- @weixin_42223090
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
类别不平衡(Class Imbalance):数据集中各类别样本数量差距悬殊。常见于欺诈检测、医疗诊断、异常检测等场景。准确率(Accuracy)失效——多数类占 99%,全猜多数类也有 99% 准确率模型偏向多数类,少数类(正类)几乎学不到信号交叉熵损失被多数类主导,梯度更新忽略少数类。

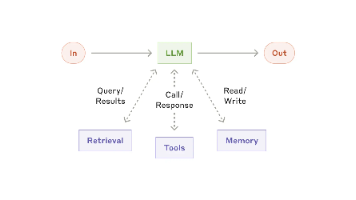
AI 会话上下文管理机制解析 大模型产品处理长对话时并非简单存储全部历史记录,而是采用动态上下文管理策略。核心机制包括: 模型本身是无状态的,每次请求需重新构造上下文输入 上下文窗口有限,需平衡系统指令、工具结果、历史对话等内容 短对话通常保留完整上下文,长对话则采用多种优化策略: 裁剪早期内容 摘要压缩关键信息 检索相关历史片段 挂载长期记忆 要求开启新会话 主流产品实现差异: ChatGPT:

本文深入探讨了大语言模型(LLM)发展中的关键技术——上下文工程(Context Engineering)。文章指出,AI Agent作为语言模型与现实世界的桥梁,需要解决两大核心挑战:模型缺乏长期记忆和上下文窗口受限问题。通过四种核心操作(上下文压缩、记忆系统、子代理机制和源头控制),AI Agent能够智能管理输入信息,防止上下文爆炸。文章特别提出"Agentic Context E

LangChain总体架构分为5层:模型层(L1)对接各类LLM模型;提示层(L2)处理Prompt模板化;运行层(L3)通过Runnable实现流程编排;智能层(L4)提供Agent/Tools实现工具调用;记忆层(L5)管理长期记忆和上下文。核心模块包括ChatPromptTemplate(L2)、RunnableSequence(L3)、Tool Calling Agent(L4)等,支持从

AI 会话上下文管理机制解析 大模型产品处理长对话时并非简单存储全部历史记录,而是采用动态上下文管理策略。核心机制包括: 模型本身是无状态的,每次请求需重新构造上下文输入 上下文窗口有限,需平衡系统指令、工具结果、历史对话等内容 短对话通常保留完整上下文,长对话则采用多种优化策略: 裁剪早期内容 摘要压缩关键信息 检索相关历史片段 挂载长期记忆 要求开启新会话 主流产品实现差异: ChatGPT:
AI 会话上下文管理机制解析 大模型产品处理长对话时并非简单存储全部历史记录,而是采用动态上下文管理策略。核心机制包括: 模型本身是无状态的,每次请求需重新构造上下文输入 上下文窗口有限,需平衡系统指令、工具结果、历史对话等内容 短对话通常保留完整上下文,长对话则采用多种优化策略: 裁剪早期内容 摘要压缩关键信息 检索相关历史片段 挂载长期记忆 要求开启新会话 主流产品实现差异: ChatGPT:
AI 会话上下文管理机制解析 大模型产品处理长对话时并非简单存储全部历史记录,而是采用动态上下文管理策略。核心机制包括: 模型本身是无状态的,每次请求需重新构造上下文输入 上下文窗口有限,需平衡系统指令、工具结果、历史对话等内容 短对话通常保留完整上下文,长对话则采用多种优化策略: 裁剪早期内容 摘要压缩关键信息 检索相关历史片段 挂载长期记忆 要求开启新会话 主流产品实现差异: ChatGPT:
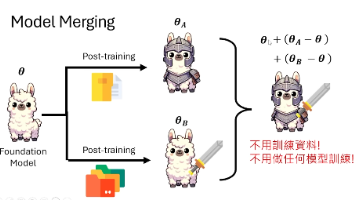
开源大模型微调面临"灾难性遗忘"问题,李宏毅教授提出三大前沿解决方案:1)模型编辑(Model Editing),通过精准手术式修改特定参数,实现知识更新和隐私遗忘;2)模型融合(Model Merging),无需训练直接合并多个模型参数,快速获得多功能模型但存在逻辑冲突风险;3)测试时训练(Test-Time Training),在推理时动态更新参数,采用快慢更新机制和自动重置保障稳定性。这些方
CLAUDE.md是用于规范Claude行为的核心文档,应聚焦于项目关键信息:构建测试流程、架构边界、编码规范和安全限制。避免放入背景介绍或可推断的内容。建议采用模块化结构,包含构建指令、架构约束、编码规范、禁止事项和验证要求。通过让Claude自行更新文档来持续优化,并定期review过时条目。项目实践中可配合环境检查工具和按文件类型触发的hooks,建立包含全局约束、路径约束和工作流的多层级规

文章摘要:本文探讨了构建高效LLM智能体的关键原则与实践经验。研究表明,简单可组合的模式比复杂框架更有效。文章区分了工作流(预定义流程)与智能体(自主决策系统)的适用场景,建议仅在需要高度灵活性时采用智能体。介绍了多种工作流模式(提示链、任务路由、并行处理等)和智能体的核心架构,强调工具设计清晰性和模型友好性的重要性。最佳实践包括优先使用简单方案、理解底层机制、设置防护措施等,并以代码智能体为例展