




- @weixin_48878618
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
其中,第一行查看2开头python版本,第二行查看3开头python版本。:删除已安装的软件包(不保留配置文件),删除软件包,同时删除相应依赖软件包。:删除已安装的软件包(保留配置文件),不会删除依赖软件包,保留配置文件。:删除为了满足某些依赖安装的,但现在不再需要的软件包;选择需要卸载的版本以python2.7为例。首先确定系统已安装的python版本。版本切换(多版本状态下)

意思是缺rendering文件,这个问题主要是由于Gym版本的变化,在某个版本中删除了classic_control包中的rendering文件,所以需要手动把这个文件给加上。

起因:在Pycharm中,基于python新建了环境,输入conda activate base后突然无法激活虚拟环境了解决1.找到Anaconda Prompt右击进入文件所在位置2. 右击进入属性3. 复制cmd.exe开始到最后的路径4. 粘贴到pycharm-settings-tools-terminal-shell path中5. 保存重启pycharm,问题解决。详细参考下面参考文献。
尽管人工智能被吹嘘的很美丽,但我们现在所使用的基于人工智能的机器人,是先在仿真环境中学习,再应用于真是世界,尽管它具有很强的能力,但在真实世界中它并没有重新学习的能力,现实世界中新出现的,在仿真环境中没有被训练的状况,它不能解决。但具身智能让机器人有了在真实世界中学习的能力。

起因:在Pycharm中,基于python新建了环境,输入conda activate base后突然无法激活虚拟环境了解决1.找到Anaconda Prompt右击进入文件所在位置2. 右击进入属性3. 复制cmd.exe开始到最后的路径4. 粘贴到pycharm-settings-tools-terminal-shell path中5. 保存重启pycharm,问题解决。详细参考下面参考文献。
灰度图像只包含亮度信息,不包含颜色信息,因此数据量比彩色图像小,处理起来更加简单和快速。这对于需要实时处理大量图像数据的场合尤为重要。:在许多图像处理任务中,如边缘检测、图像增强、特征提取等,颜色信息并不是关键因素。去除颜色信息可以减少计算的复杂度,提高算法的效率。:在某些情况下,颜色可能会分散观察者的注意力,而灰度图像可以更好地突出图像的结构和纹理,使得关键信息更加明显。:在图像分析和机器视觉领

在无监督学习中,没有外部反馈,学习是通过数据本身的特性来驱动的。而在强化学习中,反馈是在智能体执行动作后由环境提供的奖励,这些奖励可能是稀疏的(不是每个动作都有奖励)、延迟的(长期效果)且通常需要智能体自己探索来确定动作的优劣。在强化学习中,智能体会基于其观察到的环境状态进行决策,执行动作,并接收环境给予的奖励(或惩罚)。而强化学习是关于连续决策的,智能体需要在一系列的时间点上做出一系列的动作。无
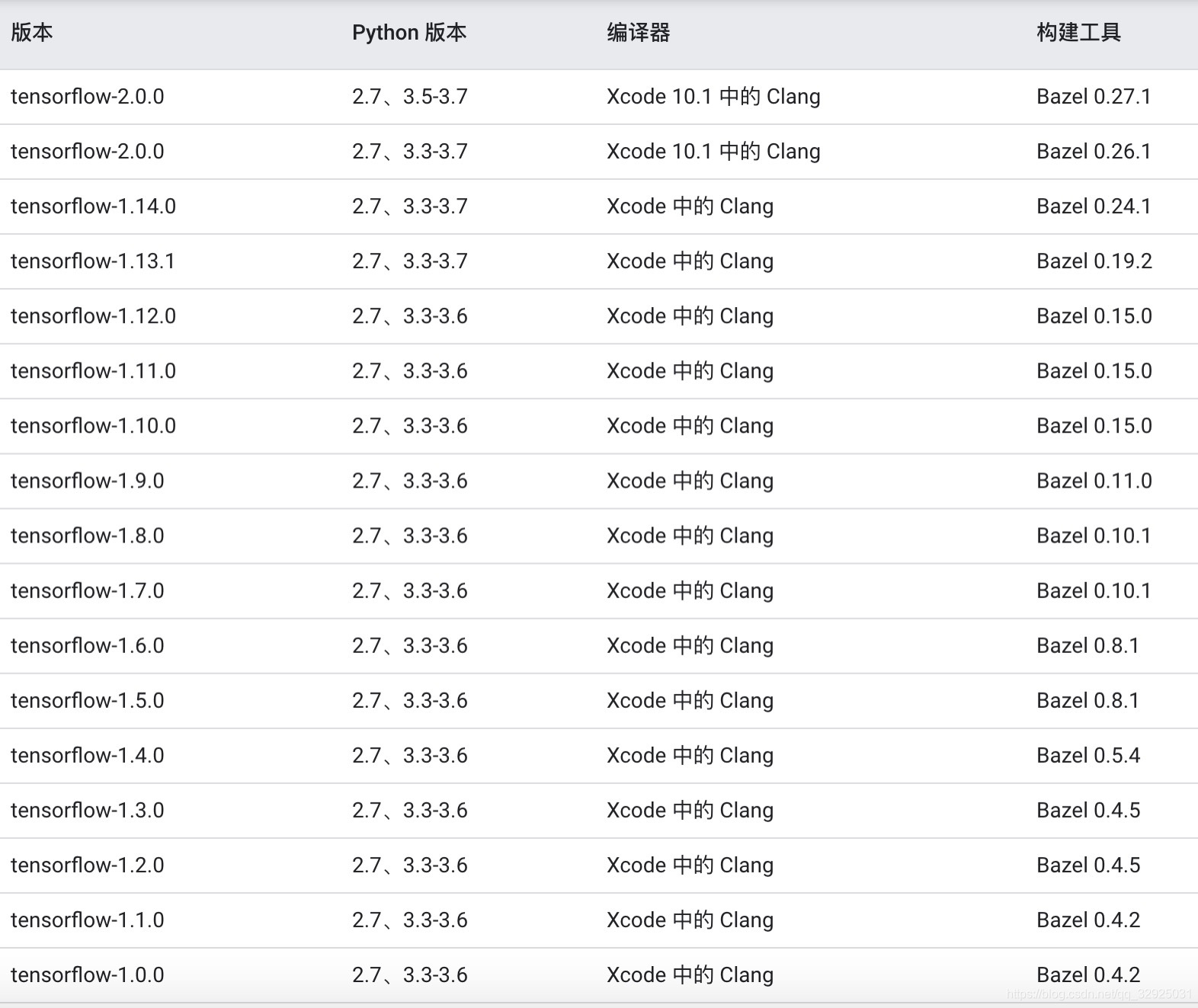
配置window10,python3.7,tensorflow1.14.0,运行第一节多臂赌博机代码时遇到AttributeError: ‘EntryPoints‘ object has no attribute ‘get‘。
之前下载的python3.8,在对应Pytorch和Tensorflow时没太在意版本,在运行一些代码时,提示Pytorch和Tensorflow版本过高,直接降下来,有时候又和Python3.8不兼容,所以又在虚拟环境搞一个Pyhon3.7,下载一些低版本的Pytorch和Tensorflow。
意思是缺rendering文件,这个问题主要是由于Gym版本的变化,在某个版本中删除了classic_control包中的rendering文件,所以需要手动把这个文件给加上。