- @weixin_53961451
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
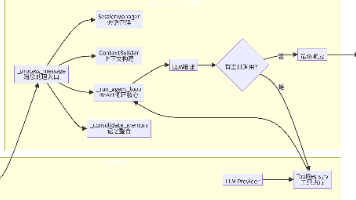
AgentLoop 作为消息处理中枢,具备以下关键功能:1)从消息总线接收消息;2)构建提示上下文;3)调用 LLM 推理并执行工具调用;4)管理会话状态和记忆。文章详细介绍了其初始化过程、默认工具注册、MCP 动态扩展机制、主循环设计以及核心消息处理流程。通过精巧的架构设计,AgentLoop 在几百行代码内实现了完整的 Agent 能力,支持会话管理、工具调用、记忆整合等核心功能,展现了高度可
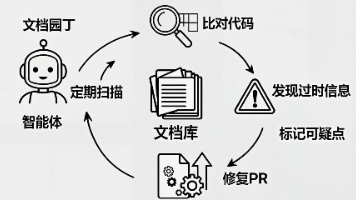
本文深入探讨Harness Engineering中维护长期质量的核心机制——反熵与垃圾回收。当智能体以远超人类的速度生成代码时,技术债务会被指数级放大,代码库面临不可逆的“熵增”风险。OpenAI的解决方案是:将人类的“品味”编码为自动化规则,建立定期运行的清理流程。文章详细解析了“品味不变量”的概念(结构化日志、命名规范、文件大小上限等),展示了如何将评审意见、重构PR转化为持续执行的机械规则
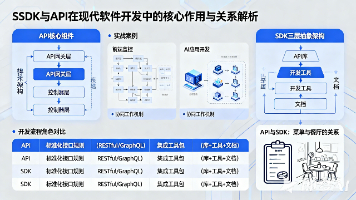
本文深入解析了SDK与API在现代软件开发中的核心作用与相互关系。API作为服务间通信的"契约",定义了标准化的接口规则(如RESTful、GraphQL等),而SDK则是包含API库、开发工具和文档的集成工具包。报告通过技术架构图详细展示了API网关层、控制器层等核心组件,以及SDK的三层抽象架构。通过实战案例(前端监控、AI应用开发等)说明了两者的协同工作机制,并对比了它们在开发流程中的不同角
当其他框架还在纠结“向量库好还是知识图谱好”时,Letta(原 MemGPT)走了一条完全不同的路:把操作系统的**虚拟内存分页机制**引入 LLM 上下文管理。本文深度拆解 Letta 的三大核心创新:将记忆分为“主上下文”与“外存”的分页调度模型、Git 版本化的记忆协同机制、以及 Agent“睡眠”时的后台学习(Sleeptime)。我们将结合 9.82GB 存储成本和 74% 准确率的真实
OpenClaw的self-improving技能通过结构化Markdown文件(SKILL.md)实现AI自我进化,其核心机制包括: 记忆捕获:从用户纠正中提取"模式→偏好"映射暂存待确认区 分层存储:HOT层(高频记忆)、WARM层(情景记忆)、COLD层(归档记忆)的三级存储体系 反思机制:任务完成后自动分析摩擦点并提炼经验教训 人工确认:关键记忆变更需用户批准,确保进化
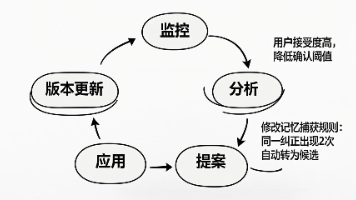
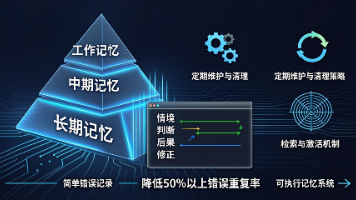
本文介绍了AI Agent记忆系统的工程实现方案,提出分层存储架构(工作/中期/长期记忆)和判例式数据结构。核心内容包括:1)基于JSON的判例记录格式;2)记忆写入、检索与激活机制;3)定期维护与清理策略。文章建议从简单错误记录开始,逐步构建可执行记忆系统,通过条件匹配和定期维护提升Agent决策质量,预计可降低50%以上错误重复率。最终目标是将理论转化为可落地的代码实现,使Agent行为更智能
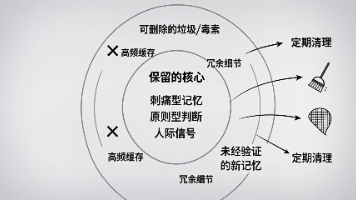
AI Agent社区掀起"记忆革命",揭示高效认知的本质不在于记忆量,而在于精准筛选。研究发现,不加维护的记忆系统会因"熵增"而失效,40%的内容从未被调用,15%甚至包含有害的错误记忆。解决方案包括:分层架构(短期/中期/长期记忆)、"判例式"知识记录、定期主动遗忘(优先删除最常用、最完整和最新记忆)。真正的智慧在于保留关键原则、失败教训和用户偏好,让记忆系统成为决策面板而非信息仓库。这场革命指
OpenClaw的self-improving技能通过结构化Markdown文件(SKILL.md)实现AI自我进化,其核心机制包括: 记忆捕获:从用户纠正中提取"模式→偏好"映射暂存待确认区 分层存储:HOT层(高频记忆)、WARM层(情景记忆)、COLD层(归档记忆)的三级存储体系 反思机制:任务完成后自动分析摩擦点并提炼经验教训 人工确认:关键记忆变更需用户批准,确保进化
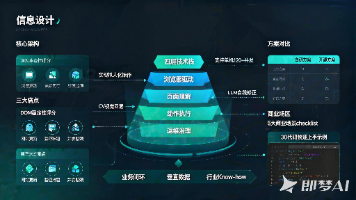
本文系统解析浏览器自动化系统(BUS)的核心架构与落地实践。BUS通过四层技术栈(浏览器驱动、页面理解、动作执行、运维治理)实现拟人化操作,并针对90%团队面临的网站更新、验证难题、并发瓶颈三大痛点提出解决方案。关键技术包括DOM稳定性评分、CV视觉回退和LLM自我修正,支持单机120+并发。文章对比自研与开源方案优劣,提供5大商业场景checklist及30行代码快速上手示例,强调BUS需结合垂
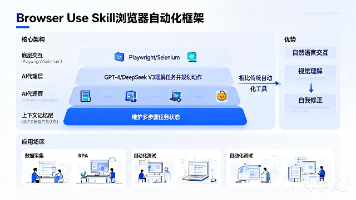
Browser Use Skill 是一种基于大模型的浏览器自动化框架,通过AI(如GPT-4、DeepSeek V3)控制浏览器,实现智能决策与自适应操作。其核心架构包括底层交互(如Playwright/Selenium)、AI代理层(理解任务并规划动作)和上下文记忆层(维护多步骤任务状态)。相比传统自动化工具,它具备自然语言交互、视觉理解、自我修正等优势,适用于数据采集、RPA、自动化测试等场