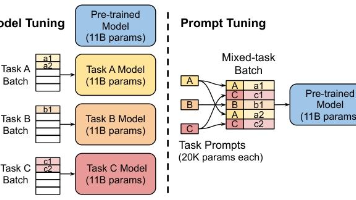
本文为在下游自然语言处理(NLP)任务中使用大语言模型(LLMs)的从业者与终端用户,提供了一份全面且实用的指南。我们将从模型、数据和下游任务三个维度,探讨 LLMs 的使用方法并分享相关见解。首先,我们将对当前主流的 GPT 类与 BERT 类大语言模型进行介绍和简要概述;其次,分析预训练数据、训练(微调)数据及测试数据对 LLMs 的影响;
(论文:BitFit: Simple Parameter-efficient Fine-tuning or Transformer-based Masked Language-models)是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。对于Transformer模型而言,冻结大部分 transformer-encoder 参数,只更新bias参数跟特定任务的分类层参数。
作者使用最近提出的ELI5数据集来测试模型生成长自由格式答案的能力。我们发现BART比以前最好的工作高出1.2 ROUGE-L,但数据集仍然具有挑战性,因为答案仅由问题弱指定。