- @weixin_43301333
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
42, 3407, 114514别问为什么【🐶】
最近又回到了一个很质朴的问题,关于DL里面各种分类器,线性层的称谓:Linear, Dense, MLP, FC之间的区别。

在机器上直接用pip安装pytorch-gpu版本,很有可能出现torch的cuda toolkit和设备不兼容的问题。即,显示为trueQ: 如何知道自己安装的gpu版pytorch能否正常使用?
日期:2021.12.2最新的对应关系请参见官网:
偶然看到的,感觉有几点还是比较中肯的用distributionDataparallel代替Dataparallel;直接在GPU上create tensor,而不是用.cuda();在使用Dataloader的时候设置num_workers和pin_memory,多线程加速和避免额外GPU缓存使用16bit精度(pytorch1.6之前需要有Nvidia apex支持)原文:7-tips-for-
都是配置、中间缓存文件,如果需要把代码push到github和别人共享的话,建议都删除/加入.gitignore。其中,.idea是pycharm的缓存文件,.vscode是vscode的配置文件,而、__pycache__则是python编译生成的中间文件(主要用来加快二次运行)。......
如torch.select等;或者输入的input_ids超出了模型embedding的词表范围。,比方说padding tokens、ending tokens。在某些情况下会比较实用。这种类型的报错,绝大多数情况下,都是因为tensor index的错误。,上述操作的一个好处就是可以把超出词表范围的那些ids。
查询资料之后,没有找到出现这个问题的原因。重新初始化仓库的,也有说是网络问题。但笔者尝试之后没有效果。重新addremoteurl就行。
在机器上直接用pip安装pytorch-gpu版本,很有可能出现torch的cuda toolkit和设备不兼容的问题。即,显示为trueQ: 如何知道自己安装的gpu版pytorch能否正常使用?
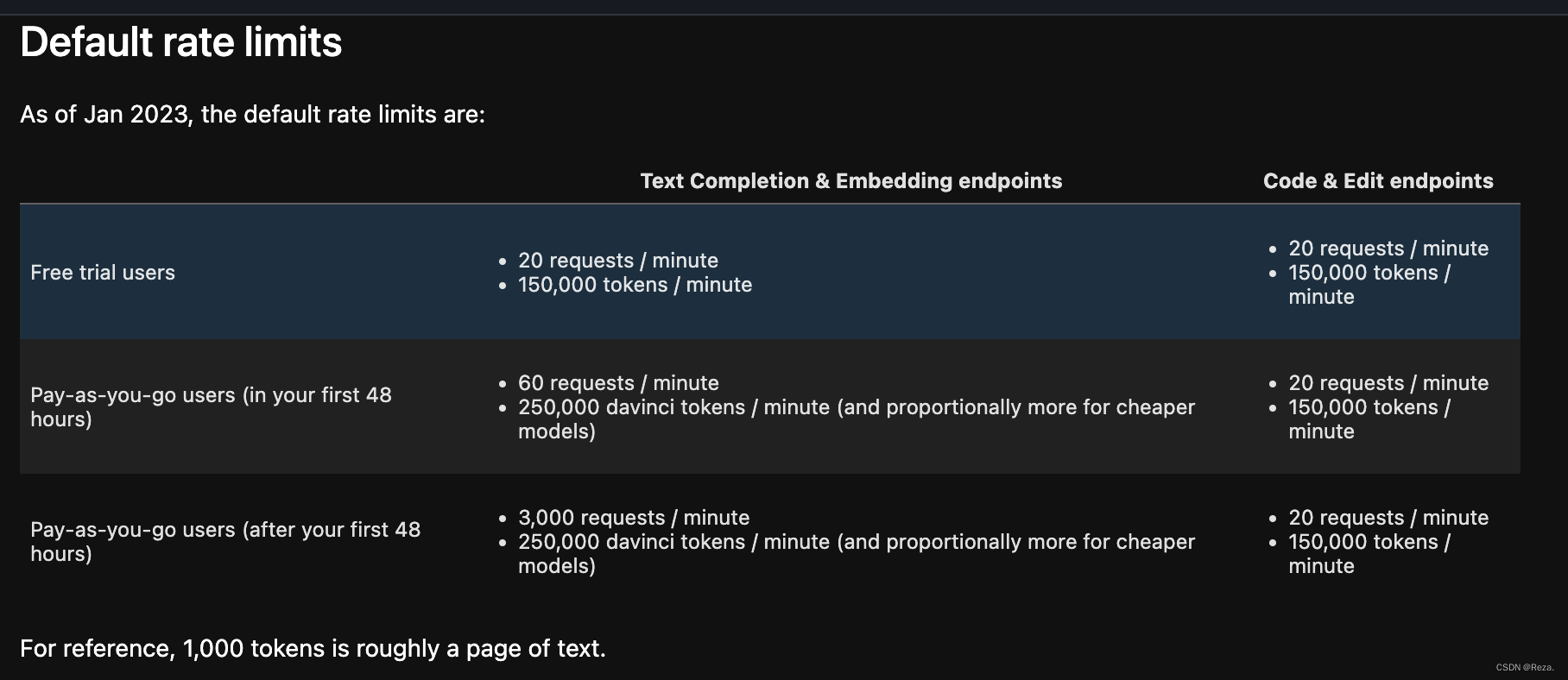
原因就是调用API的频率太过于频繁。例如,free trial的用户,每分钟限制的request的上限是20次,15万tokens。超过这部分,访问就会受拒。