




- @weixin_62533513
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在 SDN 出现之前,网络设备(路由器、交换机)就像是老式的诺基亚手机:硬件和软件是锁死的。如果你想改变路由规则(比如:“把所有来自 YouTube 的流量走这条路,其他的走那条路”),你必须登录到每一台设备上,敲入复杂的命令。对于拥有成千上万台设备的谷歌、Facebook 这样的大公司来说,这简直是噩梦。物理与性能:我们通过地月通信和视频流计算,理解了带宽是路宽,延迟是车速,物理定律决定了网络的
这三个实验其实都在跑同一个SDN 闭环逻辑Packet-In:交换机遇到不认识的包,求助控制器。:控制器运行 Python 代码(学习 MAC、查黑名单、算路径)。:控制器把决定下发给交换机。:交换机根据流表,在底层直接执行任务。这套原理掌握了,你的实验报告理论部分就能写得非常专业了!需要我针对其中某个具体的 Python 函数(比如)帮你讲解它的代码实现逻辑吗?
网络核心是数据传输的高速公路。讲义对比了电路交换与分组交换,并提及了现代网络的演进。讲义末尾简要提及了SDN。这是网络架构的一次范式转移。在传统网络(如OSI模型时代)中,每个路由器既是大脑(决定路径的控制平面)也是肢体(转发数据的数据平面)。这导致网络僵化,难以升级。的核心思想是将“大脑”剥离出来,集中到一个中央控制器(Controller)中,而路由器蜕变为单纯的转发设备。这是控制器与转发器之
核心特性与技术参数NB-IoT (窄带物联网)Sigfox底层技术背景与知识产权Semtech 专有物理层芯片技术,LoRaWAN 为由联盟维护的开放式网络层协议由 3GPP 标准化主导的开放式蜂窝移动通信技术规范 (LTE Rel.13 及以上)完全专有的端到端技术生态 (由法国 Sigfox 公司独家主导)使用频段与频谱资源免费的非授权 ISM 频段 (如美国 915 MHz, 欧洲 868
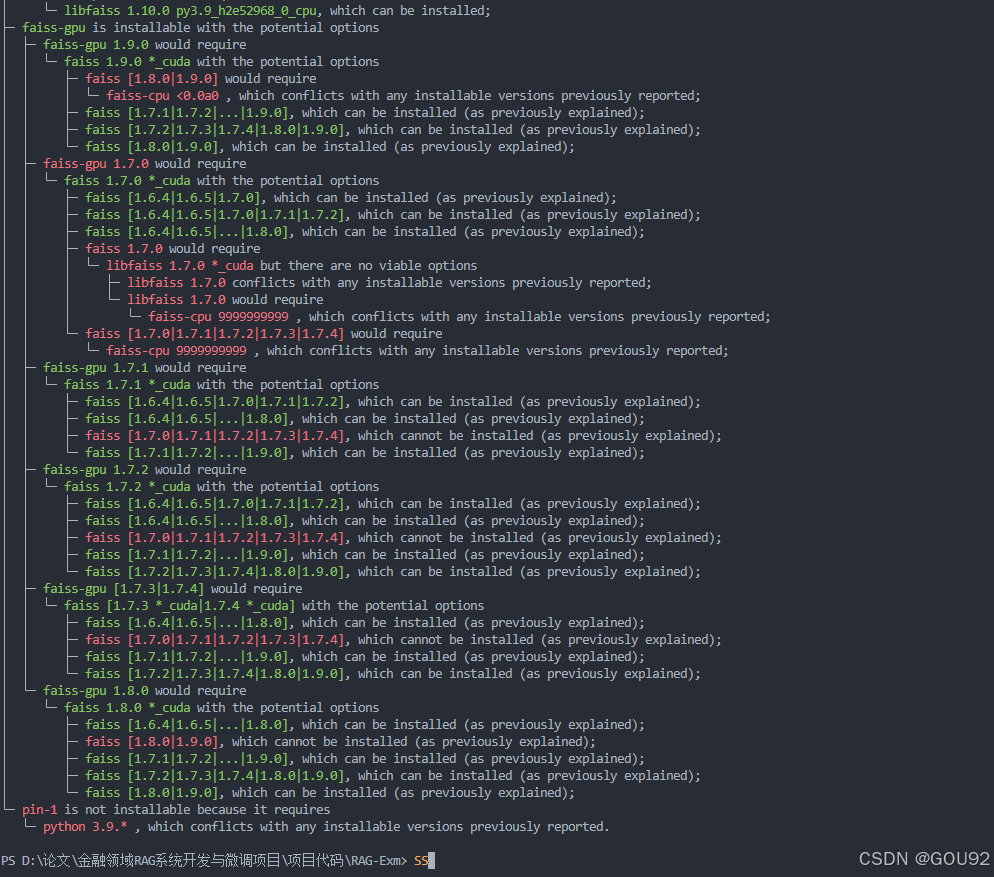
这张图片显示了在尝试安装或时遇到的依赖冲突问题。以下是图片内容的解释: 的安装问题: 的依赖问题:其他版本的问题:总结:清理现有安装:根据需求重新安装:如果你只有 CPU:检查 CUDA 兼容性:验证安装:其他注意事项如果在安装过程中仍然遇到问题,可以尝试清理 Conda 的缓存:确保你的 Conda 环境是最新的:希望这些步骤能帮助你解决的安装问题!
是库中模块提供的一个函数,用于计算两个向量之间的余弦相似度。余弦相似度是通过测量两个向量在多维空间中的夹角来评估它们的相似性,值范围在 [-1, 1] 之间,其中 1 表示完全相同,-1 表示完全相反,0 表示不相关。以下是。

在当今高度数字化的世界中,嵌入式实时系统(Embedded Real-Time Systems, RTS)构成了现代基础设施的隐形骨架。从控制汽车高速行驶时的防抱死制动系统(ABS),到维持重症监护室病人生病体征的医疗仪器,再到决定火星探测器能否安全着陆的导航计算机,这些系统不仅处理数据,更直接操控物理世界。与通用计算机系统不同,嵌入式实时系统的失效(Failure)往往不只是意味着数据的丢失或画
为了在工程上量化这一概念,我们引入**响应时间(Response Time)**的定义。对于任何一个嵌入式系统,它都有一组输入i1i2ini1i2...in和一组输出o1o2omo1o2...om。响应时间是指从输入信号呈现给系统的那一刻起,到系统产生相应输出的时间间隔。一个系统被称为实时系统,当且仅当它的响应时间被严格限制在某个**有界范围(Bounded)**内。
在实时系统的语境下,进程(Process)或任务(Task)被定义为一系列指令的序列,在没有其他活动干扰的情况下,由处理器连续执行直至完成。这一简单定义的背后,隐藏着实时系统对时间参数的极度敏感。为了量化这些行为,研究者确立了一系列关键的时间标记:到达时间(Arrival time,也称请求时间rir_iri)、开始时间(Start timeSiS_iSi)以及完成时间(Finishing t
在实时系统的语境下,进程(Process)或任务(Task)被定义为一系列指令的序列,在没有其他活动干扰的情况下,由处理器连续执行直至完成。这一简单定义的背后,隐藏着实时系统对时间参数的极度敏感。为了量化这些行为,研究者确立了一系列关键的时间标记:到达时间(Arrival time,也称请求时间 $r_i$)、开始时间(Start time $S_i$)以及完成时间(Finishing time