




- @weixin_56760882
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
由于不同的代码需要的环境不同,在conda环境下使用旧版本的python 会经常导致cuda或torch的版本不对齐,跑不通,这里进行总结。特别是换显卡的时候1.看自己显卡的架构 从而知道至少多少版本的cuda才可以用(-- 4)2.用nvidia-smi 看目前可以支持最高多少版本的cuda,如果达不到想要的高版本cuda,再更新驱动(-- 3)3.由第一步得到的cuda版本找到最低的torch

参考:《动手学强化学习》作者:张伟楠,沈键,俞勇动手学强化学习 网页版动手学强化学习 github代码动手学强化学习 视频强化学习入门这一篇就够了!!!万字长文(讲的很好)强化学习入门(第二版)读书笔记我做了一个思维导图很方便理解之后学习完会在这里一直更新。补充一下要下载的库#第5章#第7章这里仅记录下学习时遇到的问题,已经学了一个月了,只是忙于毕设没空来更新一下学习进度,发现踏入门槛后学习强化学

从接触强化学习起,就一直知道强化学习可以打游戏,什么alphago,打星际争霸,后来知道大部分环境是专门写的用来供强化学习做实验的,是可以直接从环境中读取一些关键信息,并不是像人一样,只把当前在游戏中看到的图片当做当前的状态(当然,现在已经有研究这种的agi了)于是这里想使用强化学习来非侵入式打游戏。这里的非侵入式就是不读取游戏里的内存状态,而是像人一样打游戏。当然这样游戏也就不会判断你在作弊了。
将其中所有的trick都用上即为Rainbow_DQN。效果如下:(学习曲线)具体实现细节,代码中有较为详细的阐述。

探究论文TD-MPC的原理。此论文的创新点主要是这样:基于数据驱动的模型预测控制(MPC)相较于无模型方法有两个关键优势:通过模型学习提高样本效率的潜力,以及随着规划计算预算的增加表现更佳。有模型的环境下可以使用的算法(有RL算法也有不是RL的算法):如下表的MPC,POLO,LOOP,PLaNet,Dreamer,MuZero,EfficientZero,需要的计算资源高。
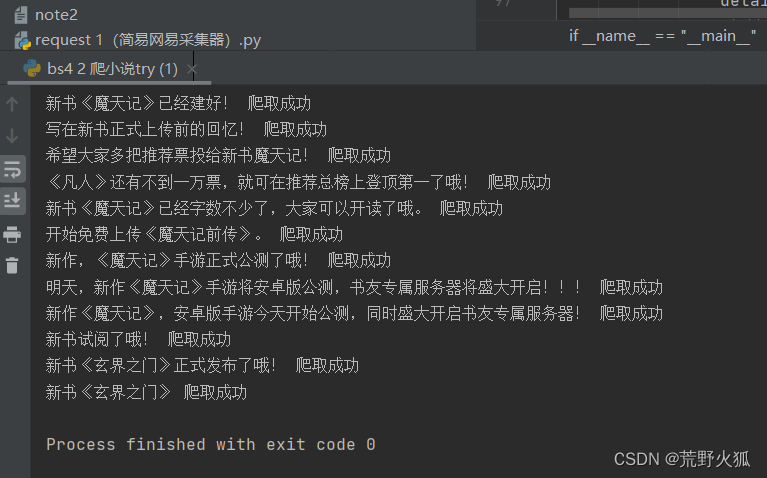
文章目录前言一、先上效果图二、使用步骤1.引入库2.读入数据总结前言之前因为想研究怎么让esp8266上校园网,折腾半天,请教大佬后,说要先学爬虫,就能知道怎么模拟登录上网了。大佬学的是c#,我学的是python,于是就开始学习了python爬虫,这是学习中觉得好玩的事,也遇到了不少困难。一、先上效果图这本书一共两千四百多章二、使用步骤1.引入库代码如下(示例):import numpy as n
参考图文解释Glados自动签到免费获取天数(github action版)之前用了一阵sever酱,然后前两天说cookie过期了,后来改了也没用,于是想自己写一份cookie不过期的。我尝试了半天,一直报一个json格式的错。(在电脑是可行的,在action上就报错)最后原博客回答:我看了下目前用github action的方式会触发cloudflare的五秒盾,阻止了脚本的签到行为。估计gi

写了好几个版本的PPO,很容易出现的问题。
临近期末,要交一次python大作业,乘这次机会,将之前做的项目的一个类似于红蓝对战的小游戏,再次整理一下,做成作业上交。这里并不对报告形式做约束,按照环境,原理,实验效果,做一次小的总结。环境由同门@及个人共同打造。但是我对游戏规则进行了一些修改。游戏本身只是简单的模拟双方对抗的场景,一些复杂的考虑并没有包含在内。为了符合报告的形式,这里尽量不以我为主语,以本研究为主语。

记录一下rocket5.2.0安装以及和python和c++通信的踩坑史。由于只是简单实现,c++部分的实现可能并不完美。linux:ubuntu20.04 2核2g 有公网iprocketmq:5.2.0 (发现一定要看官网的说明,大多博客都是安装的4.x版本的)c++ :g++4.9.3 调用的库rocket版本:rocketmq-client-cpp-2.2.0python:3.11.5 调
