- @weixin_51697828
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
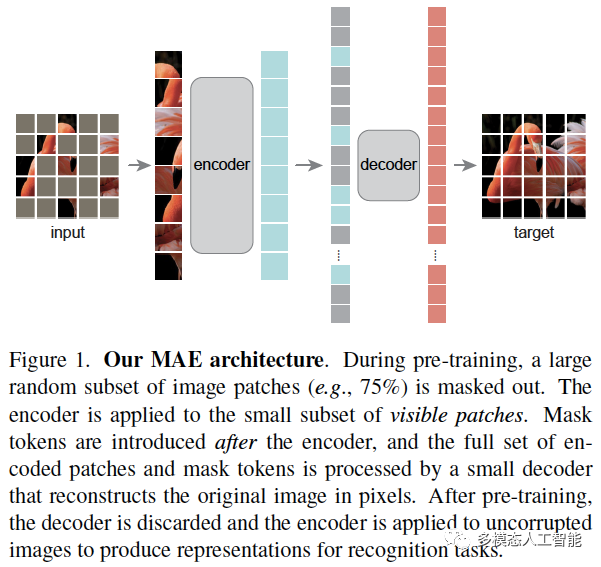
原文:He,Kaiming,XinleiChen,SainingXie,YanghaoLi,PiotrDoll'arandRossB.Girshick.“MaskedAutoencodersAreScalableVisionLearners.”ArXivabs/2111.06377(2021).1.Abstract本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习方法。我们的MAE
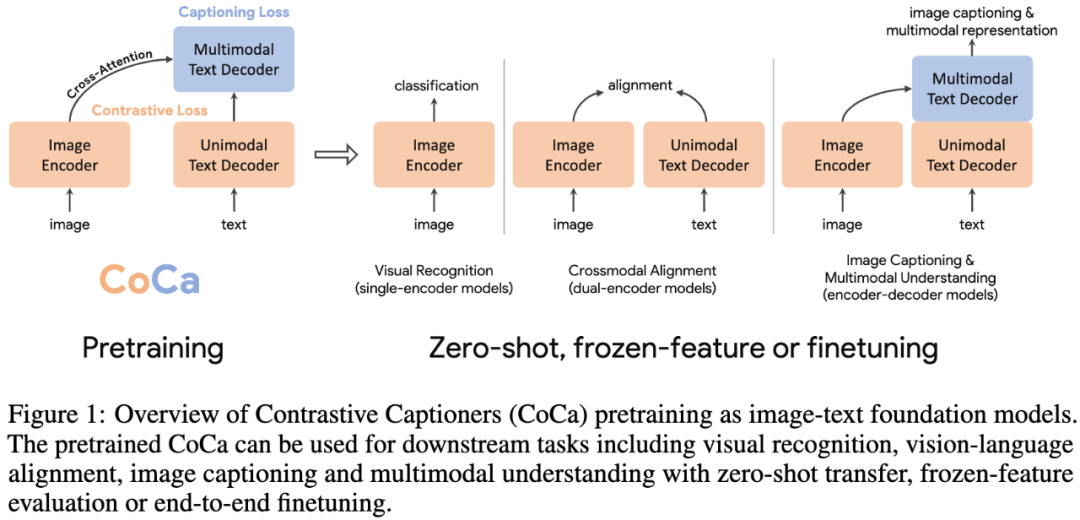
原文:YuJ,WangZ,VasudevanV,etal.CoCa:ContrastiveCaptionersareImage-TextFoundationModels[J].arXivpreprintarXiv:2205.01917,2022.探索大规模预训练基础模型在计算机视觉中具有重要意义,因为这些模型可以快速迁移到许多下游任务中。本文提出了对比Captioner模型(Contrastive
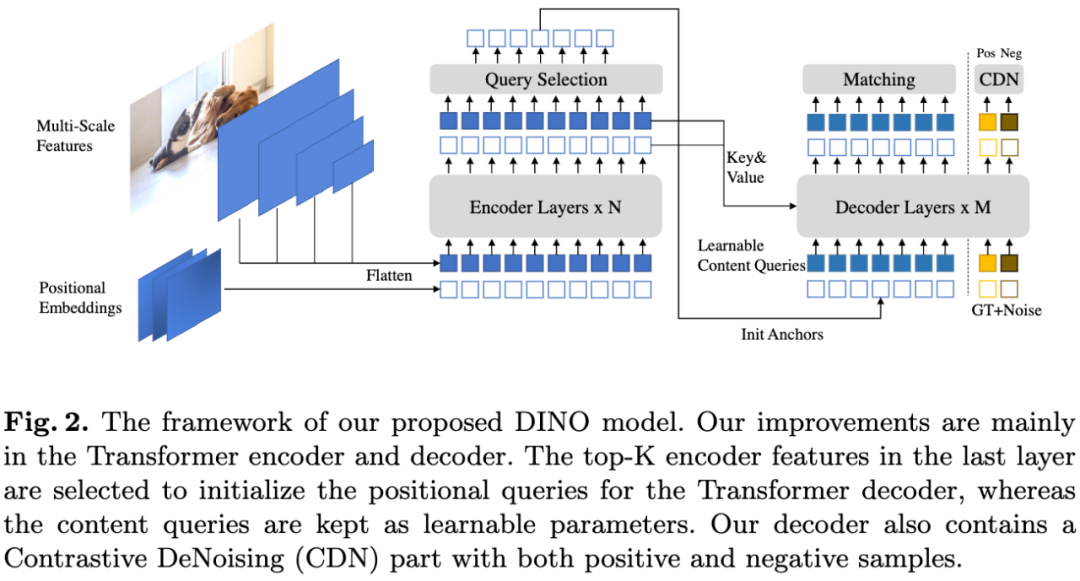
在本文中,我们提出了一种强大的端到端Transformer检测器DINO,借助contrastive denoising training、mixed query selection、look forward twice方法,大大提高了模型的训练效率和检测性能。我们进一步尝试在更大的数据集上用更强的骨干网络训练DINO,并在COCO 2017 test-dev数据集上达到了新的SOTA水平,63.
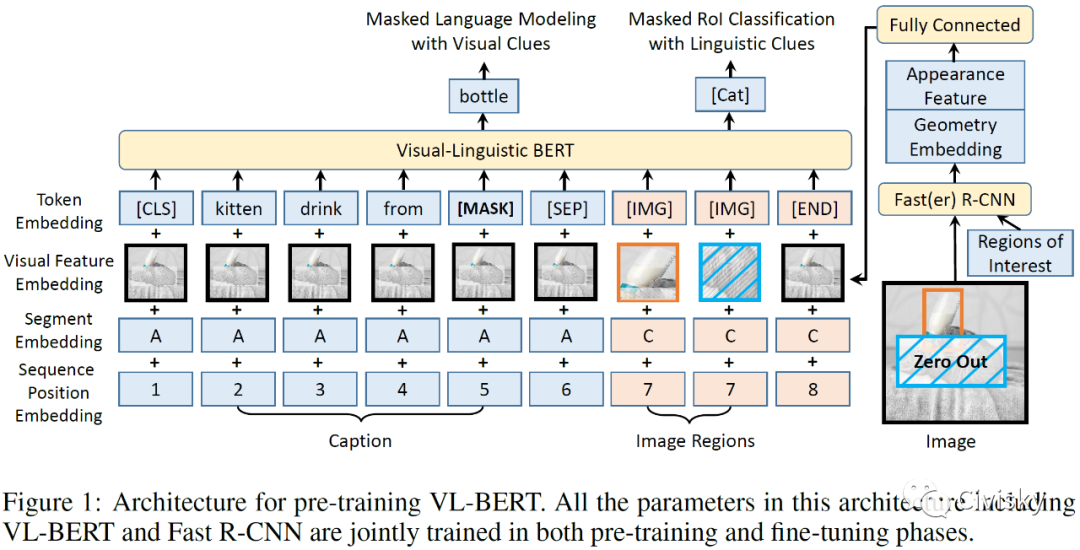
VL-BERT是一个可预训练的通用视觉语言表征模型,它采用简单而强大的Transformer作为主干,并进行了扩展,将视觉和语言的嵌入特征作为输入。VL-BERT的输入元素要么来自输入句子的单词,要么来自输入图像的Region-of-Interest(RoI,感兴趣区域)。作者利用大规模Conceptual Captions数据集和纯文本语料库对VL-BERT进行了预训练。大量实证分析表明,预训练
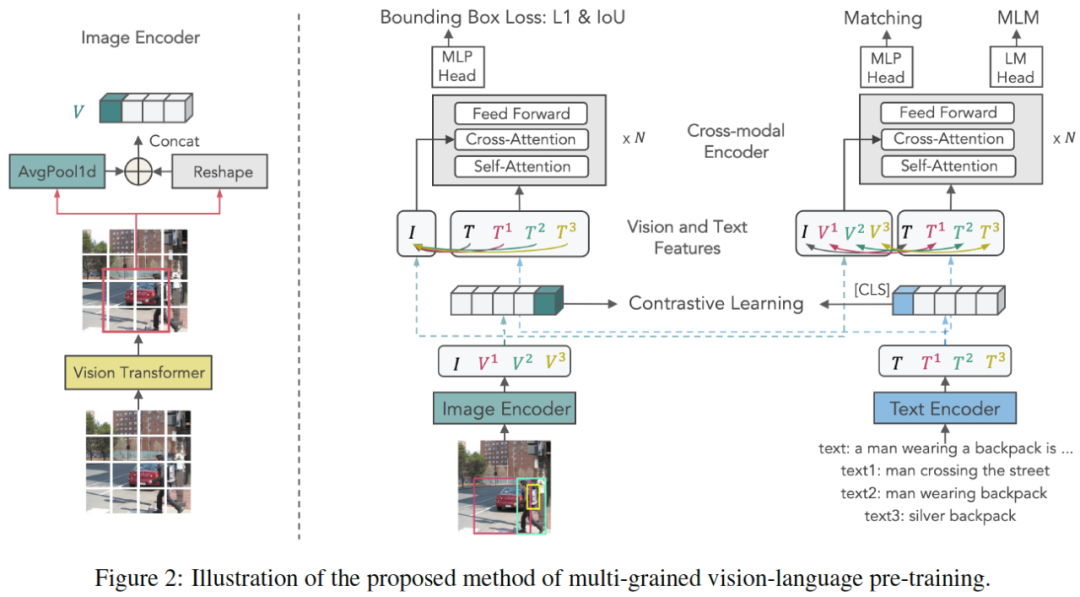
原文:Zeng,Yan,XinsongZhangandHangLi.“Multi-GrainedVisionLanguagePre-Training:AligningTextswithVisualConcepts.”ArXivabs/2111.08276(2021).源码:https://github.com/zengyan-97/x-vlm现有的视觉语言预训练方法大多依赖于通过目标检测提取的以对
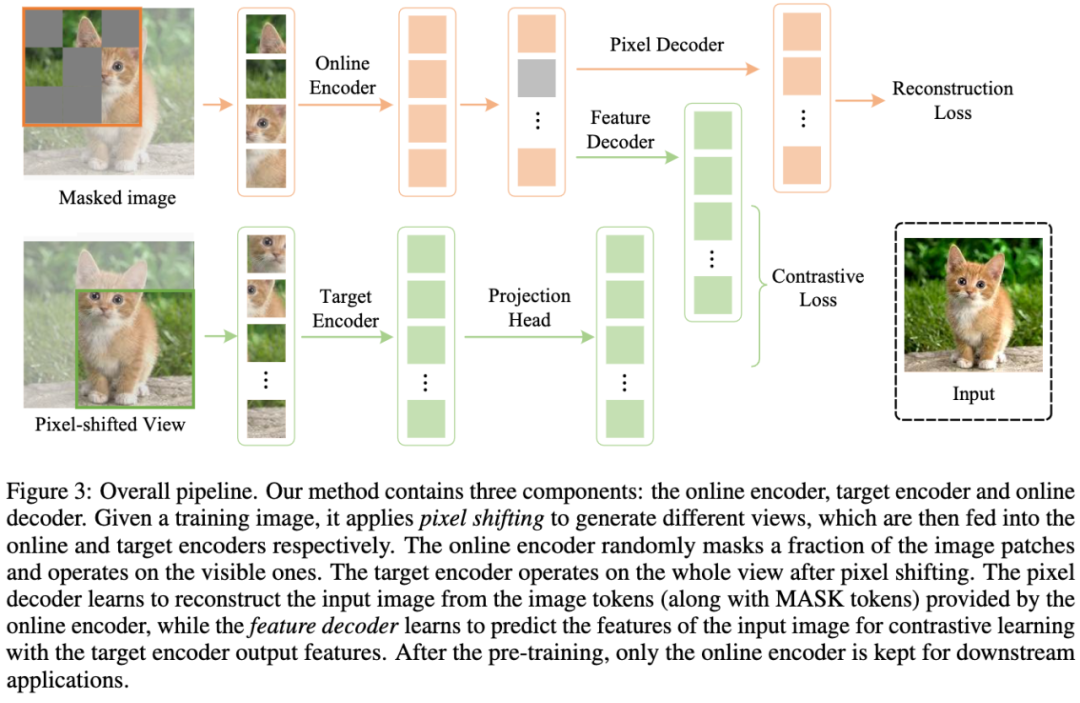
本文提出了一种新的自监督学习框架——对比掩码自编码器(CMAE),旨在利用对比学习来提高MIM的表示质量。在CMAE中,我们分别从输入生成和体系架构方面提出了两种新颖的设计,以协调MIM和对比学习。大量实验证明,CMAE可以显著提高预训练表示的质量。值得注意的是,在图像分类、语义分割、目标检测三个下游任务上,CMAE取得了最先进的性能。未来,我们将研究把CMAE扩展到更大的数据集上。
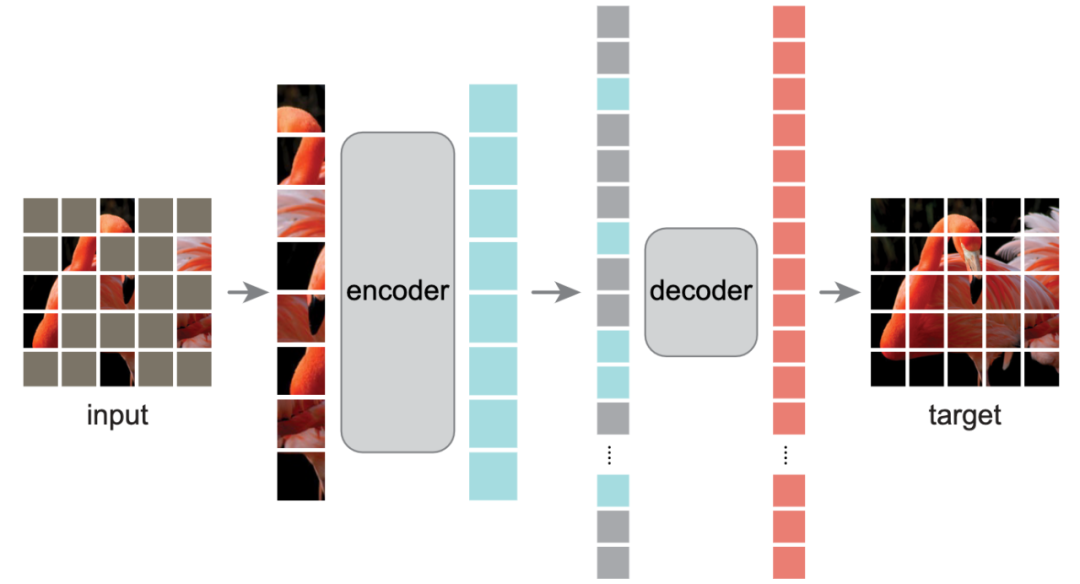
本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习方法。MAE方法很简单:我们对输入图像的patches进行随机掩码,然后重建缺失的像素。MAE基于两个核心设计。首先,我们开发了一个非对称的编码器-解码器架构,其中编码器仅对可见的patches子集(没有掩码的tokens)进行操作,同时还有一个轻量级的解码器,可以从潜在表示和掩码tokens重建原始图像。其次,我们发现对输入图像进
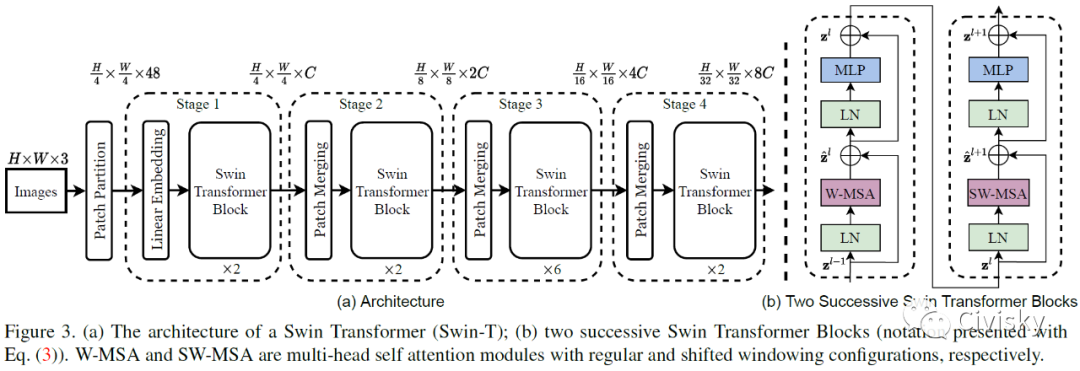
Transformer已被广泛应用于自然语言处理领域。但是由于语言和视觉之间存在巨大差异,如何将Transformer更好地应用到视觉领域成了一项挑战。为了解决这些差异,作者提出了基于移动窗口的分层视觉Transformer——Swin Transformer。移动窗口将Self-Attention计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而大幅提高了效率。分层结构在不同尺度建模上具有一
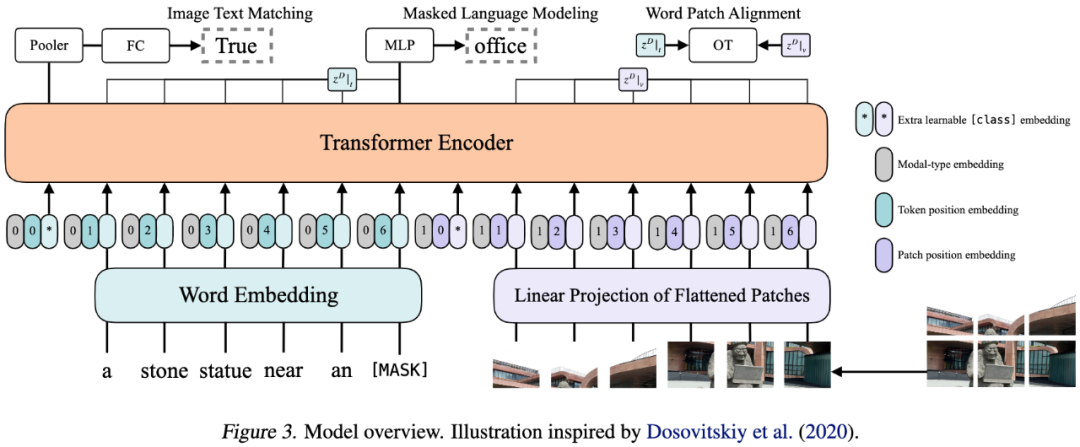
在本文中,我们提出了一种极简的VLP架构——视觉-语言Transformer(ViLT)。相比于那些大量配备卷积视觉嵌入网络(如Faster R-CNN和ResNets)的VLP模型,ViLT是有竞争优势的。未来,我们希望更多地关注Transformer模块内部的模态交互。尽管ViLT-B/32很了不起,但它更像是一个概念的证明,即没有卷积和region supervision的VLP模型仍然可以
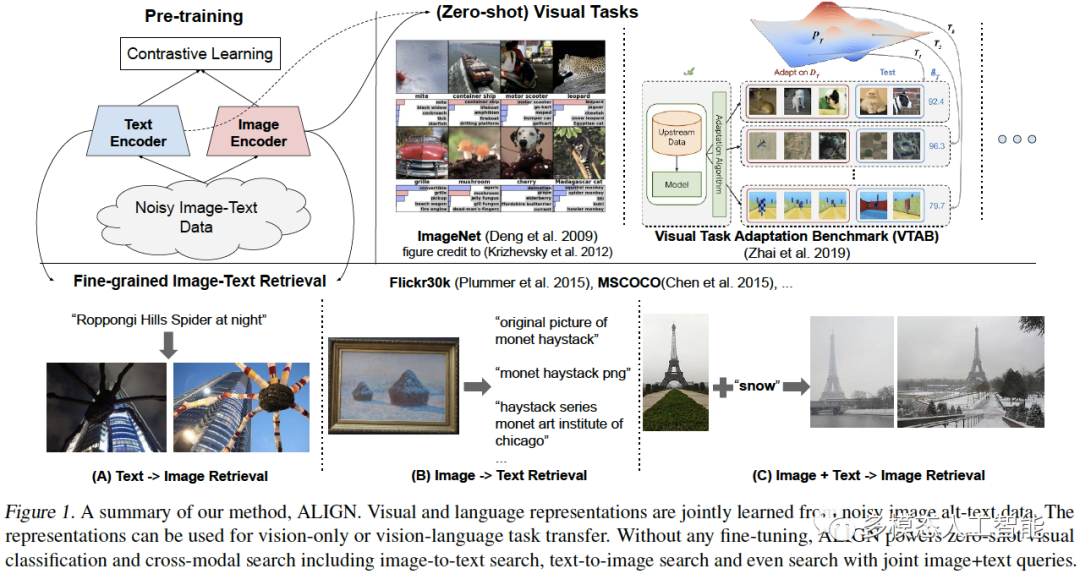
1.Title:ScalingUpVisualandVision-LanguageRepresentationLearningWithNoisyTextSupervision2.Author:JiaChaoetal.3.Abstract预训练的表示在许多NLP和感知任务上变得越来越重要。虽然NLP中的表示学习已经过渡到在没有人工注释的原始文本上进行训练,但视觉和视觉语言表示仍然严重依赖精心设计的训