
写文章




- @weixin_44599230
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
hmm中文分词原理简单介绍与python实现
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录马尔可夫模型隐马尔可夫模型1.引入库2.读入数据总结马尔可夫模型一个长度为N的序列N1,N2,N3,...NNN_{1}, N_{2}, N_{3},...N_{N}N1,N2,N3,...NN,每个位置有k种可能的状态Sj(1<=j<=k)S_{j}(1<=j<=k)Sj(1<=j&l
基于pytorch自己训练一个小型的chatgpt闲聊程序
OpenAI公式在2018年提出了一种生成式预训练(Generative Pre-Trainging,GPT)模型用来提升自然语言理解任务的效果,正式将自然语言处理带入预训练时代,预训练时代意味着利用更大规模的文本数据一级更深层次的神经网络模型学习更丰富的文本语义表示。同时,GPT的出现提出了“”生成式预训练+判别式任务精调的自然语言处理新范式,使得自然语言处理模型的搭建变得不在复杂。生成式预训练
diffusion模型原理介绍以及pytorch代码实现
扩散模型 diffusion简单介绍

文本识别CRNN模型介绍以及pytorch代码实现
文本识别CRNN pytorch
GPT模型介绍并且使用pytorch实现一个小型GPT中文闲聊系统
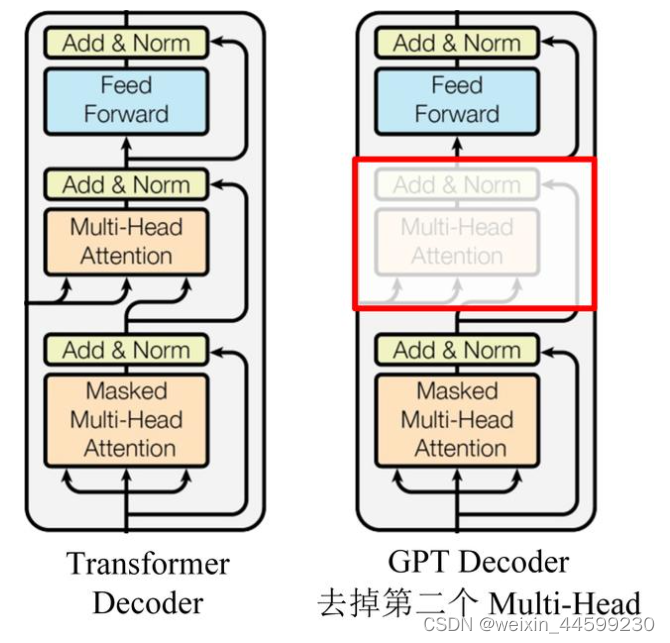
文章目录GPT模型介绍无监督训练方式模型结构微调下游任务输入形式GPT-2GPT-3pytorch实现一个小型GPT中文闲聊系统GPT模型介绍GPT与BERT一样也是一种预训练模型,与BERT不同的是,GPT使用的是Transformer的Decoder结构。在大量没有标号的数据上训练出一个预训练模型,然后少量有标号的数据上微调训练一个中下游任务的模型。在微调的时候构造与任务相关的输入,就可以很少

到底了