




- @weixin_43332715
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
创建个人github.io主页//吐槽:很多国内教程已经失效了
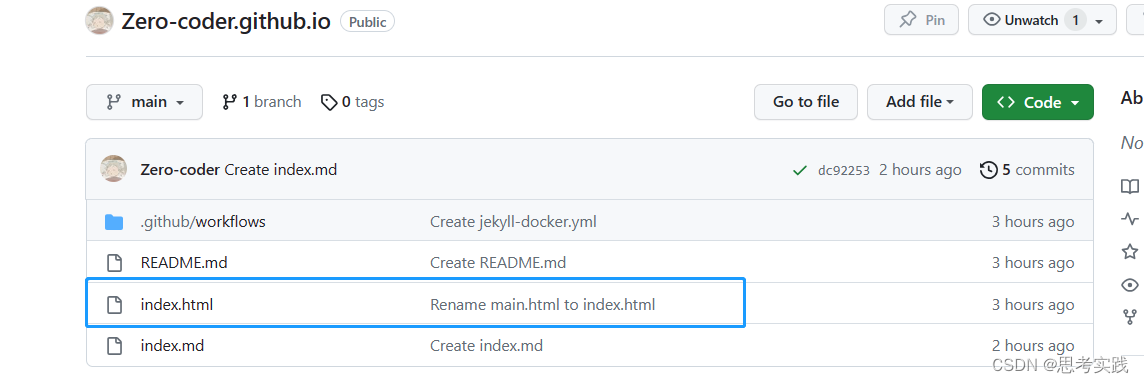
直接去插件市场下载一个SQLite Viewer就行了
突然心血来潮,想到卡尔曼滤波器是否能和深度学习结合。于是从谷歌学术上搜了一下,发现现在这方面的工作还没有太多结合。Top 期刊 TNNLS 2021 有一篇最新工作。ICLR 2020 出现一篇 Kalman Filter Is All You Need 的文章,但目前从开源的审稿意见来看,凶多吉少。其余的,大部分出自于一个 Guy Revach 学者(团队)。...
1.比如我用conda activate pytorch进入到了环境然后想查看当下环境的python路径,输入 which python就可以了。2.想查看conda下所有虚拟环境安装的python的路径,输入 conda env list就可以了。(pytorch) jiangmaowei@localhost / % which python/Users/jiangmaowei/opt/anac
把图像 embedding 线性或非线性投影到语言 embedding 空间,让语言模型把图像当成前缀上下文一起处理。这样模型结构简单,推理快,还能发挥 LLM 强大的语言理解与推理能力。如果你想,我也可以画张图解释它和 Q-former 或 cross-attention 的对比流程图~4o。
2.下载Unity Hub(不要单独下载一个Unity文件,我一开始就单独下一个,也不知道咋用,Unity Hub里面可以直接下载需要的Unity 版本)Unity Hub安装编辑器出现validation failed错误,就是路径问题,很好解决。重新安装protobuf,选择版本为3.20.* 便可解决该问题。系统环境是Windows。

突然心血来潮,想到卡尔曼滤波器是否能和深度学习结合。于是从谷歌学术上搜了一下,发现现在这方面的工作还没有太多结合。Top 期刊 TNNLS 2021 有一篇最新工作。ICLR 2020 出现一篇 Kalman Filter Is All You Need 的文章,但目前从开源的审稿意见来看,凶多吉少。其余的,大部分出自于一个 Guy Revach 学者(团队)。...
深度学习的兴起:而目前深度学习之所以热,就是现在出现了新技术来解决深层神经网络的难训练问题。这主要归功于以下三个方面:(1) 计算力的提高:大家都知道的摩尔定律,以及GPU,FPGA,ASIC等在深度学习的应用;(2) 大数据时代的到来:我们有了更多的训练样本;(3) 算法的创新:启发式的参数初始化,新的激活函数、优化方法以及网络架构等;深度学习的兴起与这三个方面紧密相关,其实更重要的是前两个方面