




- @weixin_51908696
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
🧔 这里是九年义务漏网鲨鱼,研究生在读,主要研究方向是人脸伪造检测,长期致力于研究多模态大模型技术;国家奖学金获得者,国家级大创项目一项,发明专利一篇,多篇论文在投,蓝桥杯国家级奖项、妈妈杯一等奖。✍ 博客主要内容为大模型技术的学习以及相关面经,本人已得到B站、百度、唯品会等多段多模态大模型的实习offer,为了能够紧跟前沿知识,决定写一个“从零学习 RL”主题的专栏。这个专栏将记录我个人的主观
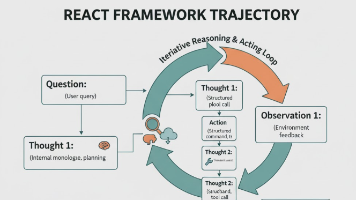
摘要:本文介绍了ReAct(Reasoning + Acting)范式,这是一种结合推理和行动的prompting技术,使大语言模型能够通过交替输出思考内容和行动指令来执行多步决策。与传统的链式思考(CoT)相比,ReAct增加了工具调用和环境反馈环节,形成“思考-行动-观察”的循环。文章详细解析了ReAct的基本元素(Thought、Action、Observation)及其交互流程,并通过伪代
摘要:本文介绍了大模型中的两种关键位置编码技术——三角函数绝对位置编码和旋转相对位置编码(RoPE)。三角函数编码通过固定正弦/余弦函数为每个位置生成向量,实现简单但难以外推超长序列。RoPE则直接在Q/K空间进行旋转操作,使注意力结果仅与相对位置差相关,更适应长上下文建模。目前主流采用RoPE,因其能更自然建模相对位置关系,且具备更好的外推性。文章还提供了两种编码的PyTorch实现代码,并解释

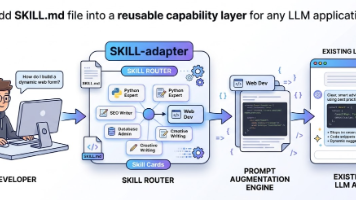
《基于腾讯元器的学术智能体搭建实践》摘要:本文介绍了如何利用腾讯元器平台零代码构建"学术炼金废弃回收站"智能体,面向科研人员提供情绪支持与学术建议。作者详细演示了从创建对话式智能体、编写提示词(包含黑话共情、建设性乐观等风格设定),到配置E-S-A响应模式(情绪接纳-策略重构-行动建议)的全过程。该智能体支持知识库对接实现RAG功能,可帮助研究者缓解焦虑、突破学术困境

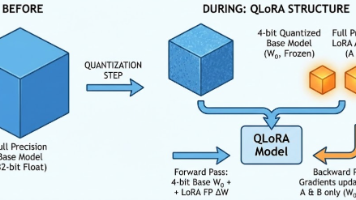
摘要 本文深入解析了QLoRA和DoRA两种高效微调技术的原理与应用。QLoRA通过4bit量化基座模型(采用NF4非均匀量化)配合全精度LoRA适配器,显著降低显存需求;DoRA则将权重分解为方向与幅度进行独立优化。文章详细对比了对称/非对称量化的区别,剖析了QLoRA的双重量化(Double Quantization)机制——先对权重分块量化,再对量化参数二次压缩。最后给出了HuggingFa
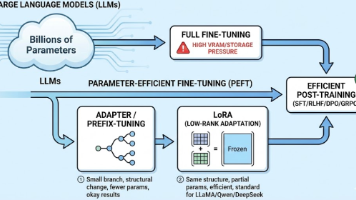
摘要 本文深入解析LoRA(Low-Rank Adaptation)技术原理及工程实现。LoRA通过冻结预训练模型参数,仅训练低秩增量矩阵ΔW=BA(B∈ℝ^{d×r}, A∈ℝ^{r×d}),显著降低微调参数量。核心观点包括: 低秩合理性:预训练模型已具备通用能力,下游任务只需低维调整; 超参数设置:rank(r)控制子空间维度,alpha实现方差归一化,建议r=4/8/16,alpha=r~2
《基于腾讯元器的学术智能体搭建实践》摘要:本文介绍了如何利用腾讯元器平台零代码构建"学术炼金废弃回收站"智能体,面向科研人员提供情绪支持与学术建议。作者详细演示了从创建对话式智能体、编写提示词(包含黑话共情、建设性乐观等风格设定),到配置E-S-A响应模式(情绪接纳-策略重构-行动建议)的全过程。该智能体支持知识库对接实现RAG功能,可帮助研究者缓解焦虑、突破学术困境
摘要 本文深入解析LoRA(Low-Rank Adaptation)技术原理及工程实现。LoRA通过冻结预训练模型参数,仅训练低秩增量矩阵ΔW=BA(B∈ℝ^{d×r}, A∈ℝ^{r×d}),显著降低微调参数量。核心观点包括: 低秩合理性:预训练模型已具备通用能力,下游任务只需低维调整; 超参数设置:rank(r)控制子空间维度,alpha实现方差归一化,建议r=4/8/16,alpha=r~2
摘要 本文深入解析LoRA(Low-Rank Adaptation)技术原理及工程实现。LoRA通过冻结预训练模型参数,仅训练低秩增量矩阵ΔW=BA(B∈ℝ^{d×r}, A∈ℝ^{r×d}),显著降低微调参数量。核心观点包括: 低秩合理性:预训练模型已具备通用能力,下游任务只需低维调整; 超参数设置:rank(r)控制子空间维度,alpha实现方差归一化,建议r=4/8/16,alpha=r~2
摘要:本文介绍了大模型中的两种关键位置编码技术——三角函数绝对位置编码和旋转相对位置编码(RoPE)。三角函数编码通过固定正弦/余弦函数为每个位置生成向量,实现简单但难以外推超长序列。RoPE则直接在Q/K空间进行旋转操作,使注意力结果仅与相对位置差相关,更适应长上下文建模。目前主流采用RoPE,因其能更自然建模相对位置关系,且具备更好的外推性。文章还提供了两种编码的PyTorch实现代码,并解释