




- @weixin_43013480
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。但传统的RLHF比较复杂,且还需要奖励模型,故DPO方法被提出,其将现有方法使用的基于强化学习的目标转换为可以通过简单的二元交叉熵损失直接优化的
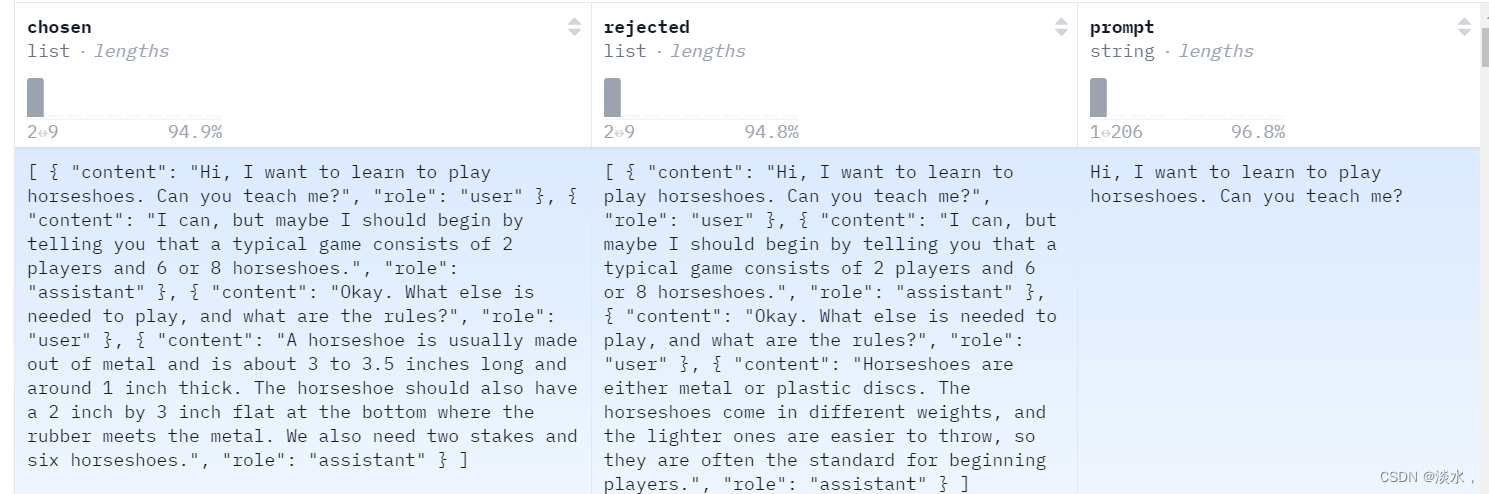
有了transfomers框架后我们的微调工作都变得简单了起来,我们在自己进行一些模型的微调时主要的操作就是构建自己的数据集及数据格式,不同模型的在训练时都使用了不同的template。因此,我从官方参考或实现中收集了几种主流模型的官方模板,以供大家自己进行微调时参考。如果觉得有帮助欢迎大家star或者提交issue 及 pr。
但是经常会报连接错误等问题,所以我们可以去huggingface官网下载好数据集,然后直接用数据集路径替换。的数据,手动将data文件夹下的文件全部下载,然后保存在本地一个文件夹中,替换上述的。
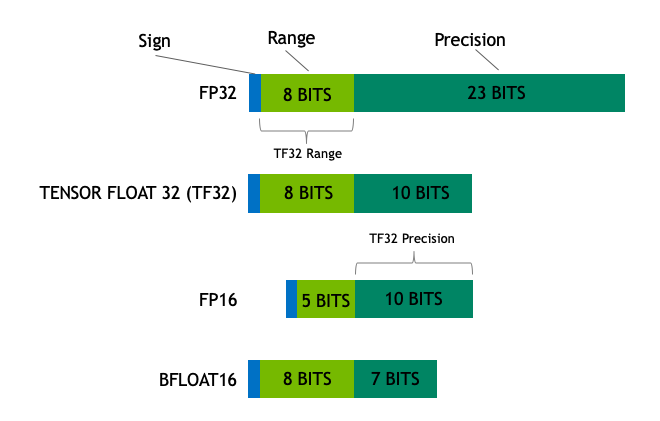
在机器学习术语中,FP32 称为全精度 (4 字节),而 BF16 和 FP16 称为半精度 (2 字节)。除此以外,还有 Int8 (INT8) 数据类型,它是一个 8 位的整型数据表示,可以存储282^828个不同的值 (对于有符号整数,区间为 [-128, 127],而对于无符号整数,区间为 [0, 255])。
知识蒸馏简单讲即使用大规模参数的模型对小规模参数模型进行蒸馏,且不是简单的只使用答案,是需要两个模型的log prob进行交互的,故两个模型的vocab size必须是一样的。参考论文中分类了多个不同的版本,on-policy及off-policy。
记录一下查看机器是否可用bf16精度,
在机器学习术语中,FP32 称为全精度 (4 字节),而 BF16 和 FP16 称为半精度 (2 字节)。除此以外,还有 Int8 (INT8) 数据类型,它是一个 8 位的整型数据表示,可以存储282^828个不同的值 (对于有符号整数,区间为 [-128, 127],而对于无符号整数,区间为 [0, 255])。
模型推理的时候出现这个问题搜了搜本以为是bfloat精度问题,但改了之后依然没用。nvidia-smi的cuda version是12.2。nvcc -V 的cuda version是12.1。最终将torch版本回退为2.1.0后成功解决问题。torch版本为2.1.2。

一般正常lora训练完模型后我们只保存其lora参数,然后与base模型进行合并。记录一下训练完保存lora后,继续再对lora训练的步骤。即为之前保存的lora模型路径。
碰到上面的报错也查了很多资料,但是都没有很好的解决,主要问题还是torch和deepspeed版本的问题。使用huggingface和deepspeed时遇到上述问题。
