




- @weixin_55035144
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
下图左边是一个非常简单的多层内存模型,只有寄存器/ cache/RAM。在这种简单模型结构下考虑优化GEBP,Cmc,n+=Amc,kcBkc,nCmc,n+=Amc,kcBkc,n,其中3个假设基于以上三点假设,上图中GEBP的RAM和cache之间的数据搬移开销为mckc+kcn+2mcnmemops而Cj:=ABj+Cj的计算量为2mckcnflops,那么计算量和数据搬移的比例。问题变成,
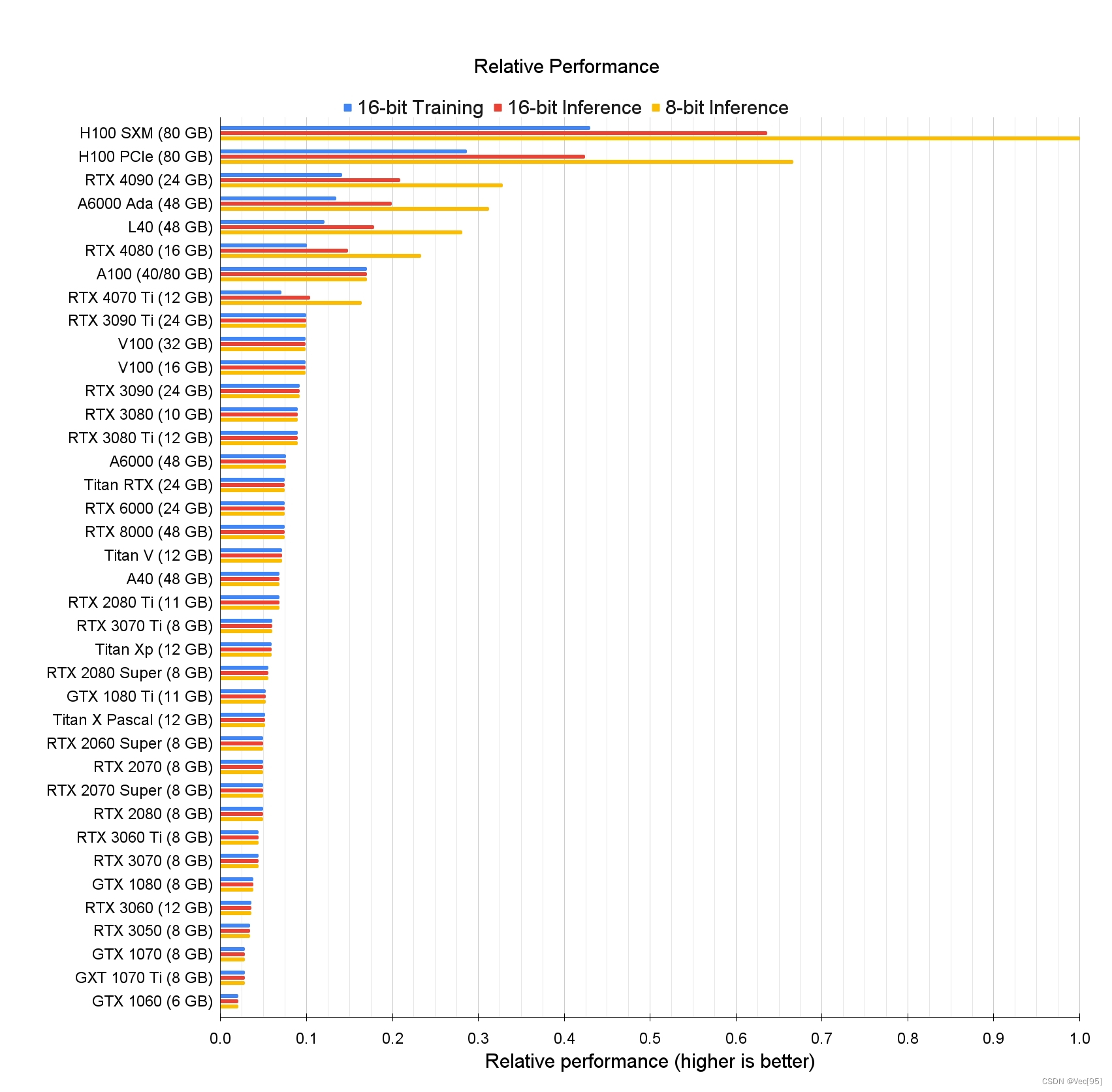
省流:个人拿来使用。跑大语言模型就4090,便宜点就3090或3090ti。不跑大语言模型就4070ti,因为有12g显存,再便宜点就2080ti,因为有11g显存,再便宜点就3060,因为有12g显存。
延迟着色(Deferred Shading)是一种渲染技术,通过将几何信息(如位置、法线和颜色)存储在缓冲区中,分两步完成光照计算,从而提升复杂场景的性能。2. 几何阶段 (Geometry Pass) 在几何阶段,渲染场景,将几何信息存储到 G 缓冲区。3. 光照阶段 (Lighting Pass) 使用屏幕空间四边形渲染光照。根据需要添加后期处理,直接在 FragColor 上进行额外处理即可

在onnx-parser中一旦模型parser解析完成,network就自动填好了,成为了serialized network。builder.create_optimization_profile():创建用于dynamic shape输入的配置器。创建network(计算图)是API独需的因为其他两种方法使用parser从onnx导入,不用一层层添加。模型搭建的入口,网络的trt内部表示和引擎
