




- @weixin_46415275
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
为什么要搭建自己的个人博客呢?我想大多数人都是为了记录笔记,督促自己学习。我在尝试了 OneNote, 以及印象笔记之后,感觉虽然这两个笔记软件功能都很齐全,也支持桌面和移动端同步,但总感觉缺少点什么,并没有促进自己学习记录,百度/google过一次的问题到下次任然需要继续百度一次。因此决定搭建属于自己的个人博客。好吧,我承认一部分原因是:拜托,搭建自己的个人博客超酷的好吧!虽然自己的编程基础拉到
one-hot encoding (独热编码)在 loss 的计算时,Pytorch 有些 loss 函数需要 网络的 ouput 与 label 的 shape 相同,因此需要对 label 进行 one-hot encoding分割中的独热编码示例python 代码实现Python 实现的思路参考 https://discuss.pytorch.org/t/efficient-way-to-o
数据增强深度学习模型的*鲁棒性(robustness)和泛化性(generality)*受到训练数据的多样性和数据量所影响。数据增强(data augmentation)是机器学习和深度学习中经常采用的一个方法,其目的是扩大训练样本的数量。语义分割是计算机一个重要的下流任务,语义分割的数据增强通常需要对图像及其对应的标签做相同的增强处理本文总结了3种常用的增强方式:(1)旋转,(2)翻转,(3)裁
one-hot encoding (独热编码)在 loss 的计算时,Pytorch 有些 loss 函数需要 网络的 ouput 与 label 的 shape 相同,因此需要对 label 进行 one-hot encoding分割中的独热编码示例python 代码实现Python 实现的思路参考 https://discuss.pytorch.org/t/efficient-way-to-o
one-hot encoding (独热编码)在 loss 的计算时,Pytorch 有些 loss 函数需要 网络的 ouput 与 label 的 shape 相同,因此需要对 label 进行 one-hot encoding分割中的独热编码示例python 代码实现Python 实现的思路参考 https://discuss.pytorch.org/t/efficient-way-to-o
游程编码理解(RLE,run-length encoding)游程编码又称行程长度编码,是一种简单的非破坏性资料压缩方法。RLE适用于颜色较单一的图片,如果图片颜色复杂则很难起到压缩的作用。改编码方式在深度学习语义分割的标签制作中有应用。将图片转化为RLE格式(compression)上面的二值图可以表示为一个像素矩阵:000110000011000000111100011110000111111
one-hot encoding (独热编码)在 loss 的计算时,Pytorch 有些 loss 函数需要 网络的 ouput 与 label 的 shape 相同,因此需要对 label 进行 one-hot encoding分割中的独热编码示例python 代码实现Python 实现的思路参考 https://discuss.pytorch.org/t/efficient-way-to-o
数据增强深度学习模型的*鲁棒性(robustness)和泛化性(generality)*受到训练数据的多样性和数据量所影响。数据增强(data augmentation)是机器学习和深度学习中经常采用的一个方法,其目的是扩大训练样本的数量。语义分割是计算机一个重要的下流任务,语义分割的数据增强通常需要对图像及其对应的标签做相同的增强处理本文总结了3种常用的增强方式:(1)旋转,(2)翻转,(3)裁
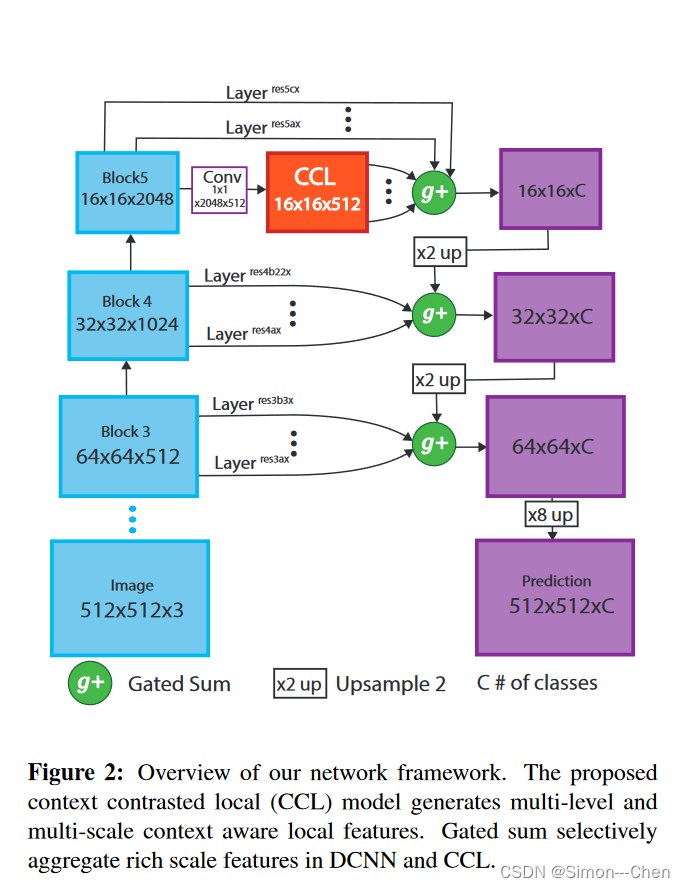
本文提出了 Context contrasted local features 以更好地利用上下文信息同时从背景信息中关注局部信息;进一步地,使用了一个 context contrasted based local(CCL) 模型获得多尺度和多等级的 context contrasted local features
数据增强深度学习模型的*鲁棒性(robustness)和泛化性(generality)*受到训练数据的多样性和数据量所影响。数据增强(data augmentation)是机器学习和深度学习中经常采用的一个方法,其目的是扩大训练样本的数量。语义分割是计算机一个重要的下流任务,语义分割的数据增强通常需要对图像及其对应的标签做相同的增强处理本文总结了3种常用的增强方式:(1)旋转,(2)翻转,(3)裁