




- @weixin_50917576
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DeepSeekV3 整体预训练用了14.8万亿的高质量Token,并且在后期做了SFT和RL,模型参数量达到671B,但是每个Token仅激活37B参数。为了做到高效的推理和训练,DeepSeekV3自研了MLA注意力机制和无辅助损失负载均衡策略的MoE架构。从技术报告中看出,是经典的Transformer架构,比较亮眼的就是前馈网络使用的DeepSeekMoE架构、Attention机制使用M

国际电工委员会制定的国际标准IEC61158对现场总线(fieldbus)的定义是: 安装在制造或过程区域的现场装置与控制室内的自动控制装置之间的数字式、串行、多点通信的数据总线。

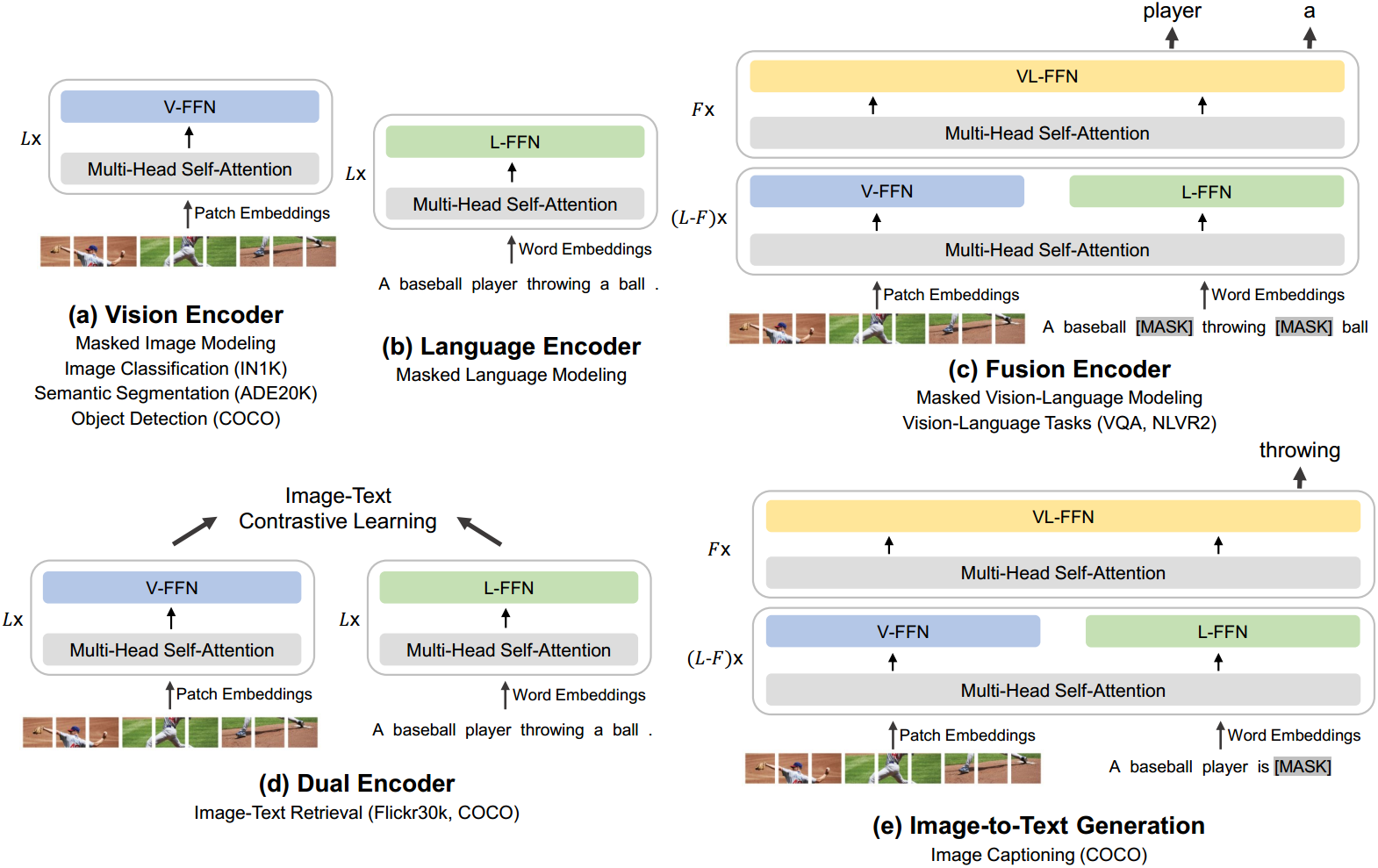
语言、视觉和多模态预训练的大融合正在出现。在这项工作中,我们介绍了一个通用的多模态基础模型BEIT-3,它在视觉和视觉语言任务上实现了最先进的迁移性能。具体来说,我们从主干架构、预训练任务和模型扩展三个方面推进了大收敛。我们介绍了用于通用建模的多路Transformers,其中模块化体系结构支持深度融合和特定于模态的编码。基于共享主干,我们以统一的方式对图像(英语)、文本(英语)和图像-文本对(“
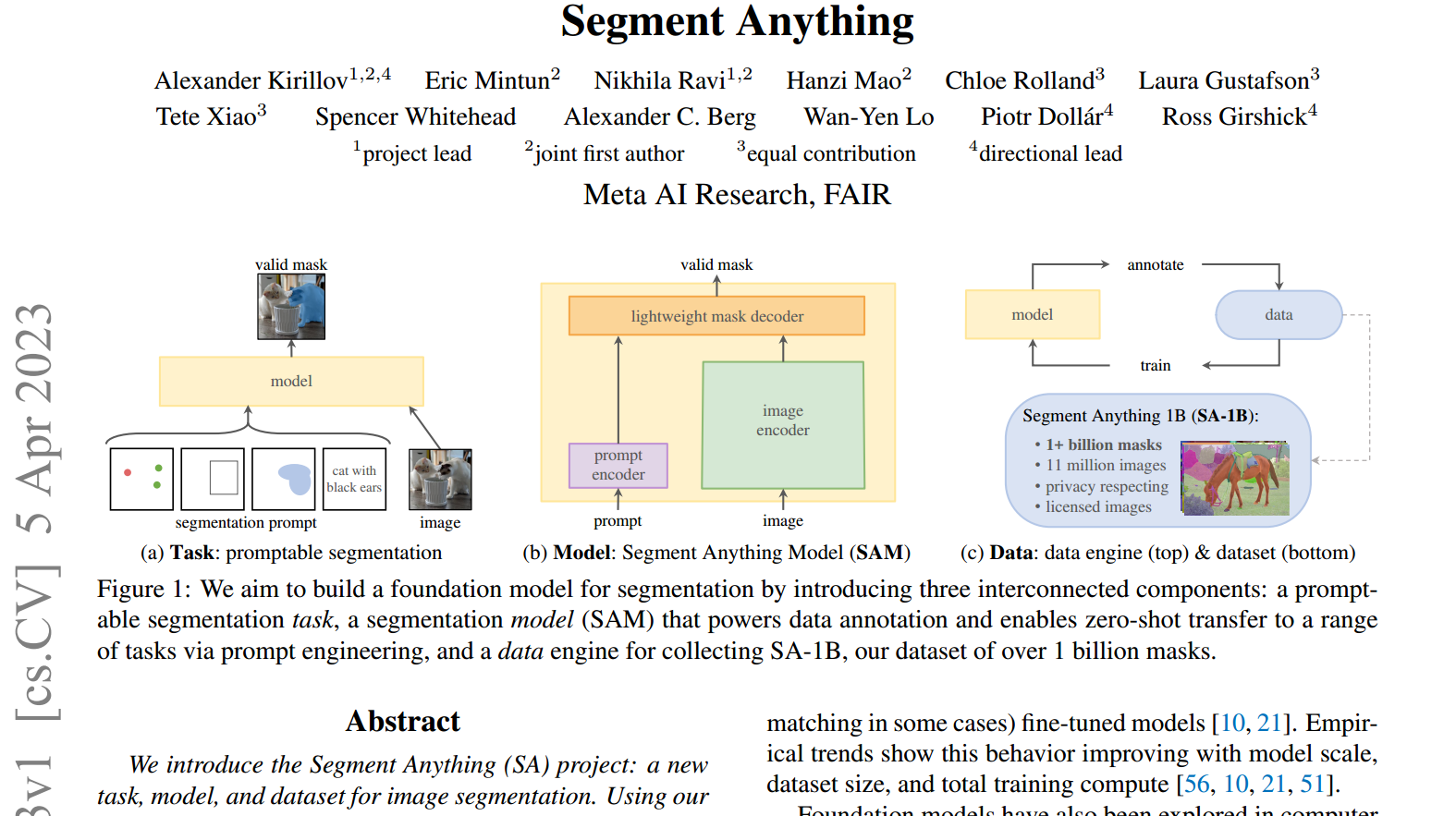
我们介绍了任何片段(SA)项目:一个新的任务,模型和数据集的图像分割。在数据收集循环中使用我们的高效模型,我们建立了迄今为止(到目前为止)最大的分割数据集,在1100万张许可和尊重隐私的图像上拥有超过10亿个掩模(本文的mask相当于标注,一个mask相当于一个标签,如标注了一个细胞,标注了一只猪,这就是分别的不同的标签,即mask)。该模型被设计和训练为提示,因此它可以将零拍摄转移到新的图像分布
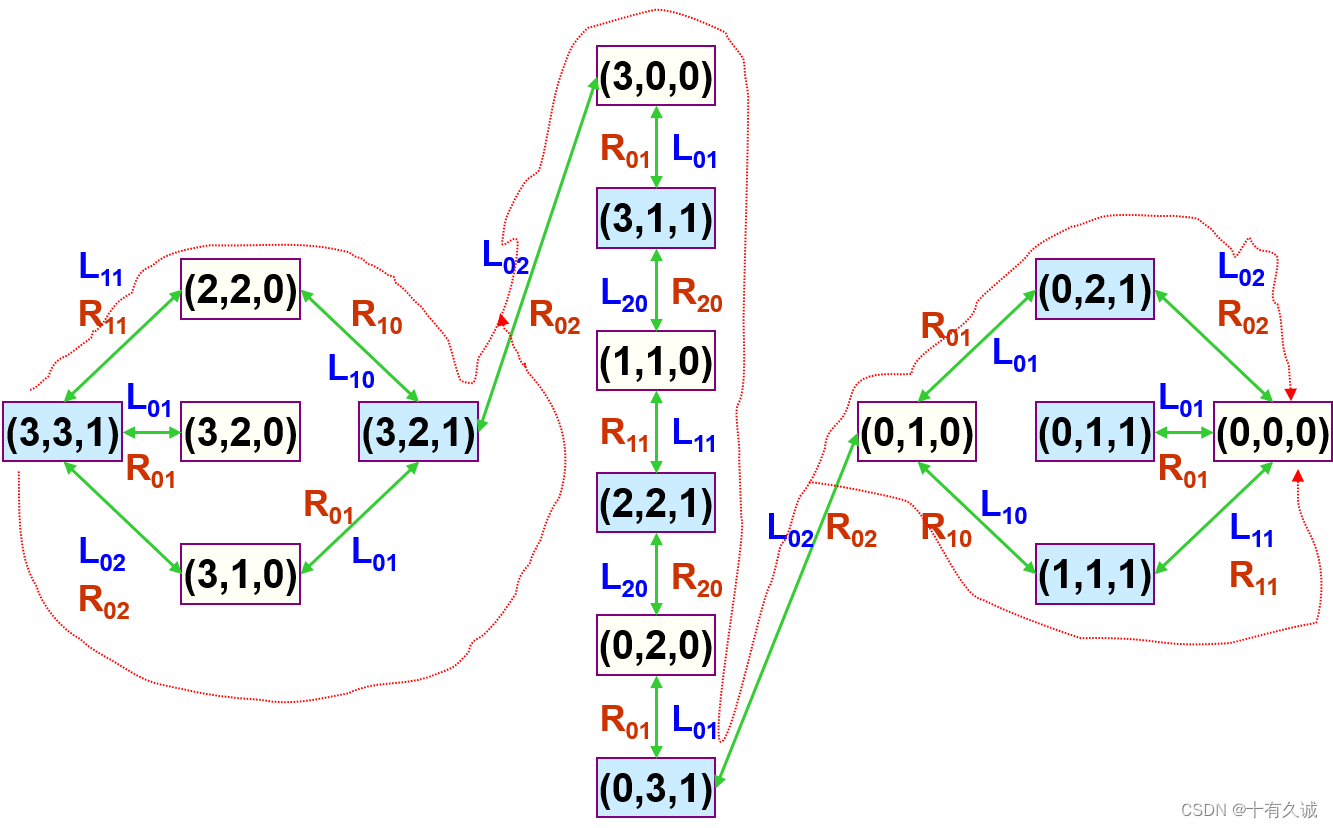
一般的传教士和野人问题(Missionaries and Cannibals):有N个传教士和C个野人来到河边准 备渡河。河岸有一条船,每次至多可供K人乘渡。 问传教士为了安全起见,应如何规划摆渡方案,使 得任何时刻,在河的两岸以及船上的野人数目总是 不超过传教士的数目,但允许在河的某一岸只有野 人而没有传教士。
DeepSeekV3 整体预训练用了14.8万亿的高质量Token,并且在后期做了SFT和RL,模型参数量达到671B,但是每个Token仅激活37B参数。为了做到高效的推理和训练,DeepSeekV3自研了MLA注意力机制和无辅助损失负载均衡策略的MoE架构。从技术报告中看出,是经典的Transformer架构,比较亮眼的就是前馈网络使用的DeepSeekMoE架构、Attention机制使用M
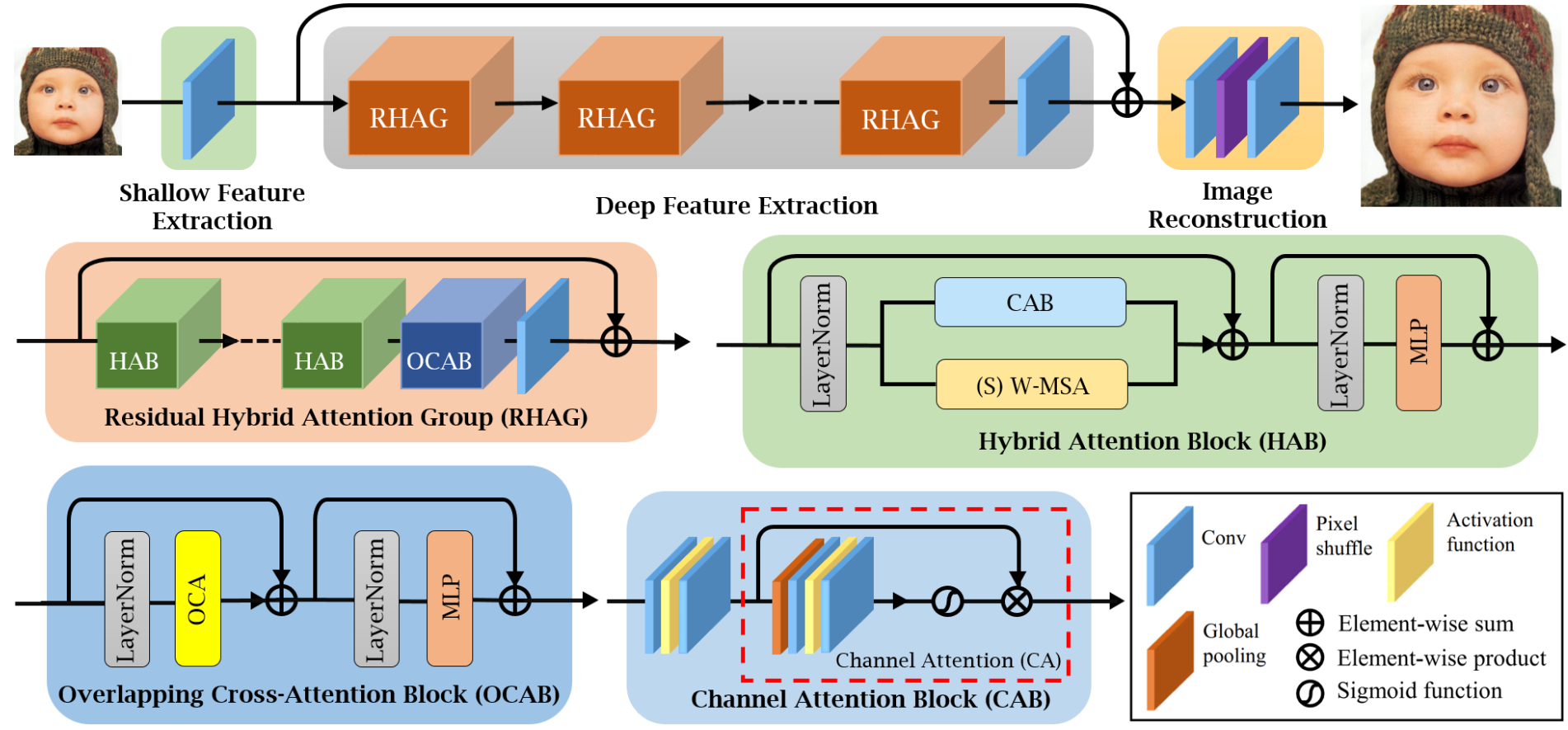
本文提出了一种称为混合注意力 Transformer(HAT) 的新型网络架构, 它融合了通道注意力和窗口自注意力机制的长处, 提高了模型处理全局和局部信息的能力。 此外, 研究人员还引入了一个跨窗口的注意力模块, 用以强化邻近窗口特征间的互动。 通过在训练阶段实行同任务预训练, 进一步提升了模型性能。 经过一系列实验, 这个方法在性能上显著优于现有最先进技术, 达到了 1dB 以上的提高。
DeepSeekV3 整体预训练用了14.8万亿的高质量Token,并且在后期做了SFT和RL,模型参数量达到671B,但是每个Token仅激活37B参数。为了做到高效的推理和训练,DeepSeekV3自研了MLA注意力机制和无辅助损失负载均衡策略的MoE架构。从技术报告中看出,是经典的Transformer架构,比较亮眼的就是前馈网络使用的DeepSeekMoE架构、Attention机制使用M