
写文章




- @weixin_58431882
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
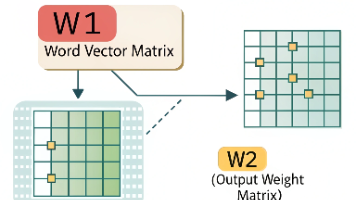
大白话解析 W1(词向量矩阵)和 W2(输出权重矩阵)
P.S.在之前的文章和中,我们已经频繁的接触到W1和W2,在神经网络的训练代码里,W1 和 W2 这两个矩阵就像模型的 “左膀右臂”—— 少了谁都不行。很多人觉得它们只是一堆数字,其实里面藏着模型对语言的 “理解”。今天咱们就用最接地气的方式,把这两个矩阵讲明白:它们到底是啥、各自干啥用、怎么配合工作,以及训练时是怎么一点点变好的。
大白话解析注意力机制
比如把中文 “他喜欢吃苹果” 翻译成英文,AI 会通过注意力机制知道 “他” 对应 “he”,“喜欢” 对应 “likes”,“苹果” 对应 “apples”,不会翻译错。而有了注意力机制,AI 在翻译 “它” 的时候,会自动 “回头看” 前面的 “小狗”,给 “小狗” 分配高权重,明确 “它” 的指代;没有注意力机制的 AI,可能会把这句话拆成一个个短词,逐个翻译,但很难处理词与词之间的远距离关

大白话解析RAG技术:给AI装上“记忆外挂“
RAG(检索增强生成)技术通过"检索+生成"的方式,解决了传统AI"胡编乱造"和"知识局限"两大痛点。其工作流程分为三步:首先将资料转化为向量存储,然后基于问题检索最相关资料,最后生成准确回答。这一技术通过让AI"带小抄"的方式,显著提升了回答的准确性和时效性,已广泛应用于企业知识库、智能客服等场景。但使用时需注意资料质量、更新频率和检索效率等问题。RAG与向量化技术相辅相成,为AI应用开辟了新路

到底了