




- @weixin_52613525
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文记录了排查Qwen3-32B大模型在4张A100 GPU上周期性崩溃的过程。通过分析dmesg日志发现Xid 63和94错误码,定位到其中一张GPU存在显存硬件故障。文章解释了Row Remapper机制导致间歇性运行的原因,并给出短期方案(改用2卡运行)和长期方案(更换故障卡)。最后总结了硬件排障经验,强调dmesg日志的重要性,并附上常用诊断命令。该案例说明大模型长文本场景会放大硬件

Claude Code摘要: Claude Code是一款AI编程助手,采用"代理式编程"模式,支持代码审查、Git操作等功能。核心功能包括: 四种权限模式(Manual/Auto/Plan/Bypass),通过Shift+Tab切换 高效快捷键:Esc×2清空输入,Ctrl+G打开编辑器,@引用文件 斜杠命令体系:/init初始化项目,/btw并行提问,/rewind回退修改

本文分享了从非结构化文本中提取结构化数据的Prompt Engineering方法论。通过虚构的"产品缺陷报告分析"场景,详细展示了从通用提示词到精细化样例设计的完整迭代过程。关键改进包括:分品类定制提示词、文本切分与模块化样例设计,以及为每个样例添加自然语言描述。最终通过明确学习重点、减少歧义和增强元学习效应,使提取准确率和召回率提升至95%左右。该方法可广泛应用于医疗、金融

摘要:本文对比了使用requests库与openai SDK开发大模型应用的核心差异。requests需要手动拼接URL路径并构造完整请求体,灵活但代码量大;openai SDK自动补全路径,提供类型安全检查和智能提示,通过extra_body支持自定义参数。在多任务场景下,SDK能显著减少样板代码,内置流式处理等高级功能。建议95%场景优先选择openai SDK以提升开发效率,仅在特殊HTTP

本文探讨了如何优化LLM在电商客服对话中的信息抽取任务。作者发现单步抽取(要求模型一次性输出完整结构化数据)存在任务过载问题,导致字段遗漏、错误拆分等问题。解决方案是将任务拆分为两步:Step1进行粗粒度的事件检测,识别对话中的关键事件和粗略信息;Step2针对每个事件进行细粒度字段填充。这种多步方法显著提升了复杂场景下的召回率和准确性,同时使错误更易定位和修复。文章还提供了详细的提示词设计建议,

摘要: 本文探讨了在视觉大模型(VLM)结构化信息抽取中,如何在无法提供样例(few-shot)的情况下通过提示词工程确保数据真实性。核心策略包括:1)严格禁止默认选项,强制模型基于实际图像内容输出;2)建立“所见即所得”的绑定关系,防止模型脑补;3)通过JSON Schema精确约束输出格式。文章提出将抽象原则转化为可执行规则,如OCR未识别时输出空字符串、选项编号与物理位置严格对应等,使提示词

摘要: 提示词质量比模型选择更能决定大语言模型结构化信息抽取项目的成败。文章总结了从非结构化文本提取字段的三阶段提示词演进:1)基础规则版(定义模糊);2)边界强化版(硬性触发条件);3)示例增强版(判例驱动)。关键发现是few-shot示例的影响力超过抽象规则,需覆盖真实复杂场景并严格对齐规则。通过将提示词视为"可测试的规格文档",采用结构化模板、强约束表达和迭代闭环机制,可

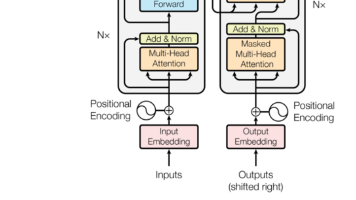
Transformer输入部分的三个关键细节:1)词嵌入乘以√d_model以平衡词向量和位置编码的幅度,防止位置编码淹没语义信息;2)使用register_buffer注册位置编码,使其随模型保存但不参与训练;3)相加时用[:,:x.size(1)]动态截取位置编码,适配不同长度的输入序列。这些机制共同确保输入信息(语义+位置)的有效融合和稳定训练。
《大模型时代的量化与微调技术:QLoRA的突破与实现》 文章摘要: 本文深入探讨大语言模型(LLM)在实际应用中的落地挑战与解决方案。随着模型参数规模膨胀至数十亿甚至数千亿,传统全参数微调方法面临严峻的硬件资源限制。为解决这一难题,研究社区提出了模型量化和参数高效微调(PEFT)两条路径。其中,QLoRA技术通过4-bit量化、分块处理、双重量化等创新方法,首次实现在24GB显存的消费级GPU上微

Transformer架构中位置编码(PE)采用"相加"而非其他方式融合词向量的原因可概括为:1)保持语义与位置信息的可分离性;2)不破坏词向量原有分布;3)天然兼容注意力计算;4)计算高效;5)经过实践验证。其本质是注入位置信息而不干扰语义表示,这一设计理念在RoPE等现代编码方案中得以延续。对于RAG开发者而言,理解PE原理有助于优化文档切分、检索和生成效果。
