




- @weixin_62627529
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
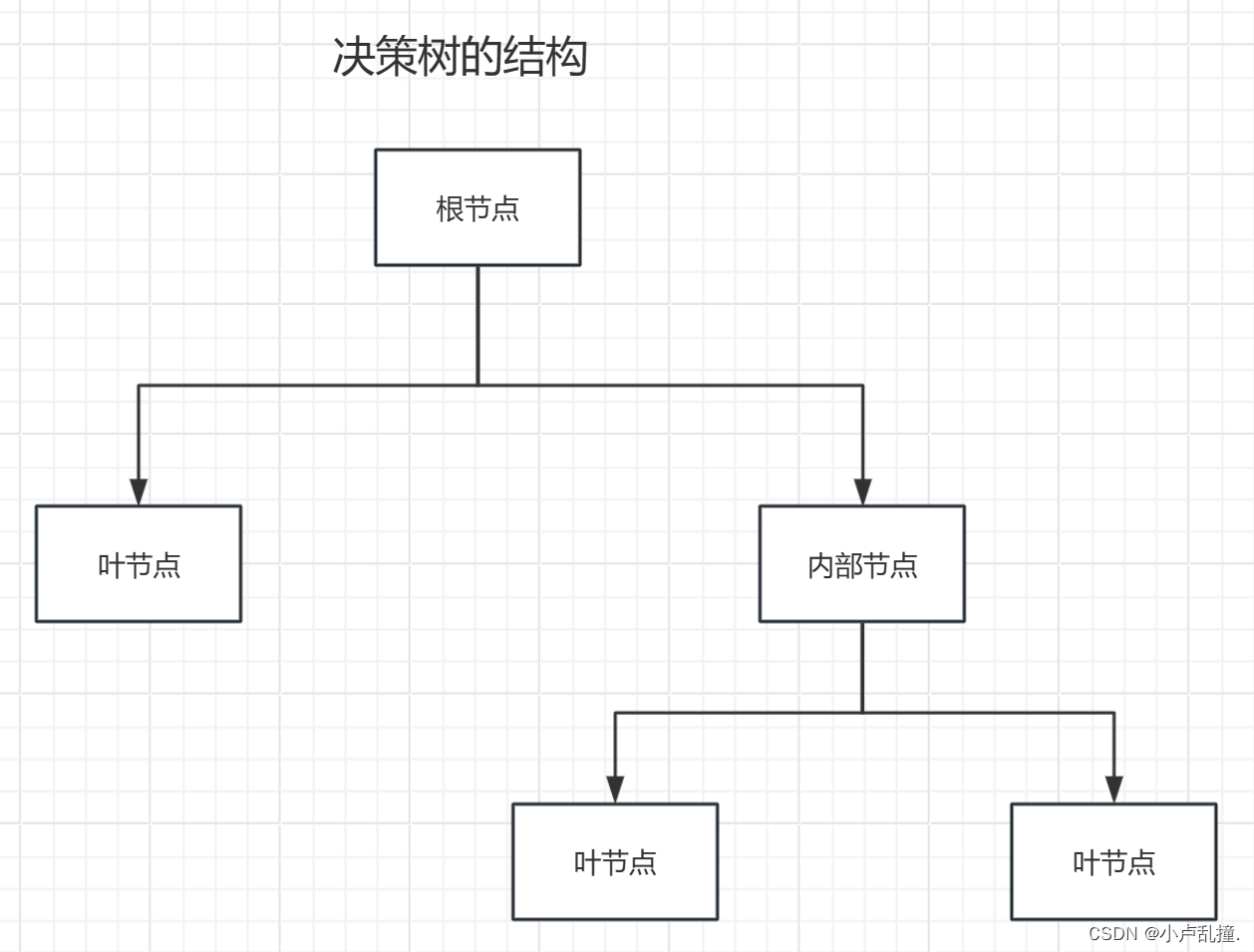
决策树是一种监督学习算法,广泛应用于分类和回归问题。它通过将数据集的特征空间划分为不同的区域来构建一个树状模型,每个区域对应于一个决策路径。决策树通过选择最佳的特征来进行决策,常见的特征选择方法有信息增益、基尼系数等。在实验过程中,常常会遇到过拟合问题,通过剪枝方法修剪决策树的叶子节点或合并相邻的叶子节点来减小模型复杂度。在实践中,对决策树进行适当的调参和剪枝操作非常重要,以获得更好的泛化能力和预
Logistics回归算法是一种简单但强大的分类算法,它在实际应用中被广泛使用。除了二元分类和多元分类之外,逻辑回归也可以用于解决其他问题,例如异常检测、推荐系统、文本分类、图像分类等。然而,对于复杂的非线性问题,逻辑回归算法的表现可能并不理想,需要考虑其他更加高级和复杂的算法来解决。
K最近邻(K-Nearest Neighbors,KNN)算法是一种常用的分类和回归算法。对于分类问题,KNN算法的基本思想是找出离待预测样本最近的K个训练样本,然后根据这K个样本的标签,通过投票或加权投票的方式来确定待预测样本的类别。iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包

回归和分类是机器学习中两种常见的任务类型,用于对数据进行预测和分类,并且都是监督学习。

K最近邻(K-Nearest Neighbors,KNN)算法是一种常用的分类和回归算法。对于分类问题,KNN算法的基本思想是找出离待预测样本最近的K个训练样本,然后根据这K个样本的标签,通过投票或加权投票的方式来确定待预测样本的类别。iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包