




- @weixin_43847596
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
数据库连接池传统的Web服务不断连接、关闭数据库,比较消耗性能。而连接池可以减少数据库的打开与关闭。有了连接池,当服务端的请求传来时,不需要牵扯数据库的建立和关闭。常见连接池:Tomcat - dbcp连接池、dbcp、c3p0数据源:DataSource(javax.sql.DataSource)可用来管理连接池。Tomat-dbcp的配置方法:1.类似 JNDI,在 context.xml 中
一、加载数据集全部数据:Batch 最大化利用向量的优势,提升计算速度(利用CPU GPU的并行计算能力)随机梯度下降:mini-batch 只用一个样本,有较好的随机性首先区分了Epoch(前馈、反馈和更新实现一次就是Epoch) \ Batch-Size(进行一次训练所用的样本数量)\ Iterations(内层迭代进行的次数 sum/Batch-size)shuffle用来打乱数据集中数据的
梯度下降算法对w向梯度的负方向更新,α表示学习率,这样可使得每次都朝着下降最快的方向移动。梯度下降对于非凸函数只能找到局部最优,很难找到全部最优(没有一个点的函数值比它小的点)
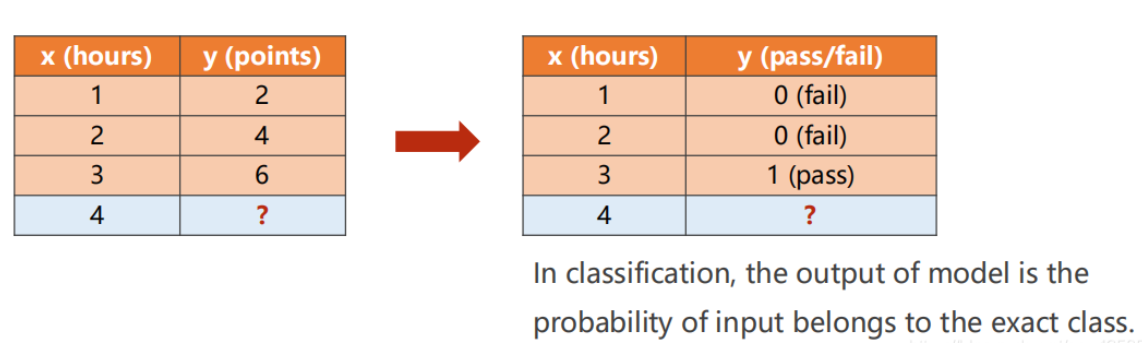
逻辑斯蒂回归(分类问题)一、概念:二、代码:实验结果截图:三、问题:四、可视化:一、概念:对于之前的线性问题转化成分类问题:如果不再预测学习4小时可以得到的成绩,而是判断学习4小时是否可以通过考试。线性回归模型的模型和损失:那么,分类问题如何将结果映射到[0,1]呢?引出了sigmoid函数,将y带入x即可。计算某输入属于某一输出的概率的最大值。σ函数:保证输出值在0~1之间损失函数称为:BCE
深度学习初学者,如何下载常用公开数据集并使用呢?1.前言2.官方文档怎样看3.动手写代码4.如何可视化1.前言刚开始进行深度学习的时候,难免要用到一些公开数据集,现在闲来无事,记录一下如何快速下载一些经典数据集。通过官方文档学习,是一些大牛们挂在嘴边经常推荐的方法,那么我们本篇博客就从官方文档开始学习。因为我是做CV方向的,所以用TorchVision这个库举例。来自官网:This library
我的任务需求是这样的,有几千个对报告单扫描生成的PDF文件,要对这些PDF上有用的部分进行提取。所以,就想到了OCR文字识别。所以我要做的是使用Python将PDF都转为PNG,使用百度开放的PaddleOCR对PNG进行文字识别,提取需要的部分。关于PDF转PNG,见博客()。......
逻辑斯蒂回归(分类问题)一、概念:二、代码:实验结果截图:三、问题:四、可视化:一、概念:对于之前的线性问题转化成分类问题:如果不再预测学习4小时可以得到的成绩,而是判断学习4小时是否可以通过考试。线性回归模型的模型和损失:那么,分类问题如何将结果映射到[0,1]呢?引出了sigmoid函数,将y带入x即可。计算某输入属于某一输出的概率的最大值。σ函数:保证输出值在0~1之间损失函数称为:BCE
一、加载数据集全部数据:Batch 最大化利用向量的优势,提升计算速度(利用CPU GPU的并行计算能力)随机梯度下降:mini-batch 只用一个样本,有较好的随机性首先区分了Epoch(前馈、反馈和更新实现一次就是Epoch) \ Batch-Size(进行一次训练所用的样本数量)\ Iterations(内层迭代进行的次数 sum/Batch-size)shuffle用来打乱数据集中数据的
梯度下降算法对w向梯度的负方向更新,α表示学习率,这样可使得每次都朝着下降最快的方向移动。梯度下降对于非凸函数只能找到局部最优,很难找到全部最优(没有一个点的函数值比它小的点)
文章目录Back Propagation知识代码:Back Propagation知识w.item(): 可以直接将梯度变成标量w.data: 取数值进行计算 不会构建计算图w.zero_(): 释放数值 对其清零计算过程可以看作在图上进行梯度传播训练的目的:使Loss取更新。计算Loss对w的导数,对w进行更新。因为目标不是y_pred取最小,而是使损失Loss取最小。如何将复杂的网络看成图,在