- @weixin_51074012
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在微调qwen-vl的时候,微调完成之后,模型也保存好了,但是用保存的模型进行推理的时候报错,看样子是找不到分词器tokenizer。
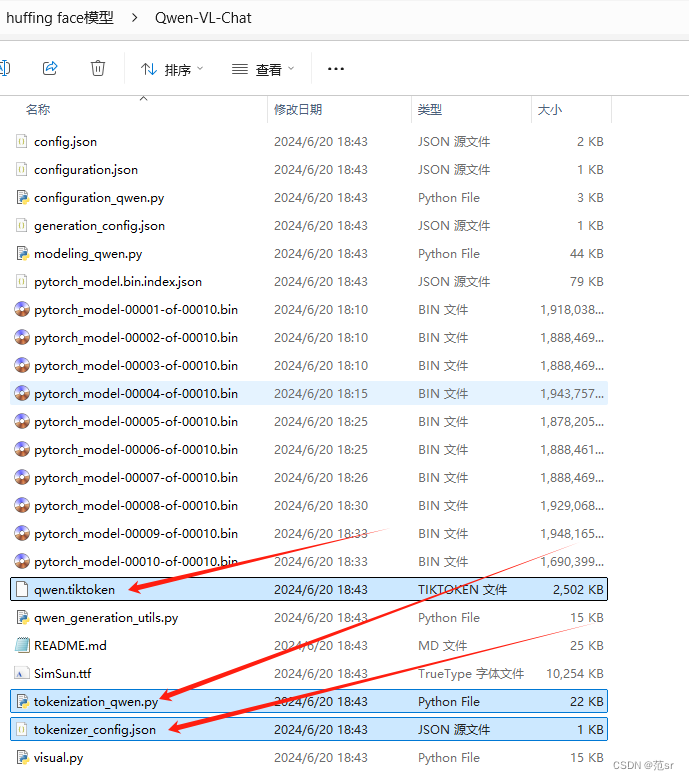
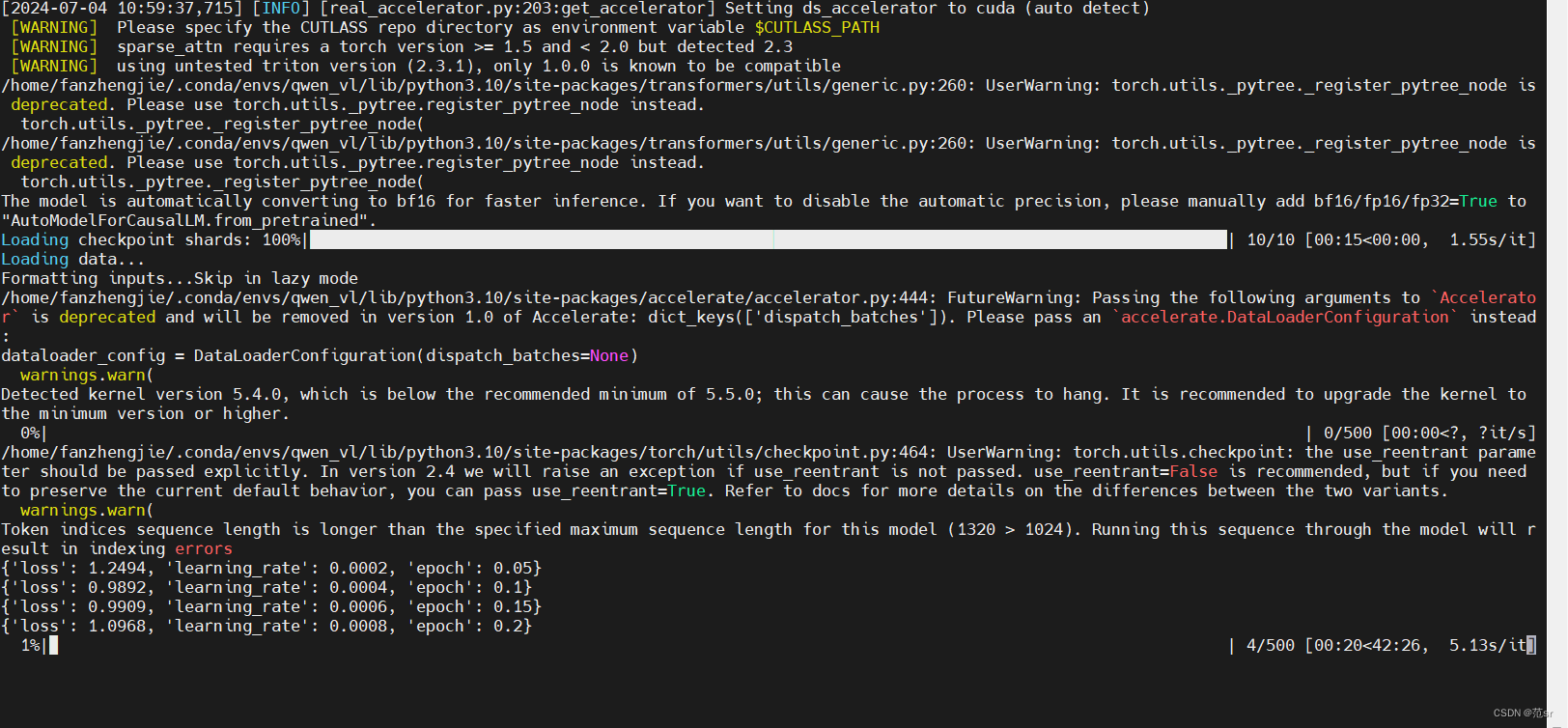
通过这个重定向,标准错误输出和标准输出都会被写入 train.log 文件。这个脚本文件名为 finetune_lora_single_gpu.sh,通常用于单 GPU 上进行 LoRA(Low-Rank Adaptation)的微调。模型训练完会保存在output_qwen文件中,想要修改去finetune.py 脚本中修改 --output_dir参数。重定向输出的目标文件名。这里是 trai
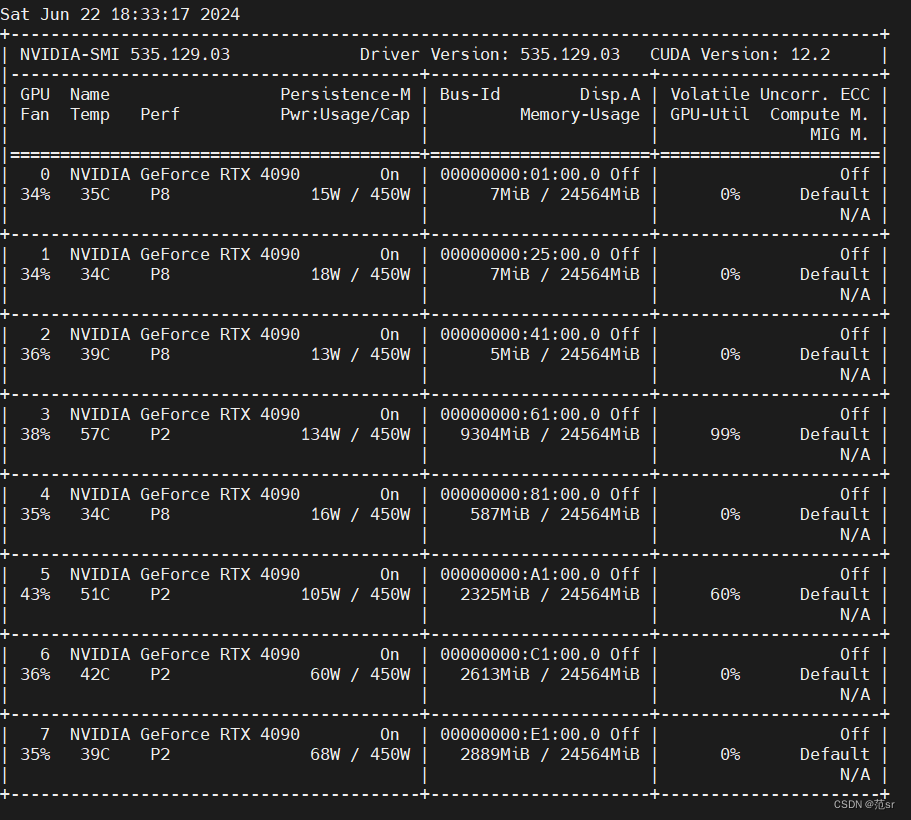
列出了多个NVIDIA GeForce RTX 4090显卡的信息,包括序号、名称、状态(如Persistence-M)、总线ID、显示适配器内存使用情况、易失性非一致性错误校正(Volatile Uncorr. ECC)状态、GPU利用率以及计算模式/迁移模式(Compute M./ MIG M.)。:显示为“Sat Jun 22 18:33:17 2024”,表明了截图的时间和日期。:显示为“
通过这个重定向,标准错误输出和标准输出都会被写入 train.log 文件。这个脚本文件名为 finetune_lora_single_gpu.sh,通常用于单 GPU 上进行 LoRA(Low-Rank Adaptation)的微调。模型训练完会保存在output_qwen文件中,想要修改去finetune.py 脚本中修改 --output_dir参数。重定向输出的目标文件名。这里是 trai
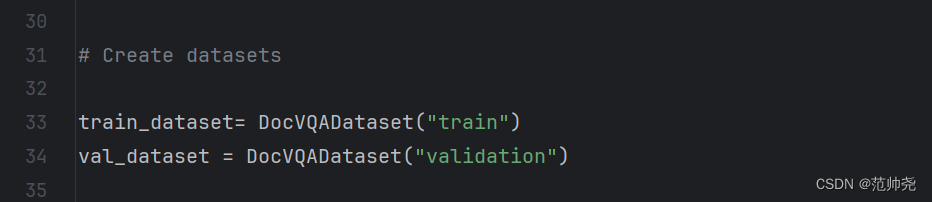
以上这种方法,是train数据和validation数据分开的时候的写法,也就是根据这两个字符串去映射各自的文件(记住必须是这两个字符串,不支持自定义,因为他在源码中写死了,train这个字符串只能索引train的数据集文件)。每个字符串后面是一个字典列表也就是你真正得数据集,必须是这三个字符串,他写死了,就是找这三个字符串来分割数据。如果你的数据集是分开的,也就是训练集和验证集是两个json文件