




- @weixin_44307002
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
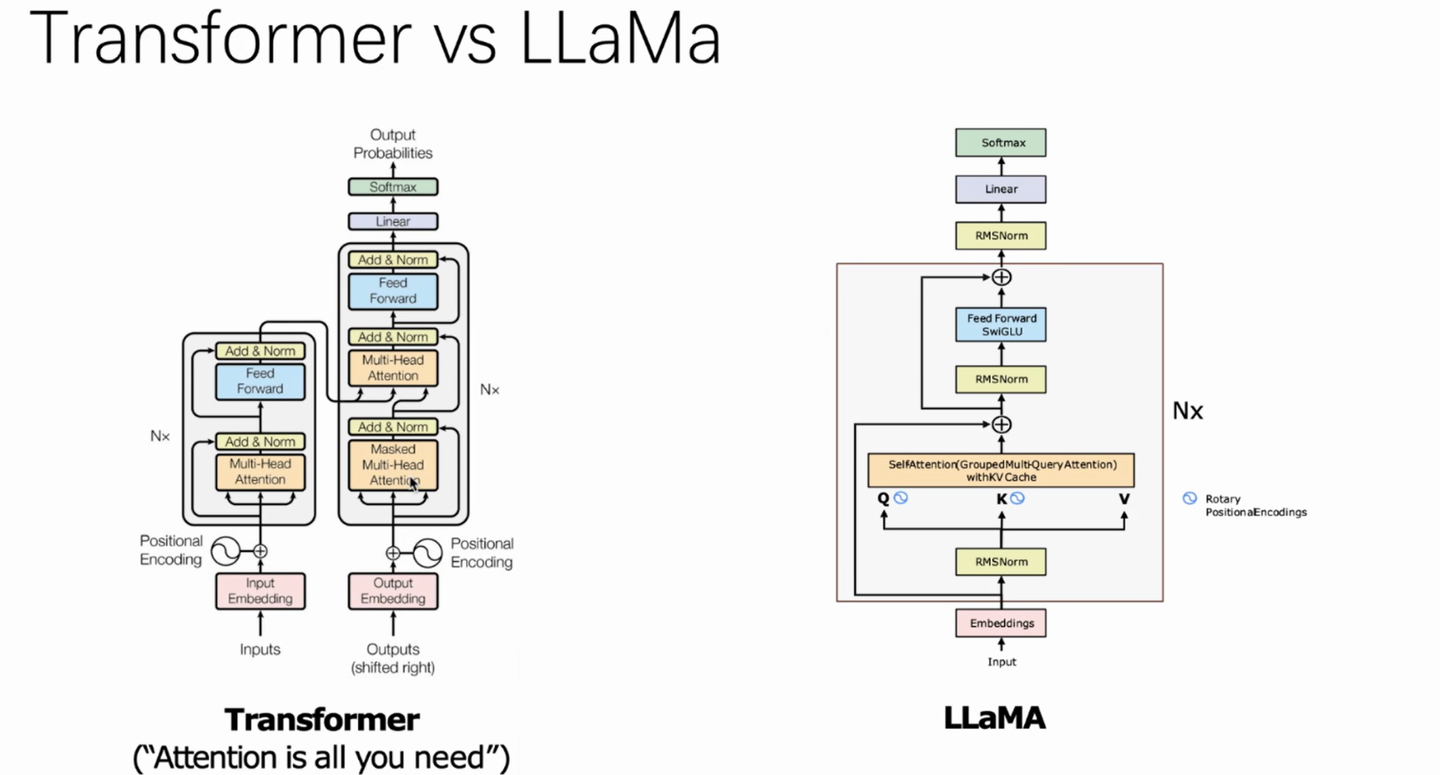
transformer主要分为解码器和编码器两部分。相较之下,LLaMA仅使用了Transformer的解码器部分你,采用了一个仅解码器的结构。在结构上,与transformer模型相比,llama2的主要变化是将其中的layerNorm替换为了均方根标准化(RMSNorm),多头注意力换成了分组查询注意力(GQA,在llama中则是多查询注意力MQA),并将位置编码替换为了旋转编码(RoPE)。
深度学习是机器学习的一个分支。传统机器学习的特征提取主要依赖人工,针对特定简单任务时人工提取特征会简单有效,但是并不能通用。深度学习的特征提取并不依靠人工,而是机器自动提取的。Transformer是一种基于自注意力机制的神经网络模型。Transformer模型由编码器和解码器两部分组成,编码器用于将输入序列编码成一个高维向量表示,解码器用于将这个向量表示解码成目标序列。Transformer最核
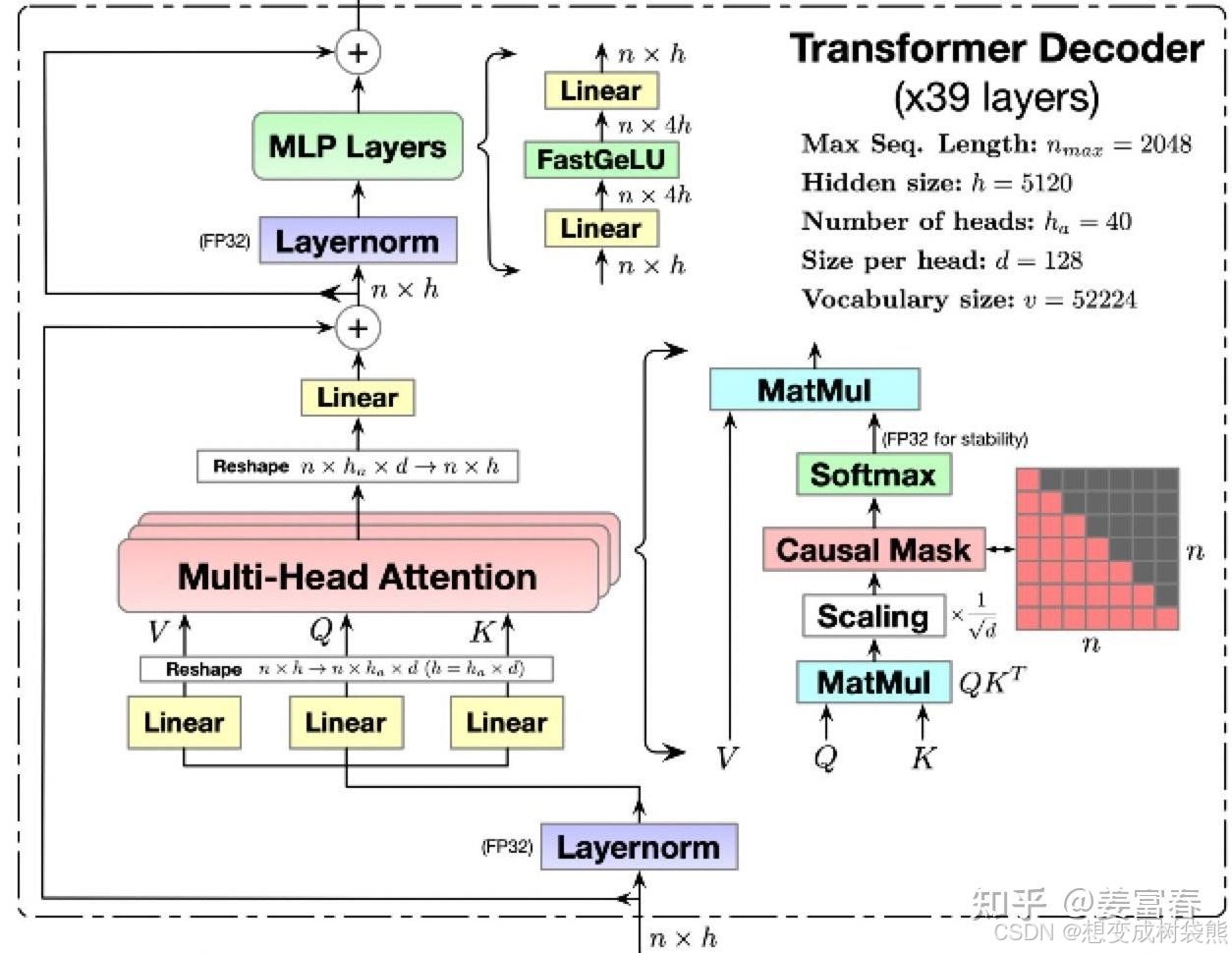
在LLM生成过程中,是一个基于前向序列token预测下一个token的过程,序列中的token(无论是prefill阶段,还是decode阶段)只与它前面的token交互来计算attention。矩阵计算上通过一个下三角的causal attention mask来实现token交互只感知前向序列。
这个问题真的困扰我很久了!!!查了很多资料但是都没有说的很明白,今天问了师兄终于搞明白了,我太难了TAT。

在LLM生成过程中,是一个基于前向序列token预测下一个token的过程,序列中的token(无论是prefill阶段,还是decode阶段)只与它前面的token交互来计算attention。矩阵计算上通过一个下三角的causal attention mask来实现token交互只感知前向序列。
正则化是机器学习中用于防止过拟合并提高模型泛化能力的技术。当模型过拟合时,它已经很好地学习了训练数据,甚至是训练数据中的噪声,所以可能无法在新的、未见过的数据上表现良好。比如:其中,x1和x2为特征,f为拟合模型,w1和w2为模型权重,b为模型偏执。左图拟合模型公式最高阶次为1,即一条直线,对应欠拟合;中间拟合模型公式最高阶次为2,即一条简单的曲线;右图拟合模型公式最高阶次为4甚至更高,即一条复杂
