
写文章




- @weixin_43153588
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
【昇思25天学习打卡营第1天】
上述内容即为本人的第一次打卡体验,后续会持续的跟进学习并和大家一起沟通讨论,并不断发掘该平台的新功能和新体验!

【Flink SQL API体验数据湖格式之paimon】
随着大数据技术的普及,数据仓库的部署方式也在发生着改变,之前在部署数据仓库项目时,首先想到的是选择国外哪家公司的产品,比如:数据存储会从Oracle、SqlServer中或者Mysql中选择,ETL工具会从Informatica、DataStage或者Kettle中选择,BI报表工具会从IBM cognos、Sap Bo或者帆软中选择,基本上使用的产品组合都类似,但随着数据量的激增,之前的部署方式

数据同步利器之seatunnel篇
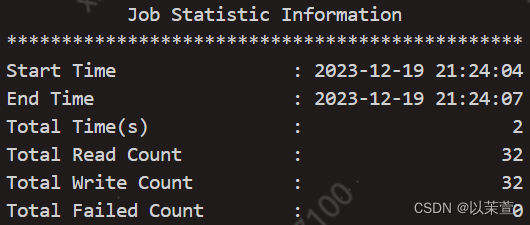
至此,seatunnel集群就已经部署完成了,看过seatunel官网介绍过跟datax的数据同步效率对比,大概提升了20%-40%,本人经过实测,速度确实更快了,而且配置比datax的json格式更为简单,seatunnel还提供了transform中间转换功能,当然了由于seatunel是后起之秀,还有不少需要完善改进的空间,但发展前景还是挺好的,希望有越来越多优秀的工具能够出现,由于篇幅有限
调度工具之dolphinscheduler篇
随着开发程序的增多,任务调度以及任务之间的依赖关系管理就成为一个比较头疼的问题,随时少量的任务可以用linux系统自带的crontab加以定时进行,但缺点也很明细,不够直观,以及修改起来比较麻烦,容易出错,这时候就需要调度工具来帮忙,不知道大家都接触过哪些调度工具,我这边接触过airflow、oozie、 Kyligence,但今天我想推荐的调度工具是dolphinscheduler,下面就从安装
到底了