
写文章




- @weixin_51552032
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
pip, github 突然连不上?报错和解决方法如下
更新google的域名服务器。然后新开一行或者在第一行加上。
[git-lfs] 遇到的相关问题
然后再git clone就没报错了,不过下载速度还是比较慢的,毕竟300MB的模型权重。的时候报了这个错误,我是从别的服务器copy这个权重文件夹过来的。的话,需要重启服务器,导致其它同学的进程被kill。

[vscode-ssh]ssh升级之后,vscode连不上
不要写成 ssh-keygen Guanjq@222.201.134.239。

[vscode-ssh] 经常出现连接远程服务器卡住的问题
【代码】[vscode-ssh] 经常出现连接远程服务器卡住的问题。
[vscode-ssh] 经常出现连接远程服务器卡住的问题
【代码】[vscode-ssh] 经常出现连接远程服务器卡住的问题。
关于ubuntu密码正确但是无法登录的情况
如果用户是L状态,那么就是lock了。

[医学影像分割] nnunet 处理自己的数据集 + 并行训练 +训练时遇到的问题
【代码】[医学影像分割] nnunet 如何创建自己的数据集?
论文阅读 2025-8-3 [FaceXformer, RadGPT , Uni-CoT]
最近ICCV 2025很多工作都release了,赶紧跟一波热度了解一下大家在做什么。
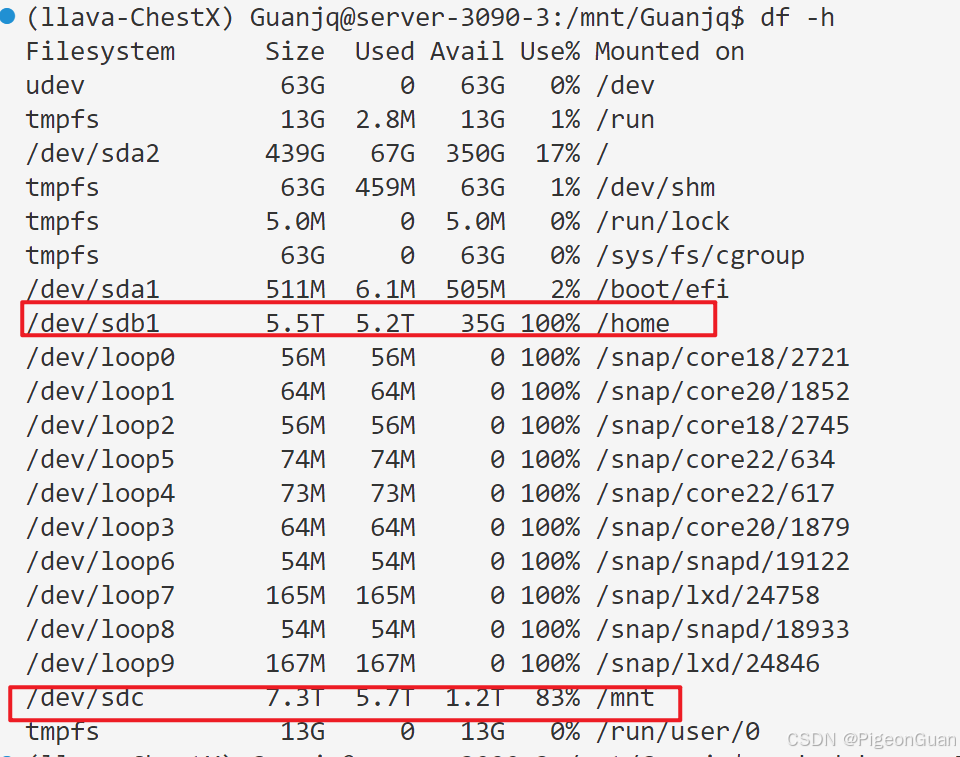
Ubuntu系统中测试硬盘速度
hdparm 测试中,7112 MB/s 的缓存读取速度表示从内存(RAM)直接读取数据的理论极限速度(依赖内存性能),而236 MB/s 的缓冲磁盘读取速度反映物理磁盘(如硬盘或SSD)的实际连续读取性能,两者差异源于内存(电子传输)和磁盘(物理/接口限制)的本质区别。一般来说大模型都是10GB以上的,但是我发现服务器上面的机械硬盘只有 700KB/s的加载速度,这十分慢。在运行程序的时候,我发
论文阅读 2025-9-13 论文阅读随心记
大模型自我反思被定义为两阶段的问同一个问题,但是思考多次。