




- @weixin_63326804
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
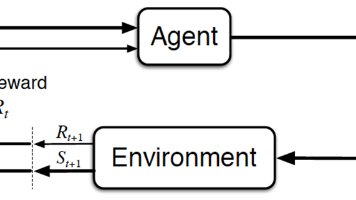
本文系统介绍了强化学习的核心概念与主流算法。首先阐述了强化学习的基本框架,包括智能体与环境交互、马尔可夫决策过程、蒙特卡洛采样等基础理论。随后详细解析了时序差分(TD)方法体系,包括Q-Learning、SARSA及其深度版本DQN等价值型算法。然后重点讨论了策略梯度(PG)方法及其改进版本Actor-Critic架构,涵盖A2C、A3C、DDPG、PPO、GRPO、DPO等算法。
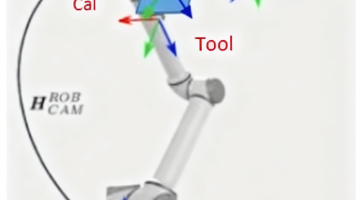
手眼标定是机器人视觉引导的核心技术,用于建立机器人坐标系与相机坐标系之间的转换关系。主要分为眼在手外(相机固定)和眼在手上(相机随机械臂移动)两种构型。标定前需完成相机内参标定以消除畸变。标定过程包括数据采集(记录机械臂位姿与标定板图像)、预处理、求解AX=XB方程及精度验证。最终得到4×4齐次变换矩阵,使机器人能准确执行视觉引导的操作任务。
本文系统介绍了强化学习的核心概念与主流算法。首先阐述了强化学习的基本框架,包括智能体与环境交互、马尔可夫决策过程、蒙特卡洛采样等基础理论。随后详细解析了时序差分(TD)方法体系,包括Q-Learning、SARSA及其深度版本DQN等价值型算法。然后重点讨论了策略梯度(PG)方法及其改进版本Actor-Critic架构,涵盖A2C、A3C、DDPG、PPO、GRPO、DPO等算法。
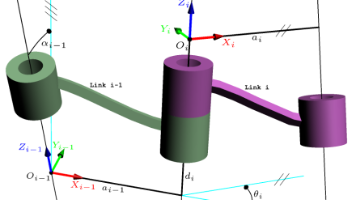
本文系统介绍了机器人运动控制三大核心技术:正运动学(FK)用于根据关节参数计算机器人末端位姿;逆运动学(IK)解决从末端位姿反求关节参数的问题,存在多解性和奇异性挑战;轨迹规划则包含关节空间和笛卡尔空间两种方法,分别适用于不同精度的运动需求。文章详细阐述了MDH参数法、解析法与数值迭代法等核心算法,并讨论了多项式插值、B样条等轨迹规划方法,最后指出实际应用中需综合机器人结构、任务需求选择合适算法。
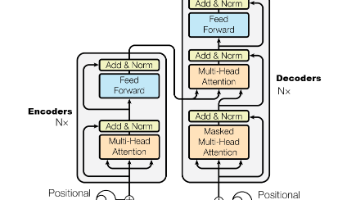
本文详细介绍了Transformer模型的结构和工作原理。Transformer由编码器和解码器两部分组成,编码器采用多层堆叠结构,每层包含自注意力机制和前馈神经网络;解码器在编码器基础上增加了掩码自注意力和交叉注意力机制。文章重点解析了自注意力计算过程、多头注意力机制、残差连接与层归一化等关键技术,并阐述了输入处理(词向量和位置编码)、损失函数等模块的设计原理。该模型通过并行计算和注意力机制,克
本文系统介绍了机器人运动控制三大核心技术:正运动学(FK)用于根据关节参数计算机器人末端位姿;逆运动学(IK)解决从末端位姿反求关节参数的问题,存在多解性和奇异性挑战;轨迹规划则包含关节空间和笛卡尔空间两种方法,分别适用于不同精度的运动需求。文章详细阐述了MDH参数法、解析法与数值迭代法等核心算法,并讨论了多项式插值、B样条等轨迹规划方法,最后指出实际应用中需综合机器人结构、任务需求选择合适算法。
本文综述了视觉-语言-动作(VLA)模型在机器人控制领域的最新研究进展,重点分析了32篇代表性论文的核心创新点与技术贡献。这些研究主要围绕以下方向展开:1)通过课程学习(AdaCuRL)、链式推理(CoT4AD)和扩散策略(DiffusionPolicy)等方法提升模型的推理能力;2)采用轻量化架构(SmolVLA)、边缘部署(LiteVLA)和令牌剪枝(VLA-Pruner)优化计算效率;3)结

本文系统介绍了强化学习的核心概念与主流算法。首先阐述了强化学习的基本框架,包括智能体与环境交互、马尔可夫决策过程、蒙特卡洛采样等基础理论。随后详细解析了时序差分(TD)方法体系,包括Q-Learning、SARSA及其深度版本DQN等价值型算法。然后重点讨论了策略梯度(PG)方法及其改进版本Actor-Critic架构,涵盖A2C、A3C、DDPG、PPO、GRPO、DPO等算法。
本文详细介绍了Transformer模型的结构和工作原理。Transformer由编码器和解码器两部分组成,编码器采用多层堆叠结构,每层包含自注意力机制和前馈神经网络;解码器在编码器基础上增加了掩码自注意力和交叉注意力机制。文章重点解析了自注意力计算过程、多头注意力机制、残差连接与层归一化等关键技术,并阐述了输入处理(词向量和位置编码)、损失函数等模块的设计原理。该模型通过并行计算和注意力机制,克
BERT是一种基于Transformer架构的预训练语言模型,通过完形填空和相邻句子判断任务进行无监督训练。其核心思想是先在大规模语料上进行预训练,再针对特定任务进行微调。BERT-base和BERT-large分别对应12层和24层Transformer编码器,输入时添加[CLS]标记用于句子表示。在多种NLP任务上取得突破性成果。该模型开创了预训练+微调的NLP处理范式,极大提升了自然语言处理
