




- @weixin_44184852
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Qwen-VL项目是一个多模态AI模型框架,包含训练、推理和评测全流程功能。核心目录包含微调脚本(finetune.py)、OpenAI兼容API服务(openai_api.py)和多模态Web演示(web_demo_mm.py)。系统支持分布式训练(DeepSpeed)、多模态评测(VQA/图像描述等)以及两种服务接口(Web和API)。数据流向清晰:用户请求通过Web/API入口处理,调用预训
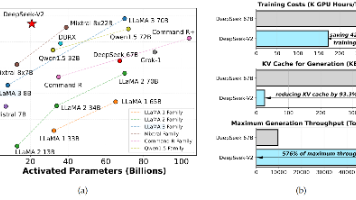
DeepSeek-V2是一款创新的混合专家(MoE)语言模型,通过2360亿参数实现高效推理(仅激活210亿参数/Token)。该模型采用两大核心技术:1)多头潜在注意力(MLA)通过低秩键值压缩减少93.3%的KV缓存;2)DeepSeekMoE架构通过稀疏计算降低42.5%训练成本。在8.1T token多源语料训练后,模型经SFT和强化学习优化,支持128K上下文长度。评测显示,其聊天版本在
Swin Transformer是一种新型的视觉Transformer架构,旨在解决将Transformer从语言领域迁移到视觉领域时面临的挑战,如视觉实体尺度的变化性和图像像素的高分辨率特性。该架构采用基于移位窗口的分层设计,通过将自注意力计算限制在非重叠局部窗口内来提高效率,同时保留跨窗口连接能力。这种设计使得Swin Transformer在图像分类和密集预测任务中表现出色,超越了此前的最佳

模型效率在计算机视觉中变得越来越重要。在本文中,我们系统地研究了用于目标检测的神经网络架构设计选择,并提出了几项关键优化以提高效率。首先,我们提出了一种加权双向特征金字塔网络(BiFPN),它可以轻松快速地进行多尺度特征融合;其次,我们提出了一种复合缩放方法,可以同时统一缩放所有骨干网络、特征网络以及框/类别预测网络的分辨率、深度和宽度。基于这些优化和EfficientNet骨干网络,我们开发了一

摘要——无人机在各个领域得到了广泛的应用,其对安全和隐私的侵犯引起了社会的关注。近年来,已经推出了几种用于无人机的检测和跟踪系统,但它们大多基于射频、雷达和其他介质。我们假设计算机视觉领域已经足够成熟,可以检测和跟踪入侵的无人机。因此,我们提出了一个可见光模式数据集,称为大连理工大学反无人机数据集,简称DUT反无人机。它包含一个总共10,000张图像的检测数据集和一个包含20个视频的跟踪数据集,包

摘要—近年来,地球视觉中的目标检测取得了巨大进展。然而,航空图像中的微小目标检测仍然是一个非常具有挑战性的问题,因为微小目标包含的像素数量较少,并且容易与背景混淆。为了推动航空图像中微小目标检测的研究,我们提出了一个新的数据集,即航空图像中的微小目标检测数据集(AI-TOD)。具体而言,AI-TOD包含28,036张航空图像中的八类共700,621个目标实例。与现有的航空图像目标检测数据集相比,A

目标检测是计算机视觉中一个重要而富有挑战性的问题。尽管过去十年见证了自然场景中目标检测的重大进展,但这种成功在航空图像中进展缓慢,这不仅是因为地球表面上目标实例的规模、方向和形状的巨大变化,还因为航空场景中目标的注释良好的数据集的稀缺。为了推进地球视觉(也称为地球观测和遥感)中的目标检测研究,我们引入了一个用于航空图像中目标检测(DOTA)的大规模数据集。为此,我们从不同的传感器和平台收集了280

遥感图像(RSIs)中的目标检测经常面临几个日益增加的挑战,包括目标尺度的巨大变化和不同范围的背景。现有方法试图通过大核卷积或扩张卷积来扩展主干的空间感受野来解决这些挑战。然而,前者通常会引入相当大的背景噪声,而后者会产生过于稀疏的特征表示。在本文中,我们引入了多核inception网络(PKINet)来应对上述挑战。PKINet采用无膨胀的多尺度卷积核来提取不同尺度的特征并捕获局部上下文。此外,

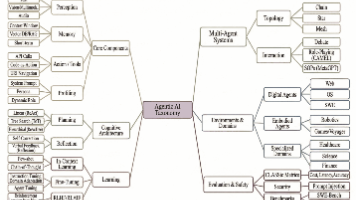
摘要:人工智能正从生成式模型向代理式AI演进,系统能够自主感知、推理与行动。本文系统研究了大型语言模型智能体的架构演进,提出统一分类法将其分解为感知、大脑、规划、行动等六大模块。通过分析从单循环代理到多代理系统的技术发展,揭示了工具使用、协作机制及评估方法的关键特征。研究指出行动幻觉、无限循环等风险,并为构建稳健自主系统提供了技术路线。该框架为理解智能体在软件工程、科学发现等领域的应用奠定了基础。
摘要:针对无人机的实时检测,复杂背景下无人机小目标容易漏检、难以检测的问题。为了在降低内存和计算成本的同时保持较高的检测性能,本文提出了SEB-YOLOv8s检测方法。首先,使用SPD-Conv重建YOLOv8网络结构,以减少计算负担并加快处理速度,同时保留更多小目标的浅层特征。其次,我们设计了AttC2f模块,并用它替换了YOLOv8s主干中的C2f模块,增强了模型获取准确信息的能力,丰富了提取
