- @weixin_52235666
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
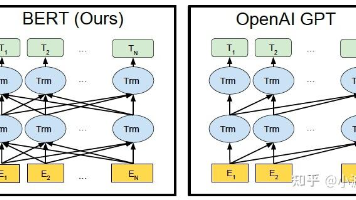
编码器预训练学习摘要 编码器预训练是Transformer的重要发展方向,通过大规模无标注文本训练通用文本理解模型,再迁移到下游任务。核心特点是使用Transformer Encoder生成上下文相关的动态词表示,解决传统静态词向量无法区分词语多义的问题。 发展历程从Word2Vec/GloVe的静态词向量,到ELMo基于RNN的上下文词向量,再到BERT的双向Transformer编码器。BER
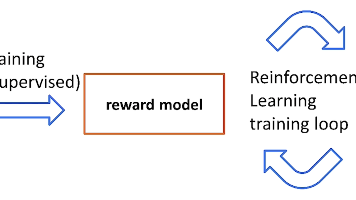
RLHF(Reinforcement Learning from Human Feedback)中文通常译为基于人类反馈的强化学习。它是一套用于大模型对齐(alignment)的训练流程,核心思想是:先让模型具备语言和指令跟随能力,再把人类对回答质量的偏好转化为奖励信号,最后用强化学习或偏好优化方法继续调整模型行为。重点:RLHF 不是单个算法RLHF 是一条训练管线,不等同于 PPO、奖励模型或
PPO(近端策略优化)在RLHF(基于人类反馈的强化学习)中用于微调语言模型,使其更符合人类偏好。其核心机制是:通过奖励模型对生成回答打分,利用优势函数(实际奖励与预期奖励之差)调整生成概率,同时通过clipping限制单步更新幅度,并引入KL惩罚防止模型偏离原始SFT模型太远。PPO结合策略损失、价值损失和KL惩罚,在提升回答质量的同时保持模型稳定性,使其成为RLHF中的关键优化方法。
摘要 视觉语言模型(VLM)是一种能够同时理解视觉和语言信息的多模态模型,旨在建立图像与文本之间的跨模态对齐关系。VLM的核心架构通常将视觉编码器与大语言模型结合,支持问答、推理等任务。本文从五个维度系统梳理VLM技术:1)概念与架构(如ViT、CLIP等模型);2)训练方法(对比学习、图文匹配等);3)典型模型(BLIP、LLaVA等);4)推理部署(vLLM框架、量化技术等);5)评测体系(V